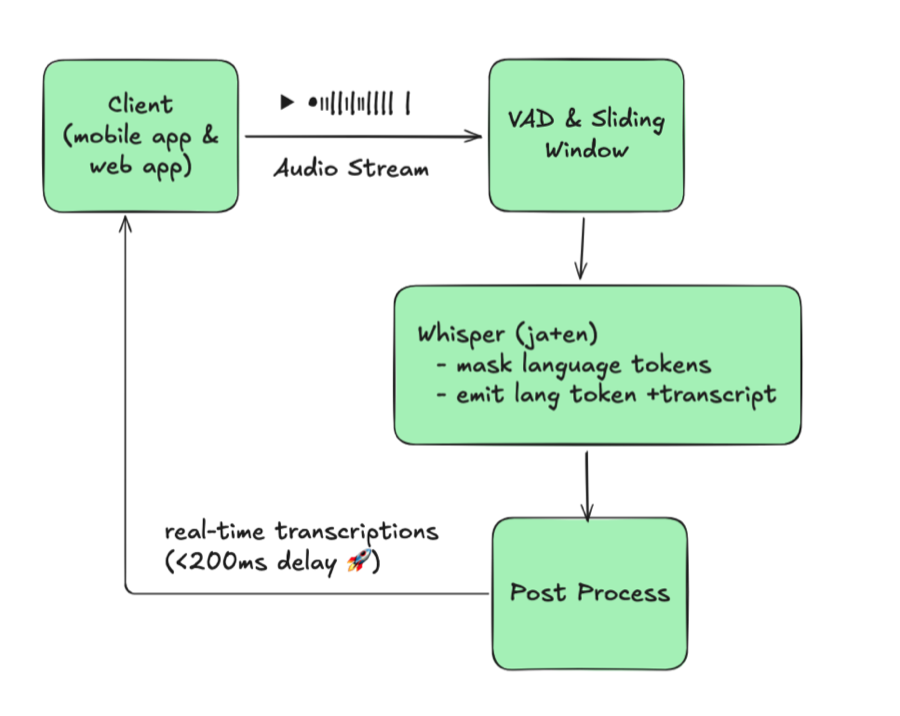
通过 AsyncLLMEngine 和合理配置 Continuous Batching,将 vLLM 推理吞吐量提升 82%
回顾:问题所在
在 Part 1 中,我们找到了瓶颈:FastAPI 服务使用多进程工作器和 IPC 队列来分发翻译任务,导致了以下问题:
- 队列序列化开销
- 工作进程间的 GPU 计算资源争用
- 尖峰状 GPU 使用率
基线:25 个并发请求时 2.2 RPS
改进方向:去掉多进程,利用 vLLM 的批量推理能力。
尝试 2:静态批处理
在现有工作进程中实现了静态批处理。
实现
| |
要点:
- 批大小:16 个请求
- 超时:50ms(不会无限等待批次填满)
- vLLM 同时处理多个序列
- 仍然使用多进程工作器
结果
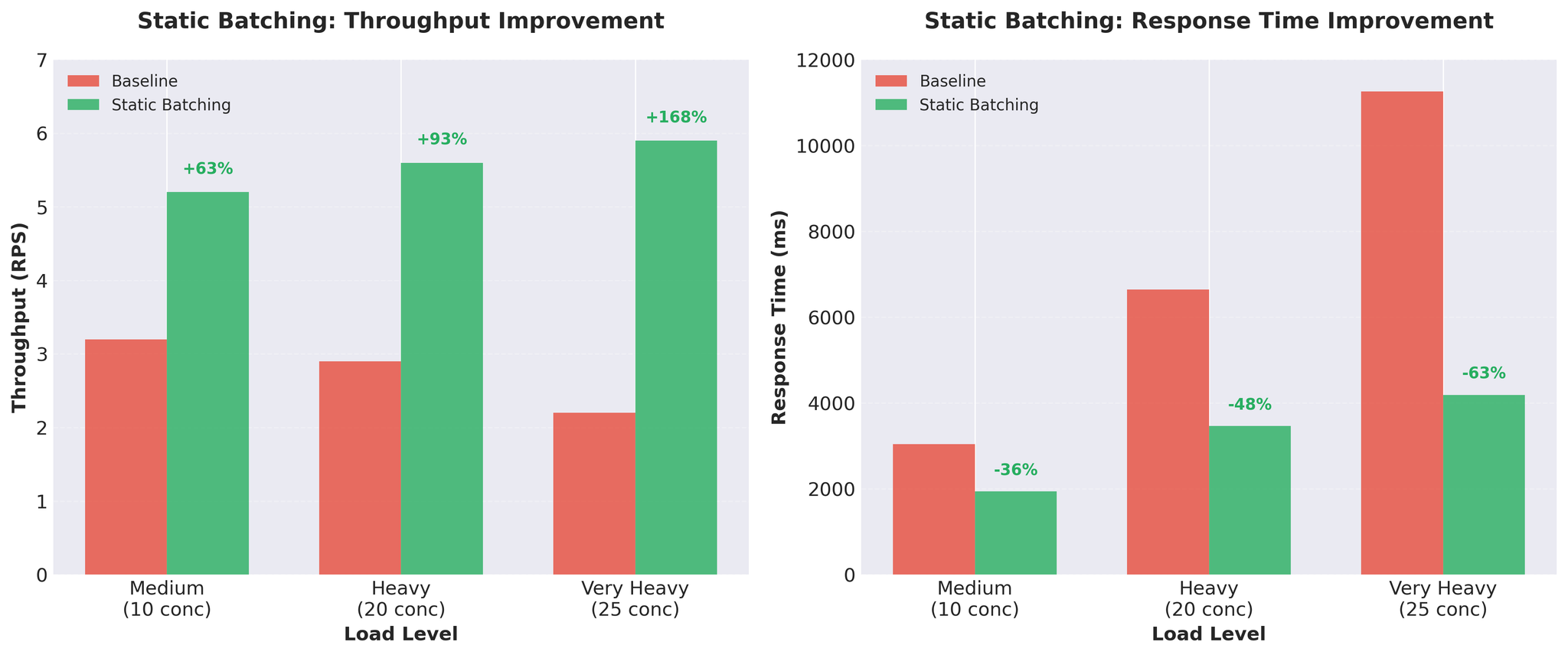
吞吐量提升近 3 倍。 每请求推理时间:452ms → 171ms。
权衡
优点:
- 大幅提升吞吐量
- GPU 利用率提高
- 实现简单
缺点:
- 队头阻塞(Head-of-Line Blocking):所有请求都要等最慢的那个完成
- 输入长度不一时,短翻译需要等待长翻译
- 示例:[50 token, 50 token, 200 token] → 前两个要等 200 token 的翻译完成
这是不错的进展,但我们想消除队头阻塞问题。
尝试 3:Continuous Batching
解决方案:使用 vLLM 的 AsyncLLMEngine 实现 Continuous Batching。
什么是 Continuous Batching?
与静态批处理不同,Continuous Batching 动态组建批次:
- 新请求可以在生成过程中加入批次
- 完成的请求立即退出(不等待其他请求)
- 每个 token 都会更新批次组成
- vLLM 的 AsyncLLMEngine 自动处理
无队头阻塞。 短翻译完成后立即返回。
实现
| |
架构变更:
- 在 FastAPI 中直接使用 AsyncLLMEngine
- vLLM 通过 Continuous Batching 引擎内部管理批处理
- 全程纯 async/await
测试现实
初始结果(均匀输入)
使用标准的均匀长度输入(相似长度)进行测试:
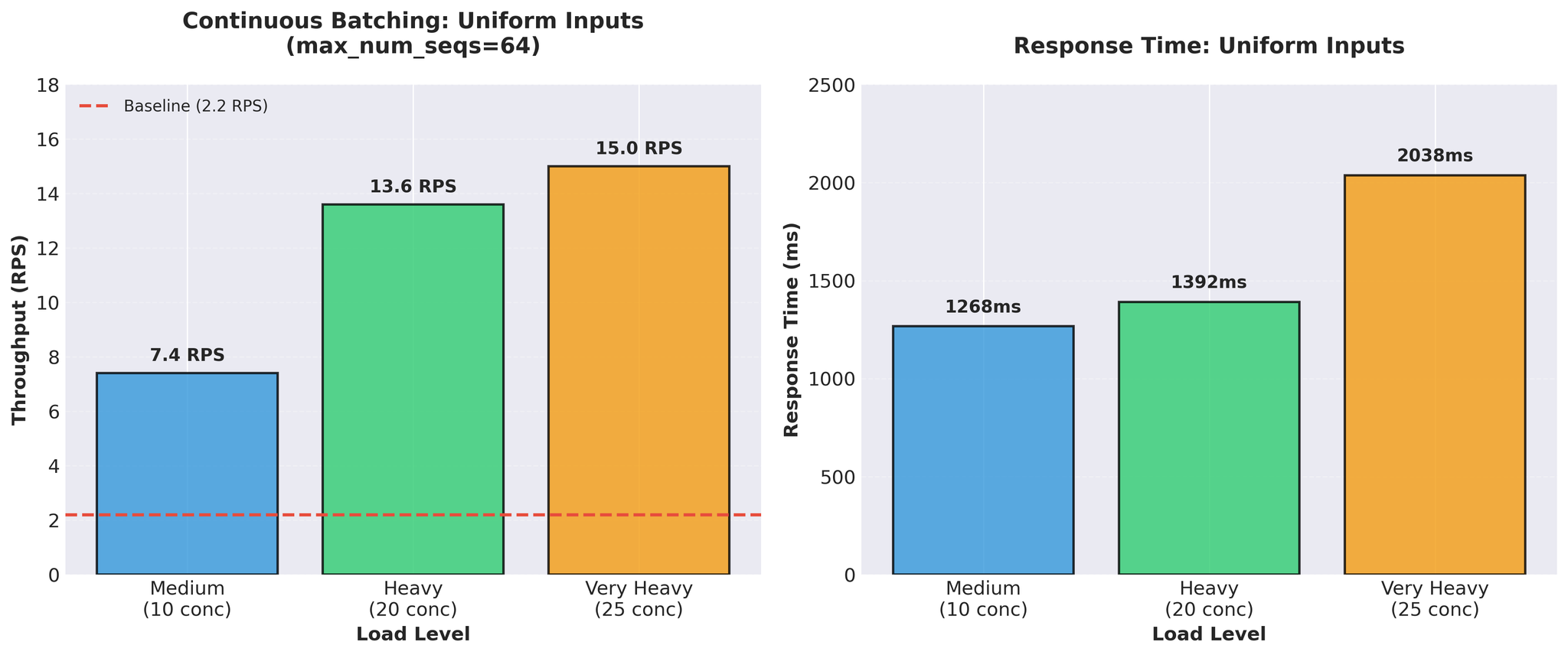
15 RPS vs 基线 2.2 — 约 7 倍提升。看起来非常出色。
可变长度输入(真实场景)
使用真实的可变长度输入(10~200 token,长短混合)进行测试:
可变输入下的基线重测:
- 极高负载:1.1 RPS(对比均匀输入的 2.2 RPS)
- 即使基线在真实数据下也表现更差
可变输入下的 Continuous Batching(max_num_seqs=64):
- 极高负载:3.5 RPS(max_num_seqs=16 调优后)
- 与均匀输入下达到 15 RPS 的同一配置
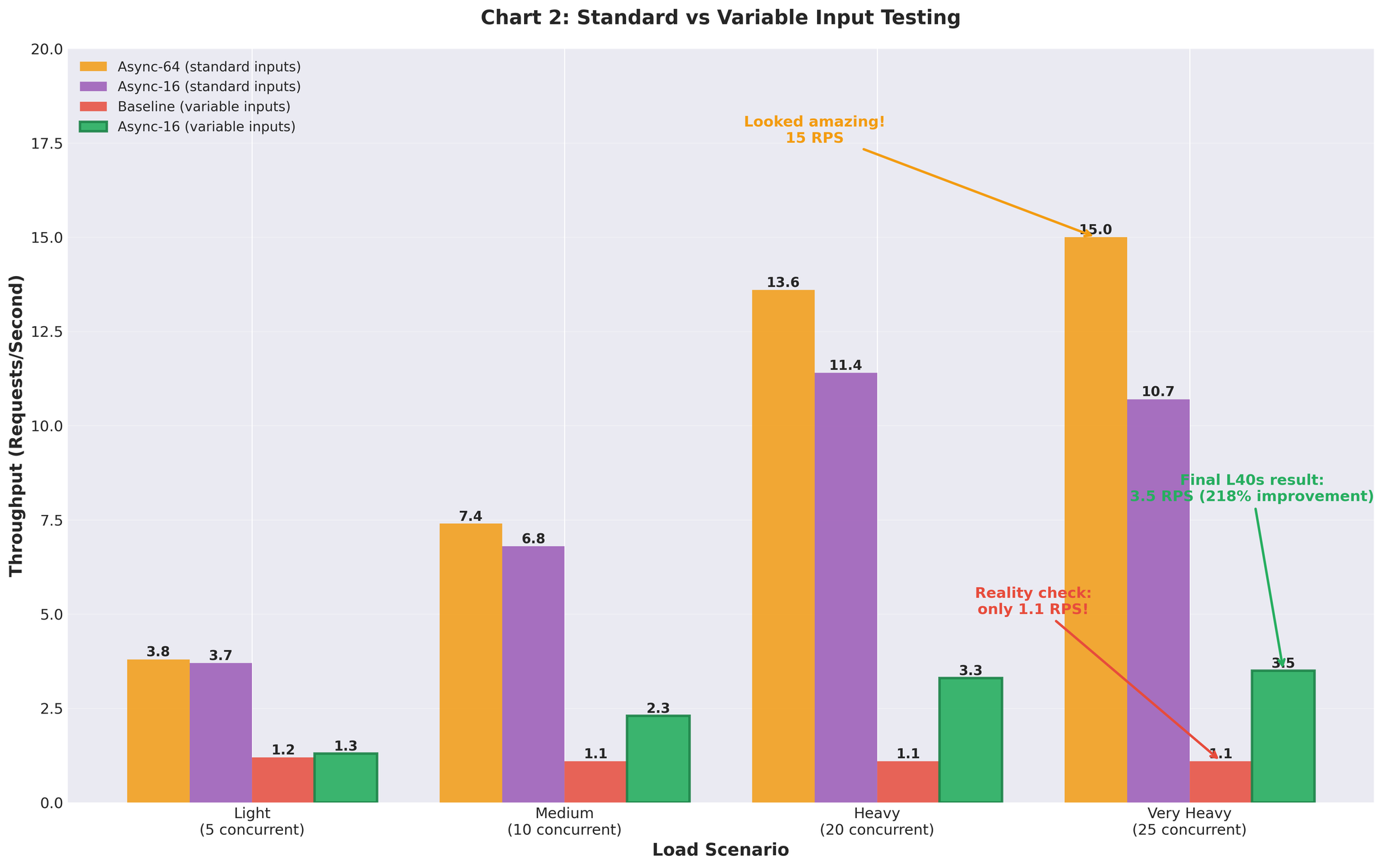
配置调优
max_num_seqs=64 在可变输入下表现不佳,促使我们分析 vLLM 内部指标。
发现
| |
问题所在:
- 实际工作负载:每台服务器 2~20 个并发请求(生产峰值约每台服务器 20 个)
- 配置:max_num_seqs=64
- 结果:60 多个空槽位产生额外开销
配置过大时的影响:
- 为 64 个序列预分配 KV 缓存
- vLLM 调度器管理 64 个槽位但实际只使用 5~10 个
- 每 token 解码时间增加
- 未使用的序列槽位浪费显存
- 空槽位的调度器开销
调优方法
遵循 vLLM Continuous Batching 调优指南:
- 测量生产环境中的实际并发请求分布
- 从 max_num_seqs=1 开始,逐步增加:2 → 4 → 8 → 16 → 32
- 每一步监控解码时间和尾部延迟
- 性能下降时停止
| max_num_seqs | 结果 |
|---|---|
| 8 | 延迟良好但吞吐量受限 |
| 16 | 最佳平衡 |
| 32 | 解码时间增加,尾部延迟恶化 |
最终配置
| |
配置依据
max_num_seqs=16:
- 生产峰值:每台服务器约 20 个并发请求
- 测试:验证到 25 个并发
- 在不浪费资源的前提下留有余量
- 调度器开销与实际负载匹配
max_num_batched_tokens=8192:
- 从默认的 16384 缩减
- 更适合实际的平均序列长度
- 降低显存压力
gpu_memory_utilization=0.3:
- 在 RTX 5090(32GB)上为模型 + KV 缓存分配约 10GB VRAM
- 通过 vllm:gpu_cache_usage_perc 追踪
- 针对配置的平衡选择
注意: 原则:根据实际工作负载配置,而非理论上限。
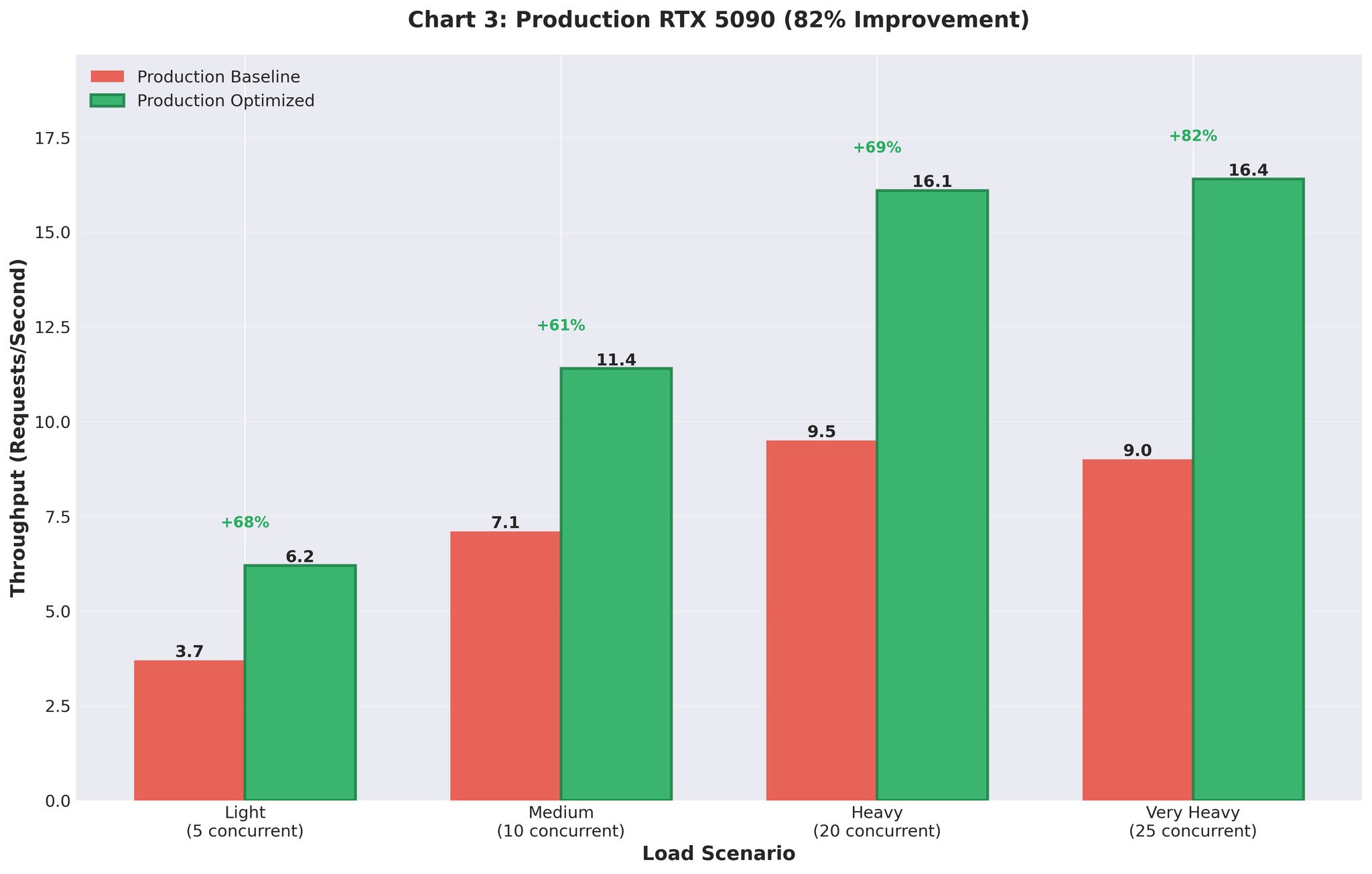
生产结果
将优化配置部署到 RTX 5090 GPU 生产环境。
优化前 vs 优化后
| 指标 | 优化前(多进程) | 优化后(优化的 AsyncLLM) | 变化 |
|---|---|---|---|
| 吞吐量 | 9.0 RPS | 16.4 RPS | +82% |
| GPU 使用率 | 尖峰状(93% → 0% → 93%) | 稳定 90~95% | 稳定 |
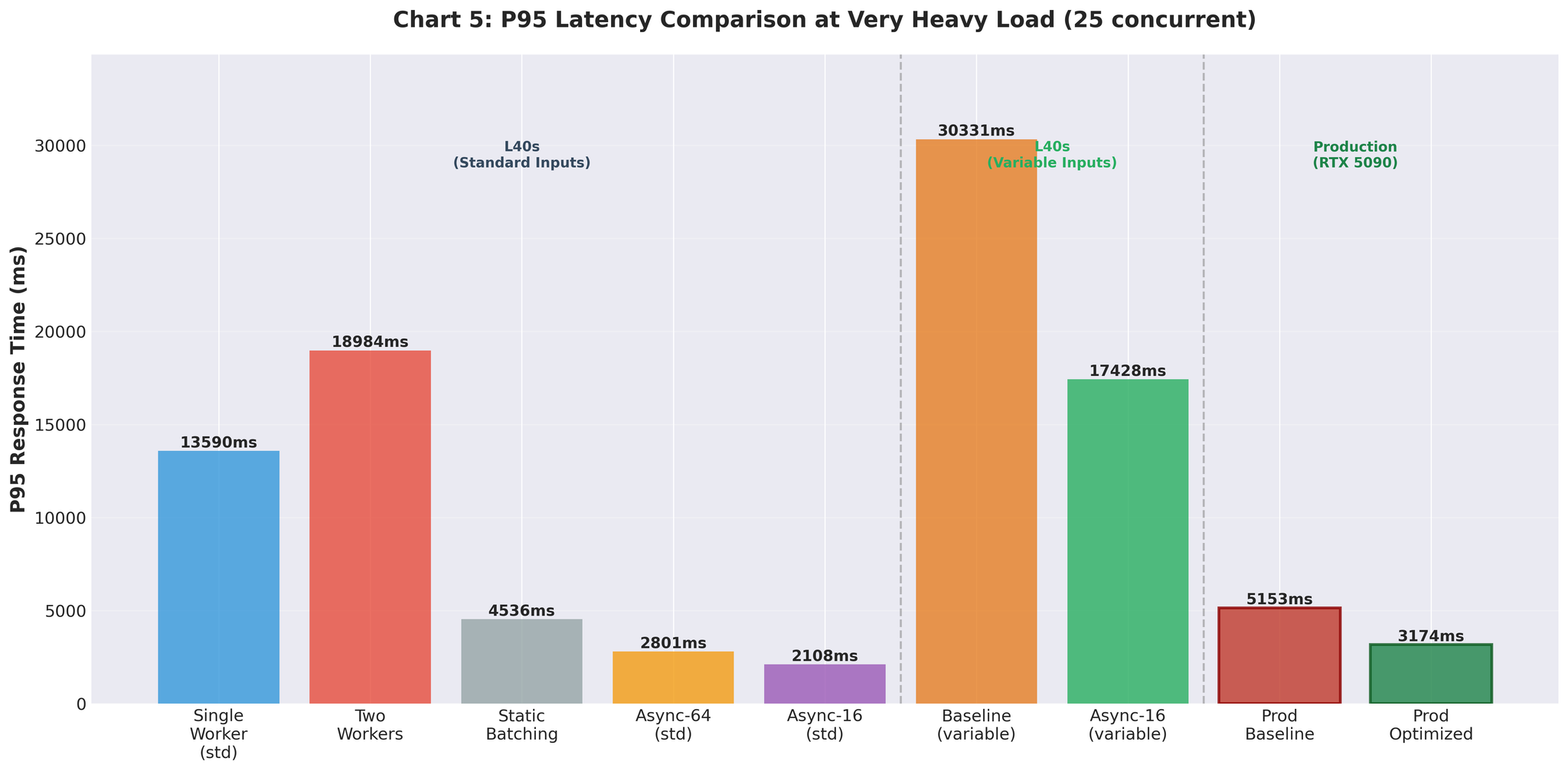
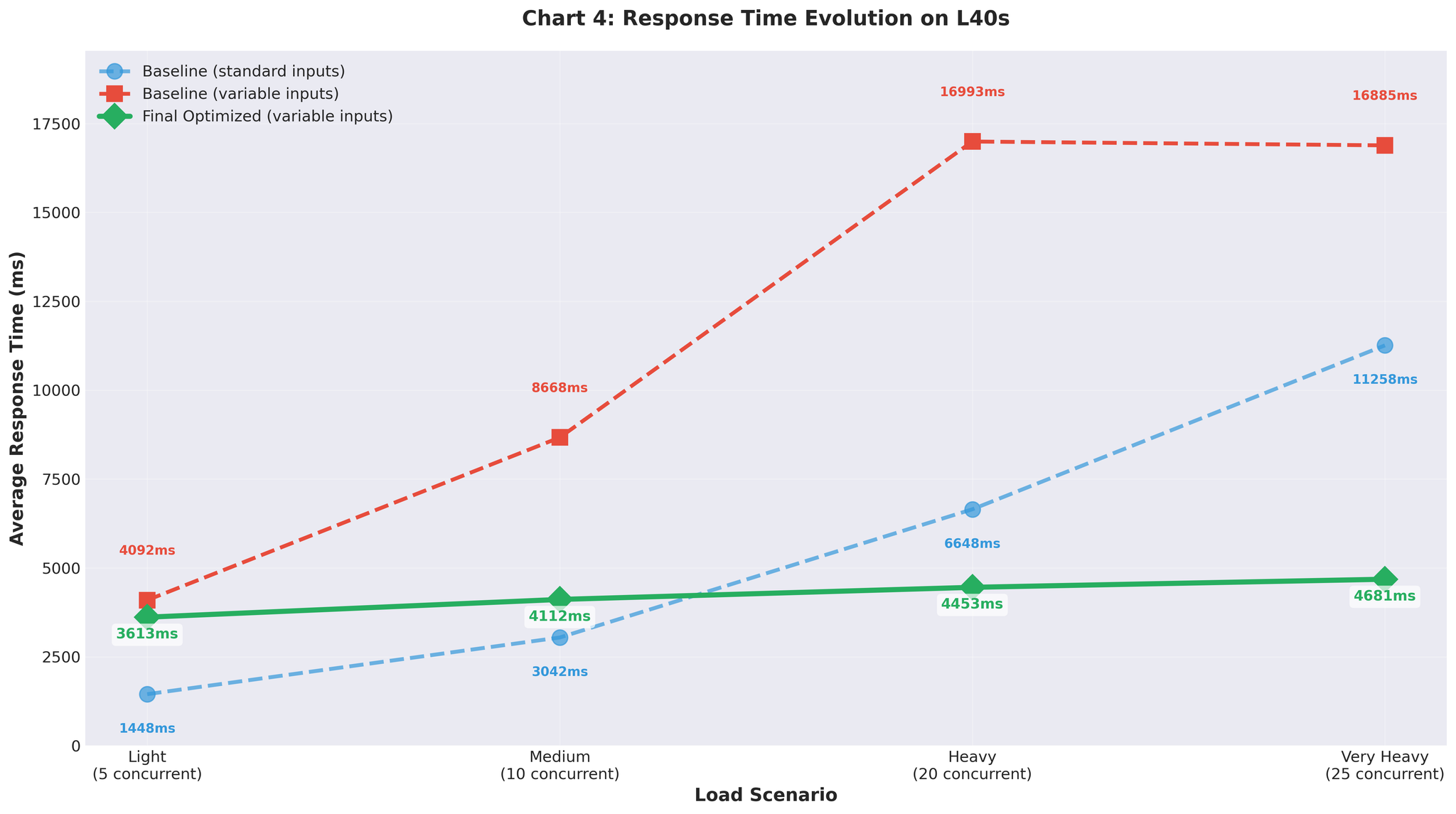
改善效果在生产中得以保持。 在真实流量下从 9 RPS 提升到 16.4 RPS。
总结
有效的方法
vLLM 的 Continuous Batching
- AsyncLLMEngine 自动管理批处理
- 无需手动批次收集开销
- 与 FastAPI 直接 async/await 集成
合理的配置选择
- max_num_seqs=16(匹配每台服务器的实际工作负载)
- 而非 64(产生开销的理论最大值)
- gpu_memory_utilization=0.3 分配 10GB
用真实数据测试
- 可变长度输入暴露了配置问题
- 均匀测试数据给出了误导性的 15 RPS 结果
监控 vLLM 指标
- KV 缓存使用率
- 每 token 解码时间
- 队列深度
- 作为配置决策的依据
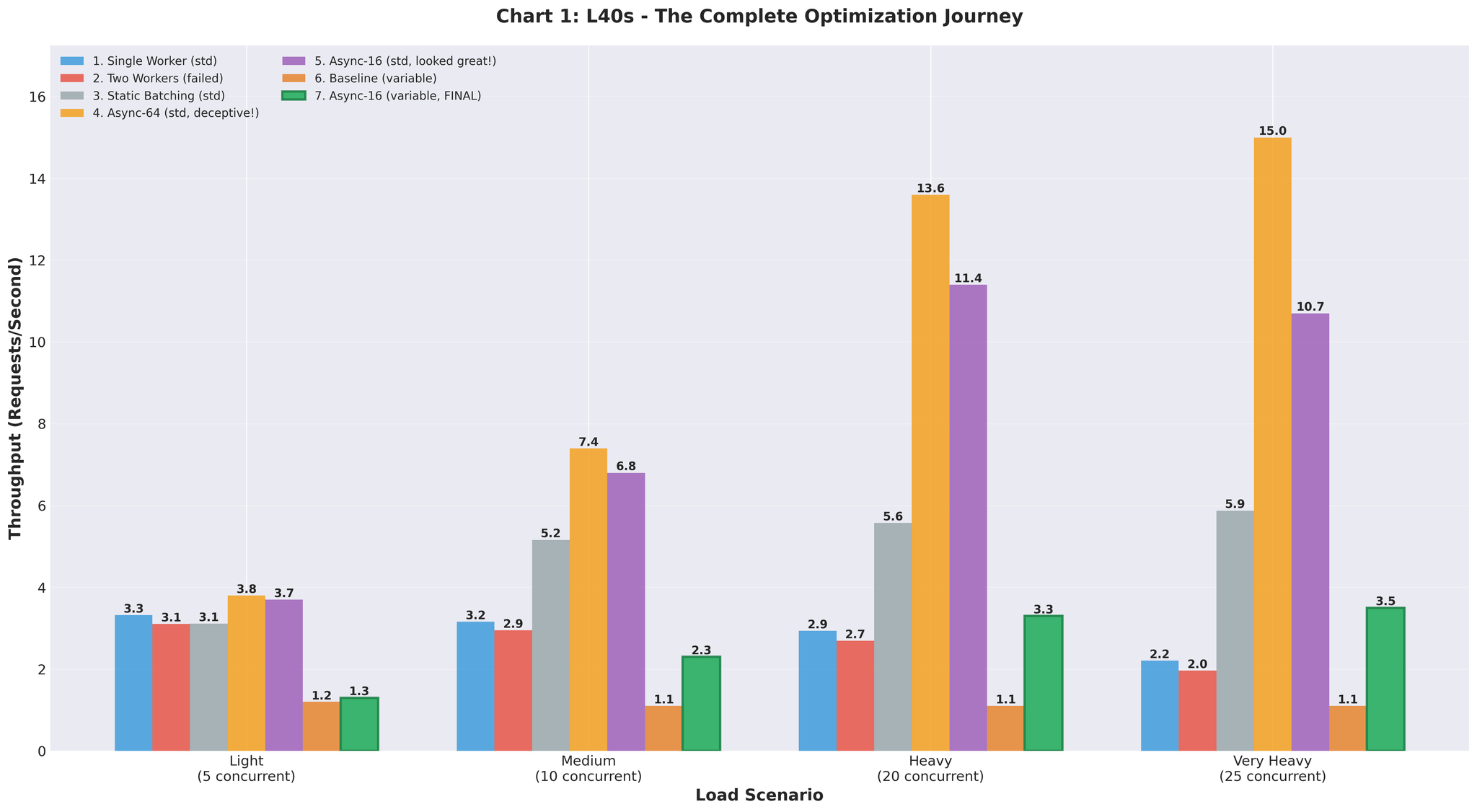
完整改进历程
| 方案 | 吞吐量 | 对比基线 | 备注 |
|---|---|---|---|
| 基线(多进程) | 2.2 RPS | - | IPC 开销,GPU 争用 |
| 双工作器 | 2.0 RPS | -9% | 反而变差 |
| 静态批处理 | 5.9 RPS | +168% | 队头阻塞 |
| Async(64,均匀) | 15.0 RPS | +582% | 误导性测试数据 |
| Async(16,可变) | 3.5 RPS | +59% | 真实但需调优 |
| 最终优化 | 10.7 RPS | +386% | 预发验证 |
| 生产 | 16.4 RPS | +82% | 真实流量,RTX 5090 |
相关文章: Part 1:翻译推理服务器扩展的瓶颈