利用 Voice Activity Detection(VAD)大幅降低云端 STT 服务使用成本的 VoicePing 实现方案详解。
本文详细介绍了 VoicePing 中 Speech to Text 的实现细节,以及开发团队如何最大限度地提高云服务的使用效率。
VoicePing 功能丰富,是远程团队的理想解决方案!我们目前提供为期一年的免费高级订阅,前往 https://voiceping.net/ 即可开始使用!
摘要
从零开始实现 Speech-to-Text 并获得良好的识别精度非常困难。因此,许多企业和开发者选择使用已有的 SaaS 方案,这些方案具有出色的识别效果,并支持多种语言。
根据使用量的不同,这可以是一个低成本的解决方案,因为收费方式是"按量付费"。但这也意味着使用量过多时成本会很高。最终取决于使用方式和使用量。
在这篇文章中,我们将介绍 VoicePing 用来降低会议中用户音频 STT 处理高成本的策略。这一策略之所以可行,是因为在会议中大多数用户只是在听,会议大部分时间并不发言。该策略基于使用 Voice Activity Detection(VAD)库来避免将无声音频流传输到 STT 服务。
我们还将展示在实现这一策略过程中遇到的所有问题及其解决方法。
引言
Speech-to-Text(STT),也称为自动语音识别(ASR),是一项有着广泛应用场景的功能。例如 YouTube 上的自动字幕生成、Siri、Alexa 和 Cortana 等个人虚拟助手,以及许多其他类型的语音应用。
在 VoicePing 中,我们用它来在会议中展示实时转写,使得在转写基础上显示实时翻译成为可能。还可以设置自动将这些转写同步到 Slack 工作区的公共或私有频道,安全保存公司所有工作相关讨论的通信记录。
同步到 Slack 的转写可以利用 Slack 提供的各种功能,例如将会议中分配给你的任务相关消息加书签,将特定讨论事项固定在频道中确保团队不会忘记,或者在会议提前结束、时间不够的情况下在 Slack 线程中继续讨论。
实现
实现一个能够将音频转换为文本的 AI 系统并不容易,需要大量带有转写文本的音频文件来训练和验证 AI 模型,支持的语言越多,工作量就越大。
幸运的是,现有许多可用的服务,而且这些服务的质量每天都在提高,在某些情况下其准确度可以与专业的人工转写人员相媲美。但根据应用的用户数量和收入情况,这些费用可能过高且不可持续。我可以建议两种解决成本问题的方案:
第一种方案是最便宜的选择,使用免费服务。大多数服务都有免费层级,对并发使用量和使用时长有限制。如果免费层级不够用,我不知道有任何不收费的 SaaS 方案,但有一个实验性的 Web Speech API。一些浏览器已经实现了它,如 Google Chrome 和 Microsoft Edge。
这些都很好,但仍有局限性。作为实验性 API,并非所有浏览器都支持,要求用户使用其他浏览器可能会影响应用声誉。另一个限制是 API 本身,目前无法选择使用哪个输入设备,调用 .start() 后总是从默认输入设备开始录音。
这让我们选择了第三方服务,付费使用并寻找降低成本的方法。这就是我们接下来要介绍的第二种方案。
降低成本
使用这类服务时,根据在其服务器上产生的工作负载来付费是合理的。Speech to Text 解决方案的费用大约在每小时 1.00 到 1.50 美元之间。对于每月超过 80,000 小时的超大量使用,可能降至每小时约 0.50 美元。最大的问题是,当你发送音频流或音频文件进行处理时,无论音频中是否有语音,对服务方来说都只是一堆需要处理的字节。他们有入站带域宽成本,即使静音音频的处理成本可能更低,他们仍在处理,因此会收费。
在 VoicePing 中,如果有 5 名参与者的 1 小时会议,仅这一场会议就需要支付 5 美元。如果同一个团队每月开 6 次这样的会议,就是 30 美元。如果参与者是 10 人而不是 5 人,就是 60 美元,仅一个团队就这么多。如果有 10 个这样的团队使用我们的应用,每月就是 600 美元。如果确实在有效利用,这不是问题。但对于 10 人参加的会议来说,并非所有人同时在说话,大部分时间只有一个人在说话。有时甚至没有人在说话,如果你参加过 Scrum 回顾会议就会知道,有时我们在屏幕上设置倒计时,大家有几分钟时间写下上一个 Sprint 的优缺点,这段时间完全没有人说话。这是 STT 使用时间的巨大浪费。
为了解决这种浪费,最直接的方法是在麦克风静音时关闭 STT。我们也这样做了,确实大幅减少了使用量,但还不够,因为这取决于用户在不说话时是否会关闭麦克风。参加过很多会议的人都知道,总有不说话但开着麦克风的用户。每次想说话时都要开关麦克风确实很烦人,只要不产生噪音,开着也无妨。
在 VoicePing 中,得益于默认启用的出色降噪功能,用户可以在整个会议期间保持麦克风开启而不打扰其他参与者。这是另一篇文章的主题,关于 VoicePing 降噪的更多信息可以查看这里:https://tagdiwalaviral.medium.com/struggles-of-noise-reduction-in-rtc-part-1-cfdaaba8cde7
事实是许多用户确实保持麦克风开启,我们需要避免在他们的无声音频上浪费 STT 使用时间。因此在将音频发送到服务进行处理之前,我们先在客户端/浏览器使用 Voice Activity Detection 进行预处理。
下面来看代码,从初始设置和预期结果开始。
初始设置
我们使用 React 和 TypeScript,因此将展示使用 React Hooks 的示例。我们使用 Azure Speech to Text 服务,所以示例会用 Azure API,但降低使用量的策略适用于任何服务。
我们创建了一个自定义 Hook useSpeechToText,代码稍后展示。先看调用这个自定义 Hook 的根组件示例:
上面的代码只有两个部分:
- 麦克风静音/取消静音按钮
- 识别到的语音列表:
我们在组件 state 中定义了结果数组,showMessage 函数将最新的 STT 结果插入数组,或在部分结果的情况下替换最后一个元素。可以在下面的演示视频中查看其工作方式。请注意:
从上面的代码可以看出,它不包含调用 STT 服务的逻辑。这些逻辑全部在 useSpeechToText Hook 内部,可以在下面的代码中查看:
虽然细节很多,但最重要的部分是向服务发送数据的地方,即 onAudioProcess 函数中的 pushStream.write(block.bytes); 调用(第 73 行)。降低服务使用量的最重要改动都围绕这一行展开。
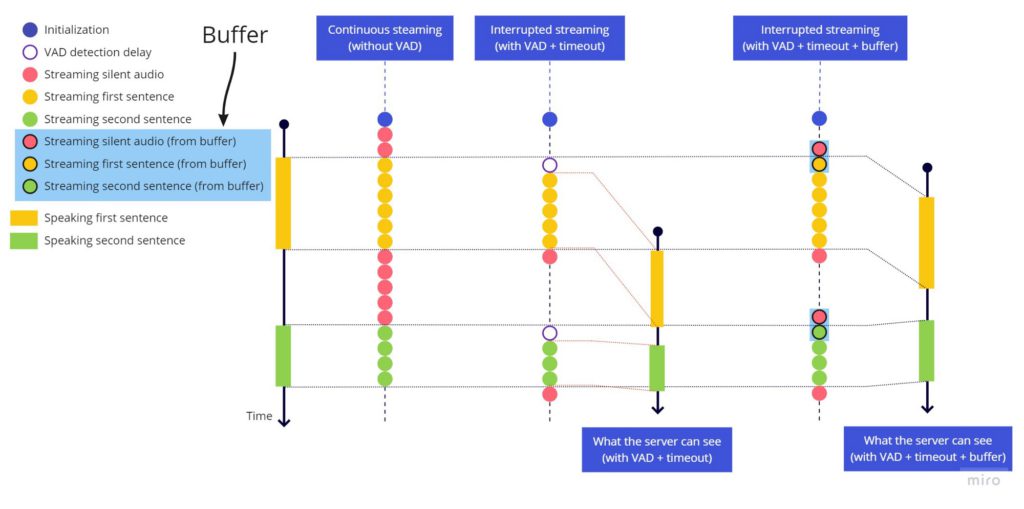
从上面的视频可以看到,麦克风未静音时,数据会持续发送到服务。为了解决这个问题,我们将 VAD 集成到这个 Hook 中。
Voice Activity Detection(VAD)
将语音转换为文本是一项复杂的工作,自己实现非常困难。但无声音频显然不包含语音,而判断音频中是否包含语音并不那么复杂。实际上已经有开源代码免费可用,我们不需要重新造轮子。有两个 npm 包可以实现这个功能。
我们选择使用 hark 包,非常容易使用。我们创建了这个可复用的 Hook:
这段代码以已有的 MediaStream 对象作为参数,在该流上实例化 hark,并将 hark 的 speaking 和 stopped_speaking 事件绑定到设置布尔状态的函数上,指示用户是否正在说话。我们将使用这个状态来开关 STT。但这并不简单,有一些问题需要处理,我们将在下面的示例中讨论。
将 VAD 代码集成到 STT 代码中
在 useSpeechToText Hook 的之前版本中,我们使用 mutedRef react ref 来检查是否应该向服务发送数据。因为 onAudioProcess 函数是在实例化 Azure 的 SpeechRecognizer 的同一个 useEffect Hook 内定义的,所以我们使用 ref 来避免重新创建 Azure 实例。
为了集成 VAD,我们使用了一个名为 streamingFlagRef 的新标志,它基于 muted state(参数 muted)和我们在 useAudioActive Hook 中定义的 VAD state(这里用 speakerActive 变量表示)。我们还使用 running.current 确保在 Azure 实例初始化之前不会开始流式传输。
我们将这些变量放在 shouldStream 变量的 AND 布尔表达式中,其变化将触发更新 streamingFlagRef ref 值的 useEffect。
现在在调用 pushStream.write(block.bytes); 发送数据时,我们检查 if (streamingFlagRef.current) 而不是 if (!mutedRef.current)。代码改动如下:
从下面的视频可以看到,停止说话时数据发送也停止了,但出现了新问题:
从上面的视频可以看到,停止说话时流式传输似乎中断得太早了,因为:
这是因为服务需要语音中的停顿来识别上一句的结束和下一句的开始。如果我们不至少流式传输一小段无声音频,服务器会将两个句子视为没有停顿的单个连续句子。
 连续流式传输(无 VAD) vs 中断流式传输(有 VAD)
连续流式传输(无 VAD) vs 中断流式传输(有 VAD)
一个简单的修复方法是在停止流式传输前添加超时,让我们添加这些高亮行来尝试:
再次测试,结果如下:
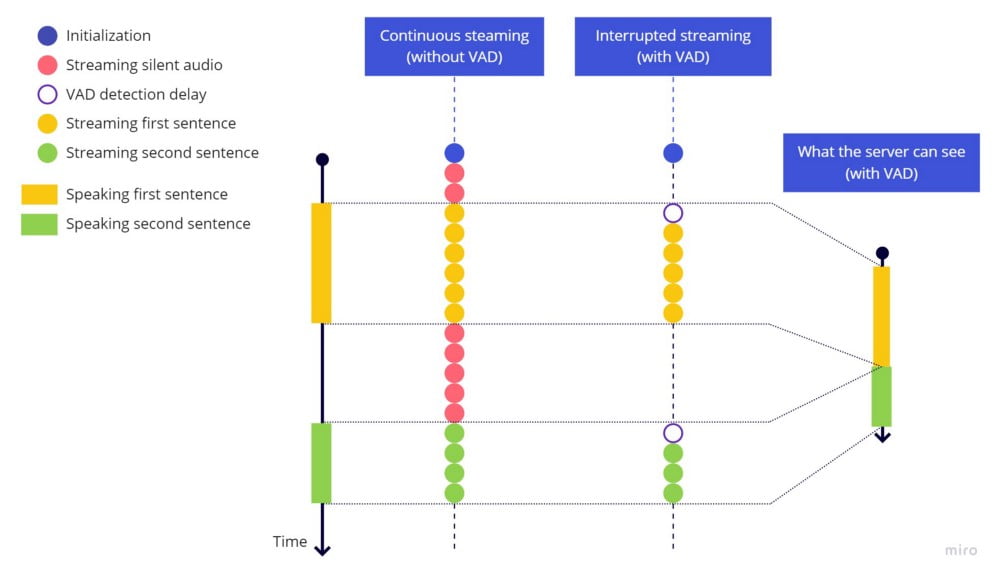
停止流式传输前的超时生效了,每个句子都正常结束,下一个句子在沉默停顿后被识别为新句子。但如果说话速度很快,句子开头会被截断。这是因为从开始说话到 VAD 库检测到声音并重新开始发送流之间存在延迟。
下面是实际发生的情况,注意每个句子开头仍然有 VAD 检测延迟造成的空白:
 连续流式传输 vs 中断流式传输(仅 VAD) vs 中断流式传输(VAD + 超时)
连续流式传输 vs 中断流式传输(仅 VAD) vs 中断流式传输(VAD + 超时)
开始发送流时,由于这个延迟,第一个词开头对应的音频部分已经丢失了。这与句末遇到的问题类似,但这里不能简单地添加超时,因为我们需要设置一个在过去执行的超时,这是不可能的。
VAD 库非常敏感这一事实使问题雪上加霜,任何小的停顿都可能触发 hark_stopped,导致弹跳效应,使流式传输在句子中间多次启停。
最终方案
由于两个问题相关联,且很难单独展示弹跳问题而不涉及截断问题,我们同时处理两者。
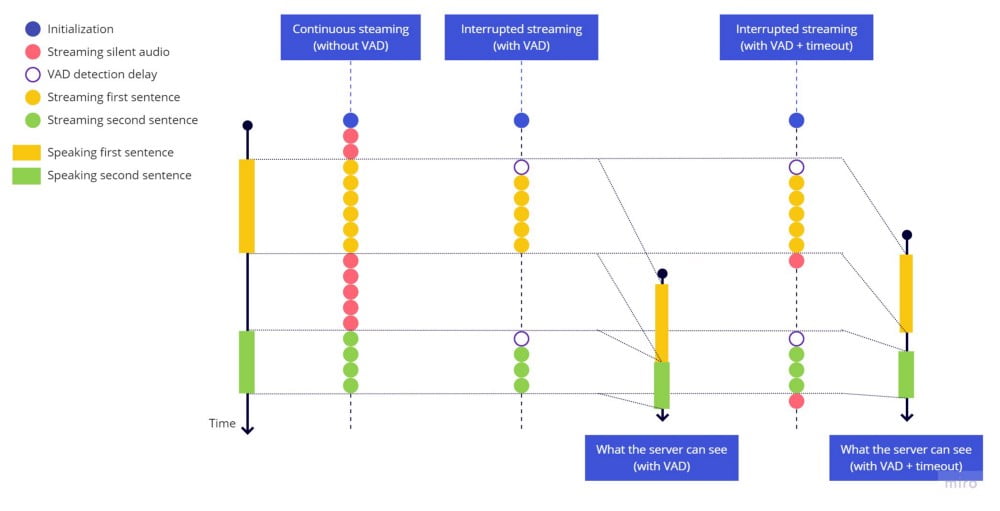
为了修复截断问题,在句首添加超时(像句末那样)没有意义,所以我们添加一个始终保持最近 2 秒音频的缓冲区。当 hark 检测到语音活动时,我们先发送整个缓冲区,然后再发送实时流。延迟并不大,但我们选择了 2 秒,因为在某些语言中,语音开始前有一些空白/静音时识别准确度更高。
为了修复弹跳效应,当 stop_speaking hark 事件触发时,我们启动一个 2 秒超时,只有在 2 秒后才停止发送流。但如果在此期间检测到语音活动(speaking hark 事件),则取消超时,就像没有检测到语音停止一样继续发送流。
改动如下:
在文件顶部添加 BUFFER_SECONDS 常量来保存缓冲区大小(秒)
在 Hook 实现顶部添加 bufferBlocks ref 来保存缓冲区数组
在控制 streamingFlagRef ref 值的 useEffect Hook 内添加处理弹跳效应的超时
在 onAudioProcess 中检查是否可以向服务流式传输音频:
在最后的 useEffect 清理函数中清空缓冲区,确保静音/取消静音麦克风时以干净的缓冲区开始
来看看效果:
使用缓冲区保持最近几秒始终可用,以便在检测到语音活动时在开始实时流之前发送,工作原理如下:
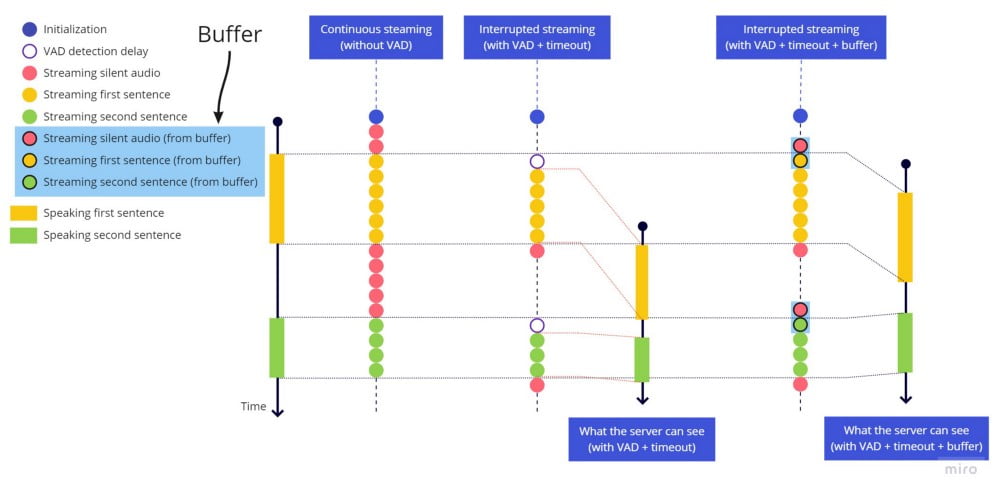 连续流式传输(无 VAD) vs 中断流式传输(VAD + 超时) vs 中断流式传输(VAD + 超时 + 缓冲区)
连续流式传输(无 VAD) vs 中断流式传输(VAD + 超时) vs 中断流式传输(VAD + 超时 + 缓冲区)
总结
从 Chrome 开发者工具的 Network 标签页可以看到,发送到 Azure 服务的数据仅在说话时产生。本文中解决的所有问题都是我们在 VoicePing 开发过程中实际遇到的。这段代码与我们目前的生产代码不完全相同,其中一个区别是我们将 createScriptProcessor(已弃用的 API)替换为 AudioWorkletNode,使用 Web Workers 在应用主事件循环之外处理音频。为了保持教程的简洁,这里展示的是 script processor 版本。
另一个我建议的架构改进是,将弹跳效应的处理保持在封装了 hark 使用的 useAudioActive 内部,而不是混合在定义 streamingFlagRef 标志值的代码中。我们的代码中没有这样做,因为 useAudioActive 在多个地方使用,在其他地方我们确实希望保持弹跳效应原样。
欢迎在 VoicePing 中体验这些功能:https://voiceping.net/
源代码
这是应用了所有先前改动的最终版本。感谢阅读。