VoicePing 如何基于定制化 Whisper V2 模型,在单条 WebSocket 流中实现自动、低延迟的语言切换——双语模式的完整设计历程。
VoicePing 目前已在生产环境的会议中运行双语转录,支持日语、英语、普通话、粤语、韩语和越南语在句中自由切换。用户的期望很简单:无论语码转换多么频繁,语音识别和翻译都应无缝衔接。本文介绍我们如何设计了双语模式(Bilingual Mode)——基于定制化 Whisper V2 模型,在单条 WebSocket 流中实现自动、低延迟的语言切换。
目录
- 1. 单语基线
- 2. 为什么"双语模式"是刚需
- 3. 初始方案:外部语言检测(及其失败原因)
- 4. 突破:让 Whisper 自己告诉我们语言
- 5. 稳定语码转换边界
- 6. 通用填充解决短音频不稳定问题
- 7. 运营约束:GPU、MPS 与并发
- 8. 总结
- 参考文献
1. 单语基线
我们从传统的实时 ASR 架构出发:
- 客户端流式传输 16 kHz PCM 音频。
- VAD 将音频切分为滑动窗口(可配置重叠,约 X 秒)。
- Whisper V2 派生模型以固定的
language=ja进行解码。 - 后处理阶段对部分假设去重、文本修正,并通过 WebSocket 流式推送更新。
这一滑动窗口+拼接的流水线借鉴了 “Streaming Whisper: Enhanced Streaming Speech Recognition”(https://arxiv.org/abs/2307.14743)中描述的 Streaming Whisper 方法,为我们在叠加双语能力之前提供了稳定的基线。
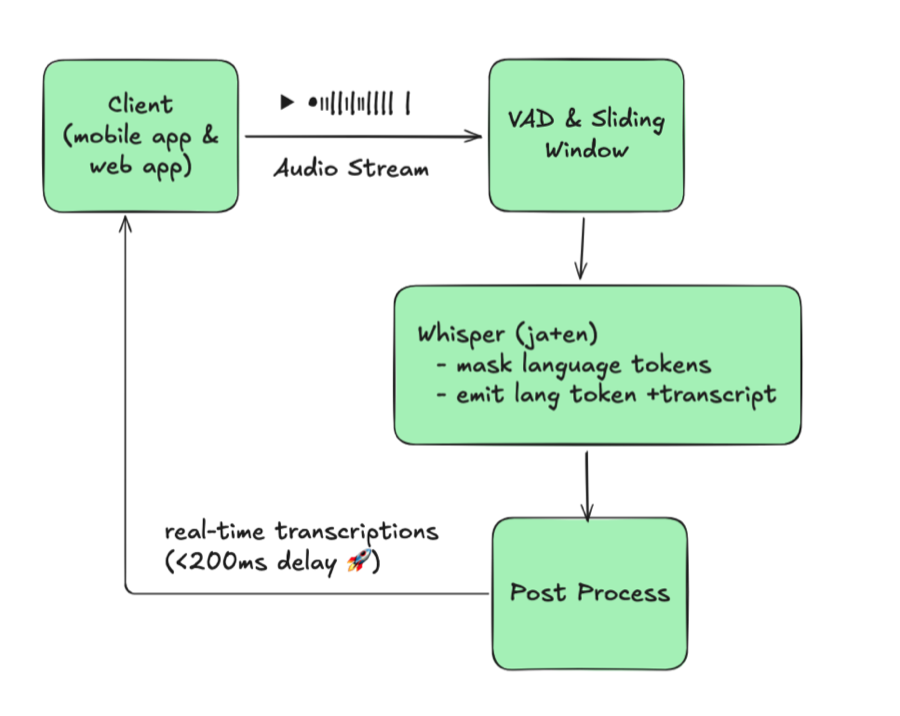
图 1:单语基线(单一固定语言)
这一架构假定会话中语言永远不会改变。缓冲区、短语偏置词典和消息会话均以该单一语言为键。一旦出现语码转换,系统便告崩溃:当客户在通话中从日语切换到英语时,服务器仍锁定在 ja,Whisper 输出的要么是乱码,要么是空文本。修复的方法是人工断开 WebSocket 连接、重新配置会话语言再重连——每次说话人切换语言都要重复一遍。这种手动循环和强制重连成为了整个架构最大的瓶颈。
2. 为什么"双语模式"是刚需
在真实会议中,语言切换不是假设中的边界情况。日语使用者做报告,说英语的同事插话,说中文的利益相关方追问。在活动现场,主持人用日语主持,而与会者用英语提问。我们原来的单语言系统打断了对话流:每次切换都要有人停下来、重新配置会话再重连,拖长会议时间,推高协调成本。
团队反复提出一个简单的需求:“只要自动检测我们设定的两种语言中正在使用的那个,不用我们做任何操作就能持续转录(和翻译)。“这个看似简单的要求成为了双语模式的北极星。
“为什么不让 Whisper 保持完全多语言模式?“因为生产环境的用户需要可预测的输出。Whisper 在无约束状态下会输出其支持的 90 多种语言中的任意一种,尤其在实时处理的短且带噪缓冲区中更为明显。测试中我们观察到 JA/EN 会议突然出现西班牙语或俄语的 token——仅仅因为说话人含糊不清或一声咳嗽恰好类似另一种语言的音素。在批处理模式下可以对更长的片段重新运行,但在实时字幕场景中这是不可接受的。用户必须选定两种支持的语言,下游的翻译、UI 和 QA 才能信任该流。
为此,我们将需求转化为具体的技术要求:
- 实时性: 切换开销必须低于 200 毫秒,否则 UI 会卡顿。
- 自动化: 无需人工在会议中手动切换。
- 受限语言对: 每条流只允许配置的两种语言(目前支持 JA/EN/zh-Hans/zh-Hant/KO/VI 组合),确保用户体验可预期。
- 会话稳定性: 误切换比漏检更有害;不能因为每个填充词就在两种语言间来回跳动。
在这些约束条件下,双语模式从"锦上添花"变成了不可或缺的系统能力。
演示:双语模式实际效果
3. 初始方案:外部语言检测(及其失败原因)
我们的第一个原型在 Whisper 前面插入了一个语言识别(LID)模型:
图 2:使用外部 LID 的朴素多语言方案
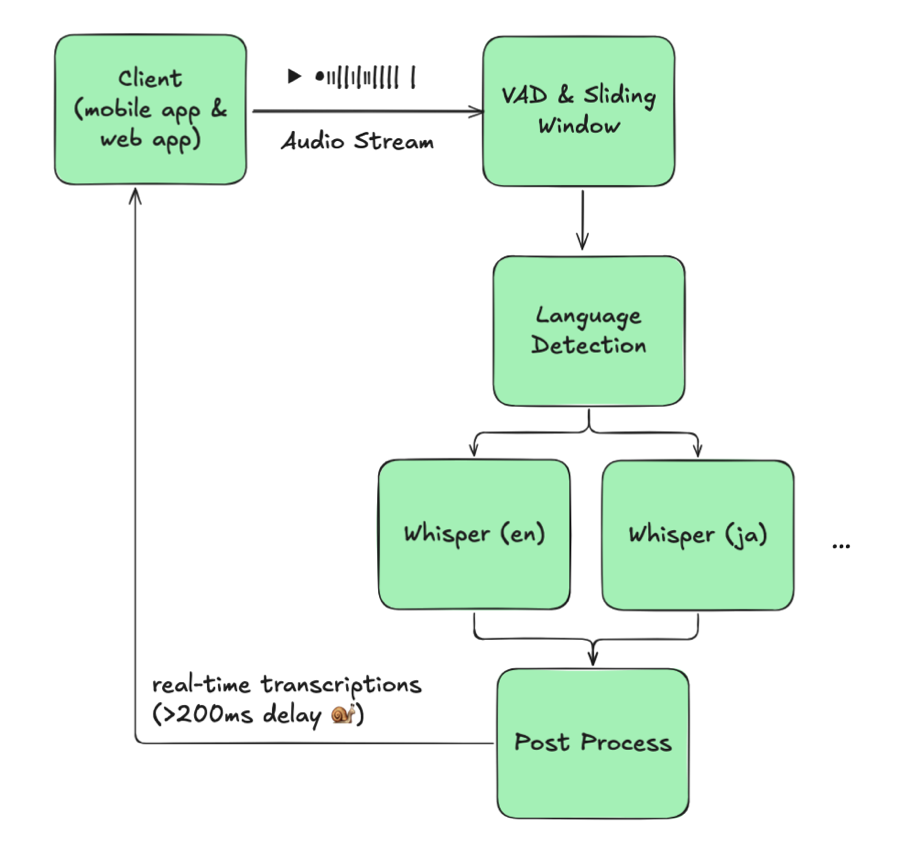
理论很简单:对每个缓冲区检测语言,然后将缓冲区送入对应的单语 Whisper 实例。但现实并非如此。
核心问题是一个无法调和的取舍:降低检测频率会错过切换,提高检测频率则增加约 100 毫秒的延迟并使 GPU 使用量翻倍。准确性和响应速度无法兼得。
即使接受了这个取舍,其他障碍也在叠加。每种语言都需要独立的 Whisper 实例,而使用量并不均匀——JA/EN 占绝对主导,KO 或 VI 的模型几乎处于空闲状态却仍占用 GPU 资源。这一架构根本无法扩展。
在现场测试中发现延迟和准确率均不如单语基线,我们遂放弃了这一方案。
4. 突破:让 Whisper 自己告诉我们语言
前一设计中最薄弱的环节就是外部语言检测器。深入研究 Whisper 内部机制后,我们发现模型已经暴露了所需的信号——只是之前没有正确利用。
4.1 Whisper 原生语言检测
Whisper 在解码器位置 1 处输出语言 token(<|ja|>、<|en|> 等)。默认情况下 Whisper 可以解码数十种语言,但在生产环境中我们此前为了稳定性而强制指定单一语言。通过拦截语言 token 并约束其 logits,我们可以让一个 Whisper 模型保持多语言能力而不牺牲准确性:
- 获取语言 token: 拦截每个 beam 的第一个 token 并解码,将其作为检测到的语言。
- 约束允许的语言: 在位置 1 处对 logits 进行掩码,使得只有配置的语言对(如 JA/EN)才能出现。这样可以防止音频噪声导致的
<|ru|>等随机检测。
| |
施加这些约束后,一次 Whisper 推理即可同时获得转录结果和语言代码。无需额外模型,无需路由,每个音频窗口只需一次前向传播。
4.2 基于 Whisper 原生检测的架构
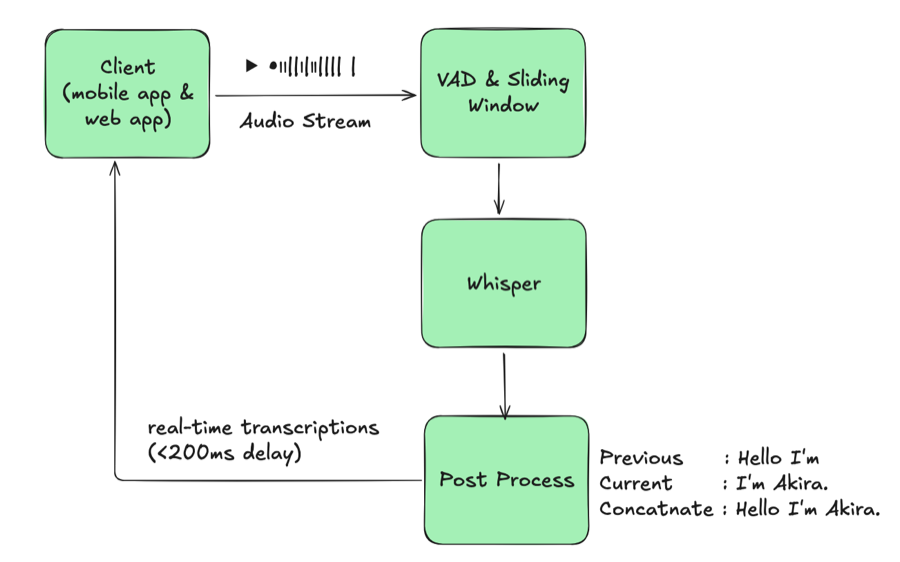
图 3:Whisper 原生语言检测
这一布局看起来与单语基线几乎相同,区别仅在于 Whisper 现在可以在单个会话中处理两种语言。一个模型同时服务两种语言,因此不再需要分别启动 JA/EN/KO 实例或管理路由。与朴素设计相比,我们完全去除了语言识别阶段、消除了按语言的模型冗余,并保持了延迟不变。
5. 稳定语码转换边界
Whisper 现在输出检测到的语言 token,但如果每个 token 都触发切换,转录结果就会不断抖动。在真实对话中,语言切换是渐进的——填充词、犹豫和混合用语会先出现,之后说话人才完全切换语言。如果没有防护机制,输出会变成这样:
| |
识别器每隔几帧就在 JA 和 EN 之间来回跳动,生成的交错文本对读者和下游系统都毫无用处。我们首先引入了滞后机制:只有当连续多帧以超过置信度阈值的概率输出同一语言 token 时,语言切换才被确认。嘈杂的 “I / いあ / I am” 突发在此规则下消失。
短文本处理是最关键的稳定化手段。任何短于 6 个字符的片段都会经过一组宽松的启发式规则,检查日语假名、明显的英文字母、韩语谚文或越南语标记。由于日语和中文都使用汉字,规则被有意设计得较为宽松;如果信号仍然模糊,我们直接回退到上一次确认的语言而非反复切换。
| |
这一简单的优化防止了 “um” 或 “えー” 之类的填充词反复触发会话语言切换。
当系统确认新语言后,会先结束现有的部分转录、启动相应的修正任务、重置 Whisper 的缓冲区,然后以新的会话/消息 ID 重新开始。这一硬边界确保 JA 和 EN 文本在下游翻译和分析中被清晰分离。最后,我们利用 VAD 检测到的静默窗口在自然停顿时刷新缓冲文本,避免在发话中途切断单词。
在这些层层机制的配合下,语码转换呈现为有序的交接而非混乱的碎片,下游翻译和搜索的可靠性也得以保障。
6. 通用填充解决短音频不稳定问题
短缓冲区天生不稳定:Whisper 容易产生幻觉,语言 token 也会随机变化。我们的解决方案看似反常——在将缓冲区送入模型之前,先在前面拼接一段语言中性的填充音频(“Okay, bye bye.")。该填充音频足够长以锚定解码器,同时在语言上保持中性;仅当采集的音频短于可配置的阈值(通常为几秒)时才插入,因此较长的发话不受影响;由于该片段固定不变,beam search 会迅速学会忽略它,而语言 token 则获得了足够的上下文以保持稳定。
| |
通过对短片段进行这样的填充,混合语言和其他短音频段的幻觉问题大幅减少。
7. 运营约束:GPU、MPS 与并发
多路 ASR 只有在规模化运行时才有意义,因此我们部署在消费级 RTX 系列 GPU 上,并借助 CUDA Multi-Process Service 来保持推理流水线的饱和运行。
在典型的 RTX 5090 上,3 个 Whisper V2 工作进程(每个约 2 GB,总计约 6-7 GB)共享显卡的约 30 GB 显存,因此 VRAM 从来不是瓶颈——真正的瓶颈在于 CUDA 核心。
在实际运营中,该 RTX 5090 配置大约可以处理 20-30 路活跃音频流,端到端延迟保持在 100 毫秒左右。添加第四个工作进程虽然在显存上放得下,但延迟会远超实时阈值,因此 CUDA 核心决定了我们的处理能力上限。
8. 总结
目前系统即使在发话中途的语码转换场景下也能实现低于 200 毫秒的延迟,并且由于我们自行运营调优后的 Whisper V2 模型,运维成本可预期且可控。
当前部署针对每条流两种语言进行了优化;扩展到更多语言需要 UI 和策略层面的调整,因此该计划已列入路线图但尚未投入生产。
下一步,我们正在尝试 TensorRT 和 VLLM 风格的推理以进一步降低延迟,同时也在准备关于多语言短语偏置的深度分析。如果您在双语或语码转换频繁的环境中运营,建议直接从 ASR 模型中读取语言 token——您需要的信号可能已经在那里了。
参考文献
Streaming Whisper: Enhanced Streaming Speech Recognition https://arxiv.org/abs/2307.14743
构建双语模式期间参考的主要项目:
SimulStreaming https://github.com/ufal/SimulStreaming
Whisper Streaming https://github.com/ufal/whisper_streaming
WhisperLiveKit https://github.com/QuentinFuxa/WhisperLiveKit
我们最初探索了 WhisperLiveKit + 流式 Sortformer,希望通过说话人分割来减少语言 token 的推理频率。但实际上需要同时运行 Sortformer 和我们自己的语言检测,延迟改善可以忽略不计,而且 Sortformer 的激进策略使其不适合我们的会议场景。
NVIDIA Nemotron Speech ASR(尚未尝试的新一代实时 ASR) https://huggingface.co/blog/nvidia/nemotron-speech-asr-scaling-voice-agents