分析 FastAPI + 多进程架构中阻碍高效 GPU 利用的架构瓶颈
问题
我们使用 FastAPI 和 vLLM 运行翻译微服务。在高负载下,服务器出现了延迟问题,但 GPU 使用率指标无法解释这一现象。
GPU 使用率呈现出不稳定的模式:急升至 93%,跌至 0%,再次急升。完全不是我们预期的持续高使用率。
核心问题:如果 GPU 存在空闲期,瓶颈究竟在哪里?
本文介绍了我们如何在 FastAPI + 多进程架构中找到阻碍高效 GPU 利用的架构问题。
系统架构
翻译服务以多台 API 服务器的形式在负载均衡器后运行。
- 客户端:Web、移动端、后端服务
- 代理:根据语言对和服务器健康状态路由请求
- API 服务器:多个 FastAPI 实例,每个运行 vLLM
本文重点关注单台 API 服务器的内部架构和瓶颈。
API 服务器架构
以下是一台 API 服务器的内部结构。

组件
1. FastAPI 主进程
| |
- 使用 async/await 处理 HTTP 请求
- 单个 Python 进程,一个事件循环
- 非阻塞 I/O 实现并发请求处理
2. TranslationService
| |
- 创建翻译任务
- 管理带有 asyncio.Event 的 EventTask 对象
- 在 async/await 和多进程之间架起桥梁
3. TranslationWorker(主进程)
| |
- 在主进程中创建队列(与工作进程共享)
- 用于任务分发的 JoinableQueue
- 用于共享任务状态的 manager().dict()
- 用于结果返回的 Event queue
4. 工作进程
| |
- 作为独立进程启动(ctx.Process)
- 每个工作进程加载自己的 vLLM 模型实例
- 从共享 translation_queue 中拉取任务
- 通过共享 event_queue 返回结果
5. EventTask(异步同步机制)
| |
- 在多进程和 async/await 之间架起桥梁
- 为每个请求分配 EventTask
await event.wait()阻塞协程直到工作进程完成
请求流程
以下是单个翻译请求的完整处理流程。

步骤说明:
- 客户端 POST /translate → FastAPI 创建异步协程
- async translate() → TranslationService 处理请求
- create_task() → 生成 ID,在共享字典中创建 TranslationTask
- queue.put(key) → 序列化任务键,发送给工作进程(IPC 开销)
- 工作进程:vllm.translate() → 执行翻译
- event_queue.put(result) → 序列化结果,返回(IPC 开销)
- event.set() → 更新 EventTask,唤醒协程
- await event.wait() 解除阻塞 → 获取结果
- 返回响应 → 发送给客户端
开销所在:
- 第 4 步:序列化(pickle 任务键)
- 第 6 步:序列化(pickle 结果)
- 第 8 步:异步等待多进程结果
- 贯穿全程的 IPC 协调
基线性能
优化前的状态:
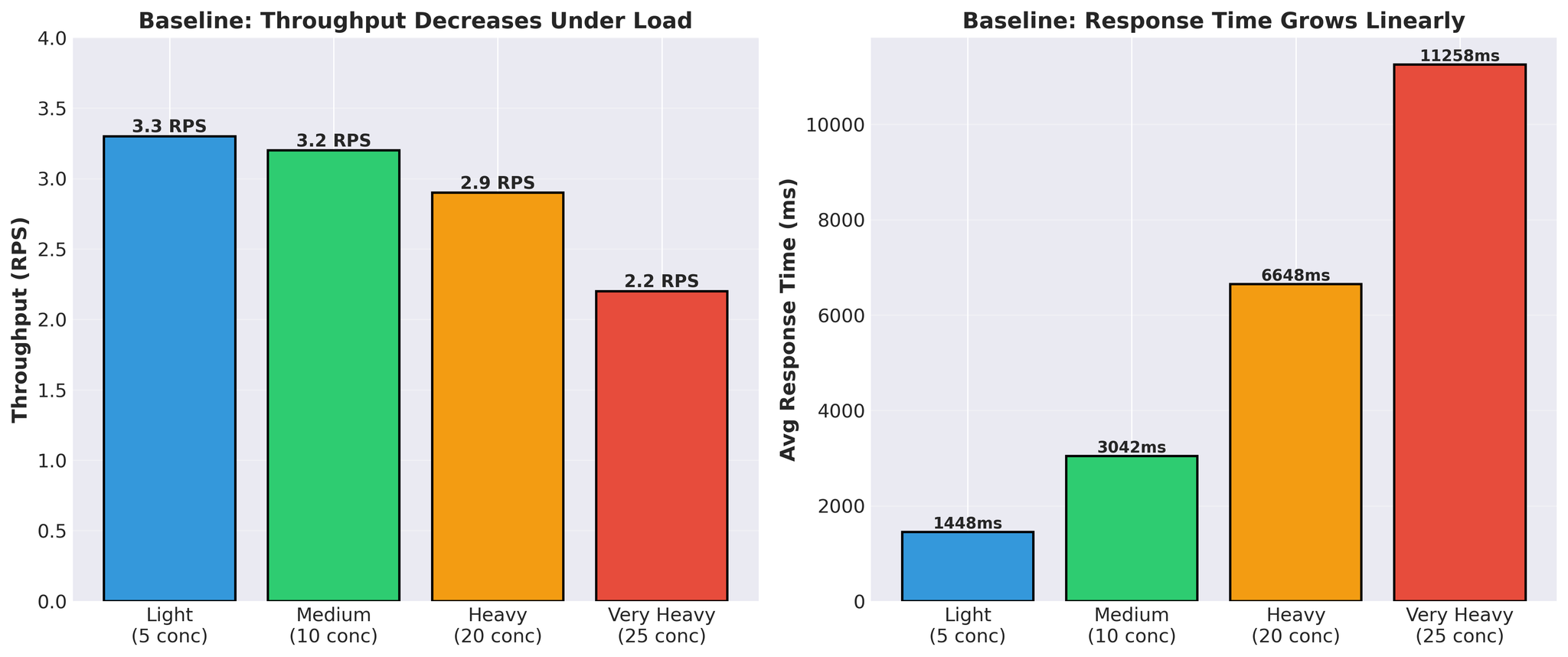
模式特征:
- 响应时间线性增长(1.4秒 → 11.3秒)
- 负载下吞吐量下降(3.3 → 2.2 RPS)
- 实际 vLLM 翻译时间:每请求 300~450ms
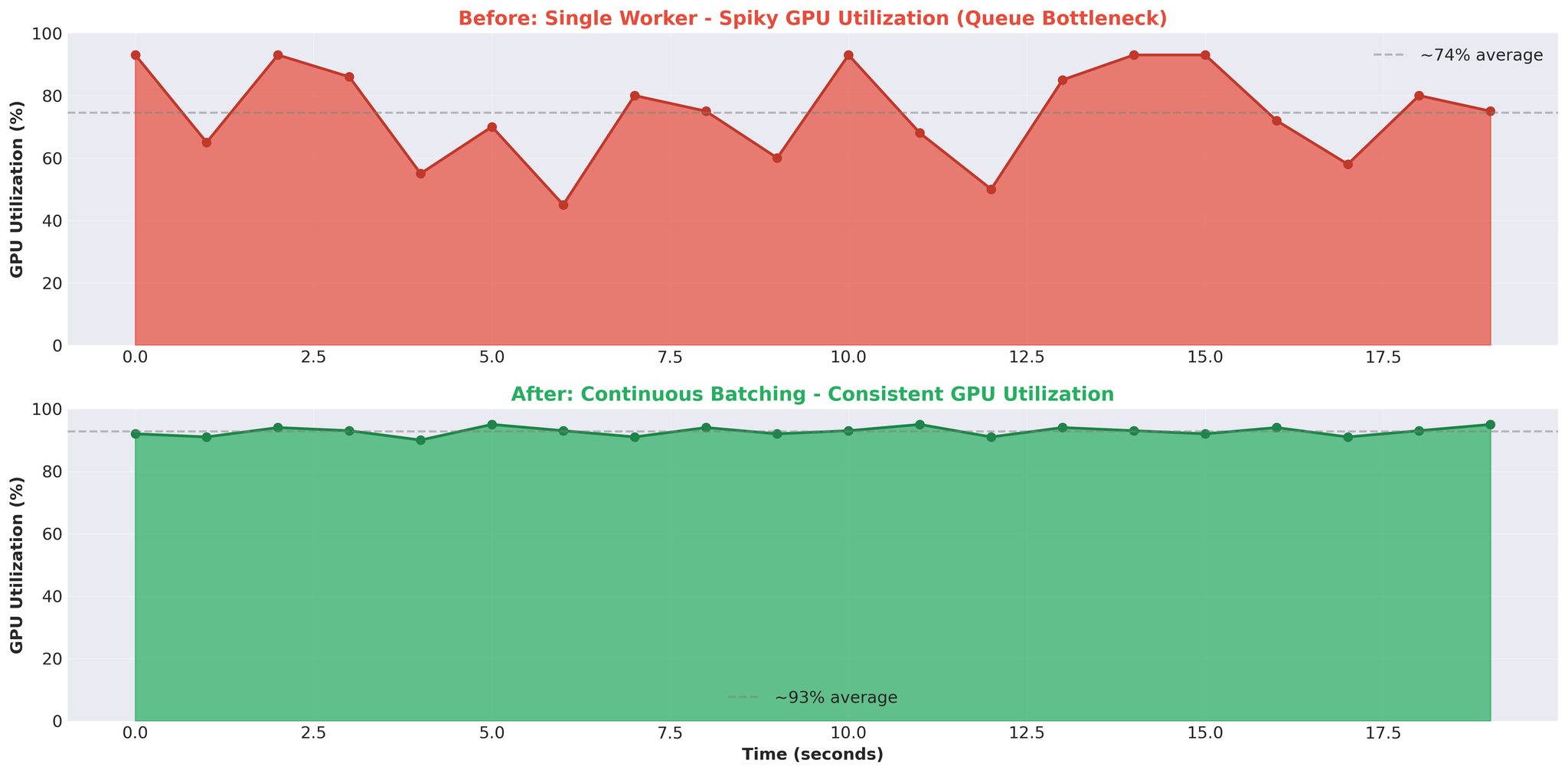
尖峰状模式:GPU 在繁忙和空闲之间交替。这表明 GPU 在等待任务,而非计算能力不足。
尝试 1:增加工作进程
第一个假设:更多工作进程 = 更好的并行化。
将工作进程从 1 个增加到 2 个。
配置
| |
- 工作进程 1:模型 A+B
- 工作进程 2:模型 C
- 共享同一块 GPU
结果
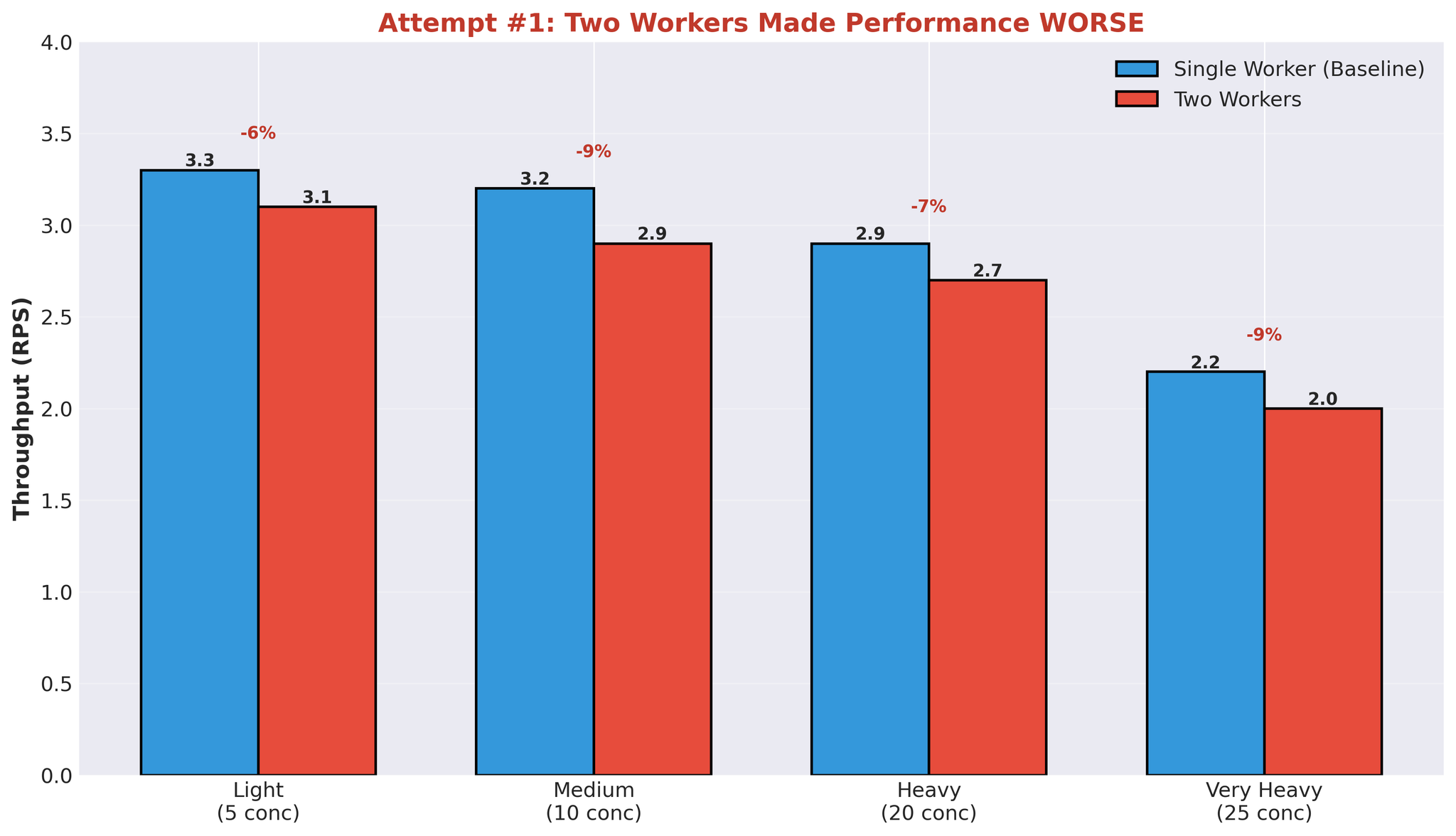
翻译时间中位数也恶化了:452ms → 2,239ms。
所有负载水平下性能均出现下降。
多工作进程失败的原因
理解了 GPU 的行为方式和架构后,这个结果就不难解释了。

问题所在:计算资源争用
当一个工作进程在处理翻译时:
- 占用了约 90% 的 GPU 计算能力
- 其他工作进程无法有效地并行利用剩余能力
- 工作进程只能等待 GPU 可用
为何没有并行收益:
- 工作进程 1 开始 vLLM 生成 → 使用约 90% GPU 计算能力
- 工作进程 2 尝试启动 → 仅约 10% GPU 计算能力可用
- 工作进程 2 缓慢运行或等待
- 尽管是独立进程,实际上是顺序执行
额外开销:
- 进程启动和管理
- 工作进程间的 GPU 显存分割(各自加载模型权重)
- IPC 队列协调
- 进程间上下文切换
GPU 技术上可以同时运行多个 CUDA 内核,但当一个工作进程已使用约 90% 计算能力时,剩余能力不足以让另一个工作进程高效并行运行。
其他架构问题
当多个工作进程争夺相同资源时:
- 上下文切换开销:操作系统在工作进程间切换
- 显存使用翻倍:每个工作进程都加载完整的模型权重
- 没有实际并行性:并行架构却是顺序 GPU 执行
所有工作进程使用相同的队列(共享 translation_queue 和 event_queue),因此每个请求的 IPC 开销不变。然而,进程管理、上下文切换和显存重复带来的额外开销,加上没有 GPU 并行收益,使得性能更差。
已识别的瓶颈
通过这次实验,我们确认了核心问题所在。
1. IPC 序列化开销
- 每个请求都需要:序列化任务 → 工作进程,序列化结果 → 主进程
- Python 多进程队列使用 pickle
- 每个请求都有开销
2. 计算资源争用
- 一个工作进程使用约 90% GPU 计算能力
- 其他工作进程无法有效并行运行
- 多进程模式下实质是顺序执行
3. Async/Await + 多进程桥接
- asyncio.Event 等待多进程结果
- 基于线程的事件队列消费者
- 异步模型和多进程模型之间的协调开销
4. GPU 周期浪费
- GPU 在等待队列操作时空闲
- 尖峰状使用率(93% → 0% → 93%)
- 翻译时间约 400ms,总响应时间超过 11 秒
- 大部分时间花在队列上,而非计算
5. 架构复杂性
- FastAPI(async/await)
- TranslationService(桥接层)
- TranslationWorker(协调层)
- JoinableQueue(IPC)
- 工作进程(多进程)
- Event queue(IPC)
- EventTask(异步同步)
- vLLM(实际工作)
每一层都增加了延迟。
关键发现
1. Async/Await + 多进程 = 开销
桥接这两种并发模型需要协调:
- 用于异步等待的 asyncio.Event
- 用于消费事件队列的线程池
- 进程边界处的序列化
这种桥接是有代价的。
2. 多进程 ≠ GPU 并行
以下情况中,增加工作进程并不能提升 GPU 利用率:
- 一个工作进程使用约 90% GPU 计算能力
- 剩余能力不足以支撑并行工作
- 多进程开销下的顺序执行
3. 队列开销占主导
在 25 个并发请求下:
- vLLM 翻译时间:约 400ms
- 总响应时间:11,258ms
- 队列开销:占总时间的约 97%
绝大部分时间花在队列和协调上,而非计算。
4. 尖峰状 GPU 使用率 = 架构问题
- 稳定的 GPU 使用率(如 90~95%)表示计算密集型工作负载
- 尖峰状模式(93% → 0% → 93%)表示 GPU 在等待工作——瓶颈在其他地方(我们的情况是队列和 IPC)
总结
瓶颈不在 GPU 计算能力,而在多进程架构本身。
已识别的问题:
- 队列序列化带来的 IPC 开销
- 没有实际并行性的 GPU 计算争用
- Async/await + 多进程协调开销
- 大部分延迟来自队列等待,而非 vLLM 处理
症状:
- 尖峰状 GPU 使用率
- 队列等待占据响应时间的主要部分
- 增加工作进程反而使性能变差
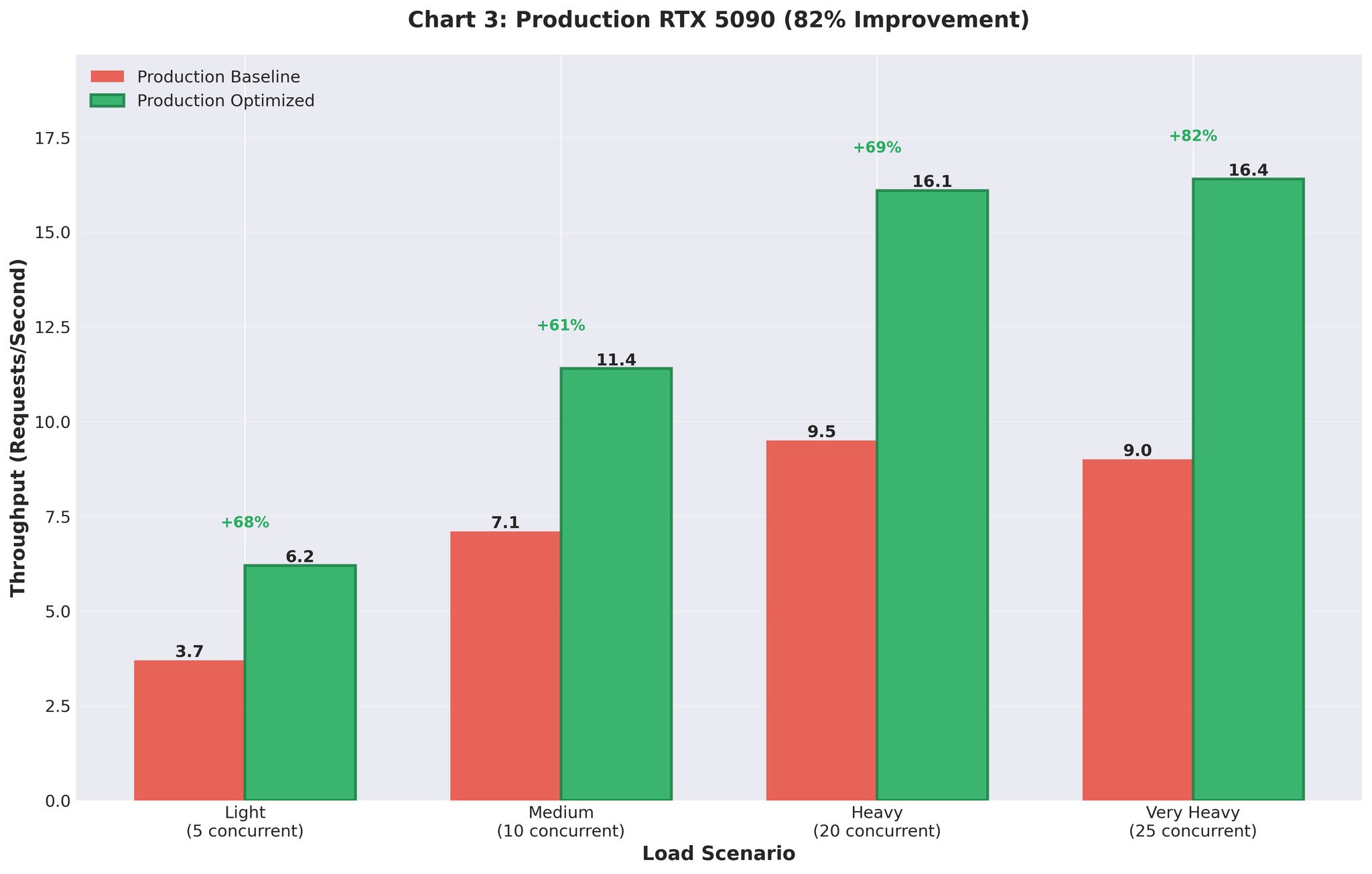
预告: 在 Part 2 中,我们将介绍解决方案:去掉多进程,直接使用 vLLM 的 AsyncLLMEngine,在生产环境中实现了吞吐量提升 82%。
下期内容:
- 完全移除多进程架构
- 将 vLLM 的 AsyncLLMEngine 与 FastAPI 直接集成
- 合理配置 Continuous Batching
- 生产成果:吞吐量提升 82%