通过 DER 分析和实时应用开发,对说话人分离框架进行比较评估。验证 Pyannote.audio 与 Nvidia NeMo 之间的性能差异。
摘要
本文评估并比较了两个先进的开源说话人分离框架:Pyannote.audio 和 Nvidia NeMo。评估重点关注不同音频场景下的 Diarization Error Rate(DER)、执行时间和 GPU 资源使用情况。此外,还探索了使用 OpenAI GPT-4-Turbo 进行后处理以提高分离准确率的方法。
主要结果:
- Nvidia NeMo 在 2 人说话人场景中 DER 低约 9%
- Pyannote.audio 在多说话人(9人以上)场景中表现更优
- GPT-4-Turbo 后处理展现出潜力,但需要集成音频上下文
- 展示了实时说话人分离 Web 应用
1. 引言
什么是说话人分离?
说话人分离是根据不同的说话人对音频进行分段和标注的过程,回答"谁在什么时候说了什么"这一问题。它与自动语音识别(ASR)结合使用,是对话分析的关键工具。
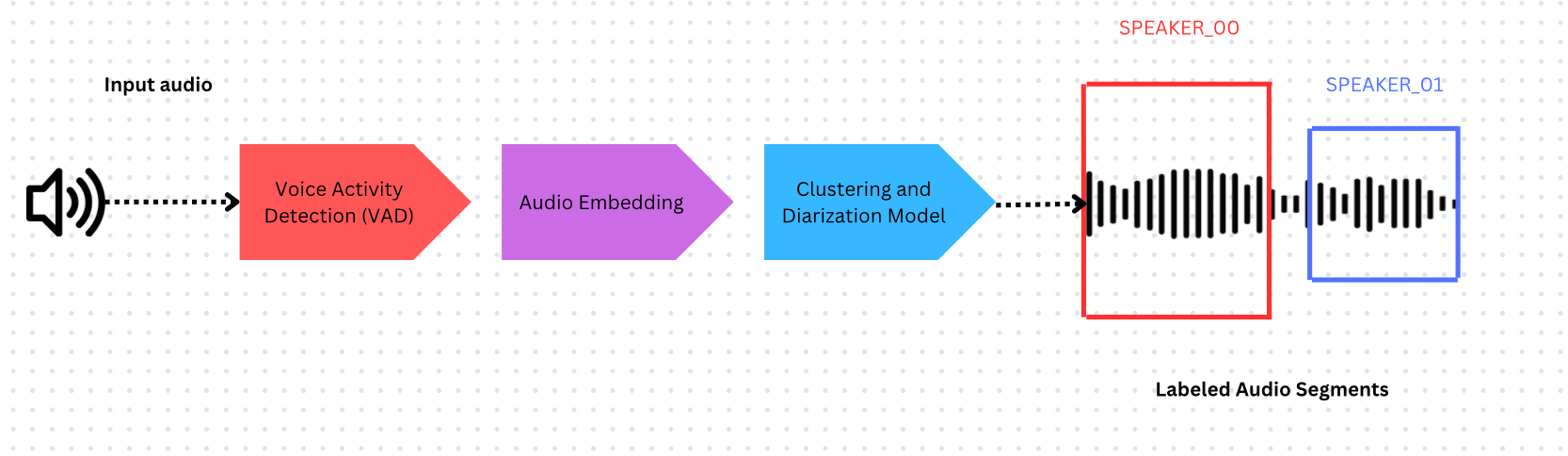
说话人分离系统由以下部分组成:
- 语音活动检测(VAD) - 识别语音出现的时间戳
- 音频嵌入模型 - 从带时间戳的片段中提取嵌入向量
- 聚类 - 对嵌入向量进行分组以估计说话人数量
Pyannote.audio
Pyannote.audio 是基于 PyTorch 的开源 Python 工具包,用于说话人分离和说话人嵌入。
Nvidia NeMo
Nvidia NeMo 采用了不同的方法,使用多尺度分割和 Neural Diarizer(MSDD 模型)来处理说话人重叠语音。
多尺度分割
NeMo 解决了说话人识别质量与时间粒度之间的权衡问题:
- 较长片段 → 说话人表征质量更高,但时间分辨率较低
- 较短片段 → 说话人表征质量较低,但时间分辨率较高
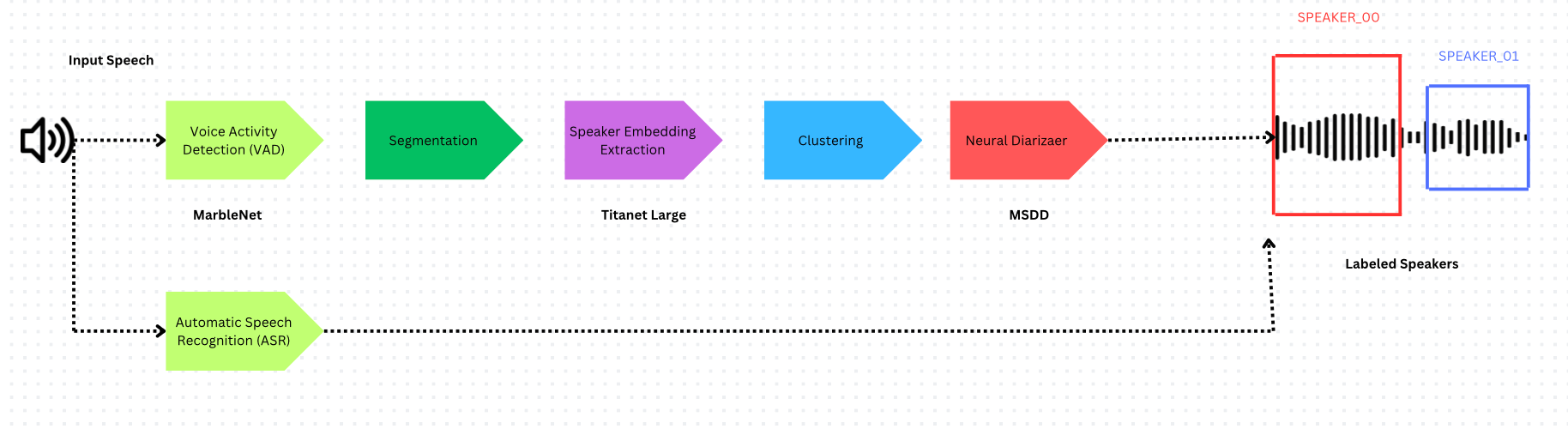
框架对比
| 组件 | Pyannote.audio | Nvidia NeMo |
|---|---|---|
| VAD | Pyannote from SyncNet | Multilingual MarbleNet |
| 说话人嵌入 | ECAPA-TDNN | Titanet Large |
| 聚类 | Hidden Markov Model | Multi-scale Clustering (MSDD) |
2. 评估方法
Diarization Error Rate(DER)
说话人分离的标准评估指标,由 NIST 于 2000 年提出:
DER = (False Alarm + Missed Detection + Confusion) / Total
各项含义:
- False Alarm:没有说话人时却检测到了语音
- Missed Detection:有说话人时却未检测到语音
- Confusion:语音被分配给了错误的说话人
注意: DER 越接近 0,表示错误越少。
RTTM 文件格式
Rich Transcription Time Marked(RTTM)是说话人分离输出的标准格式:
SPEAKER obama_zach(5min).wav 1 66.32 0.27 <NA> <NA> SPEAKER_01 <NA> <NA>
关键字段:片段起始时间(66.32)、持续时间(0.27)、说话人标签(SPEAKER_01)
3. 实验设置
数据集
- 5 分钟音频 - 2 位说话人(Obama-Zach 访谈),使用 Audacity 手动标注
- 9 分钟音频 - VoxConverse 数据集中的 9 位说话人,附带专业标注的标准答案
硬件
- GPU:Nvidia GeForce RTX 3090
- 使用 Python 的
time模块进行计时
Pyannote.audio 代码
| |
Nvidia NeMo 代码
| |
4. 结果与讨论
DER 结果 - 2 位说话人(5 分钟)
| 框架 | DER |
|---|---|
| Pyannote.audio | 0.252 |
| Pyannote.audio(预先识别说话人) | 0.214 |
| Nvidia NeMo | 0.161 |
| Nvidia NeMo(预先识别说话人) | 0.161 |
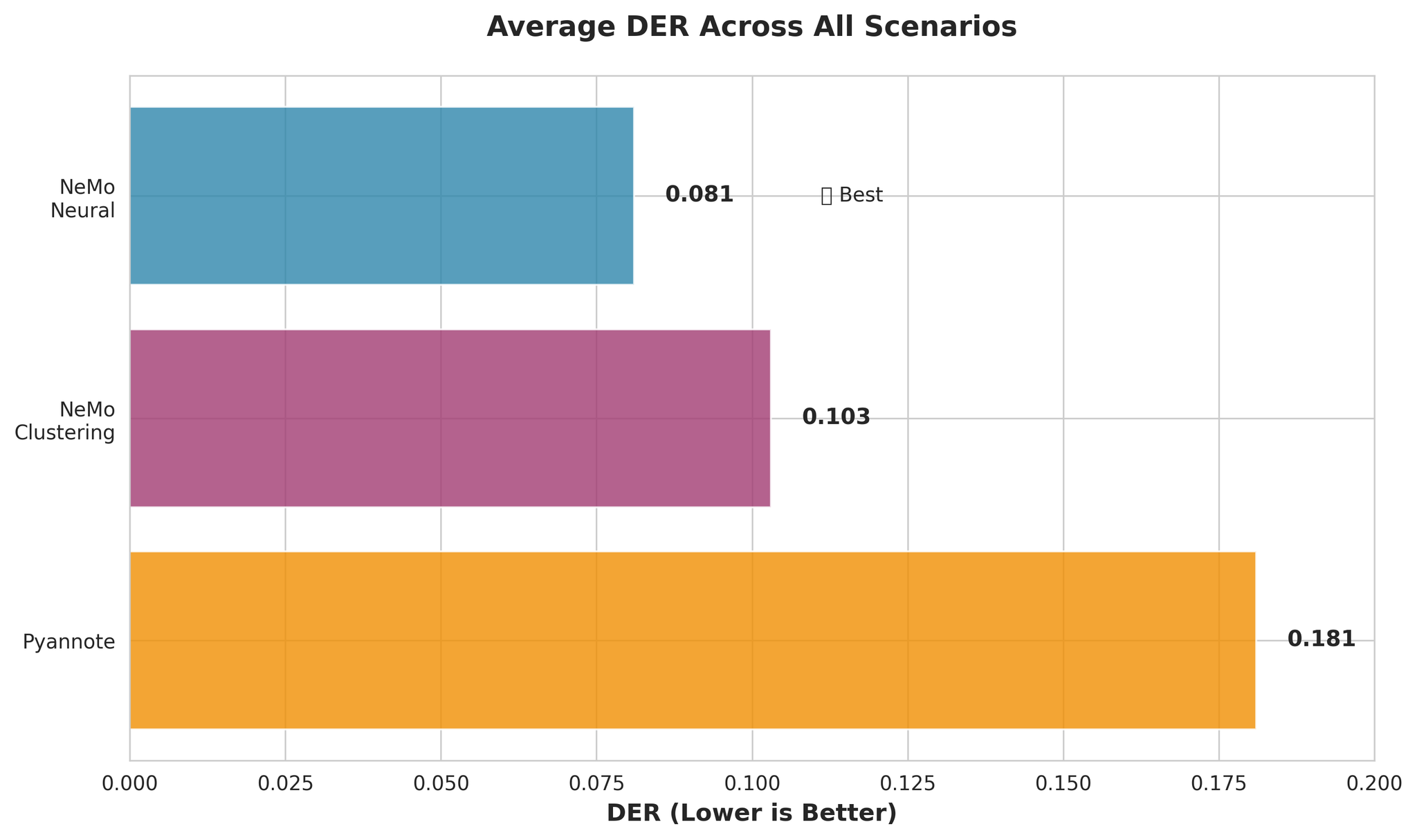
要点: 在 2 人说话人场景中,Nvidia NeMo 比 Pyannote.audio 的 DER 低约 9%。
DER 结果 - 9 位说话人(9 分钟)
| 框架 | DER |
|---|---|
| Pyannote.audio | 0.083 |
| Pyannote.audio(预先识别说话人) | 0.098 |
| Nvidia NeMo(预先识别说话人) | 0.097 |
在多说话人场景中,Pyannote.audio 比 Nvidia NeMo 的 DER 低约 1.4%。
GPT-4 后处理结果
| 框架 | GPT-4-Turbo DER | GPT-3.5 DER |
|---|---|---|
| Pyannote(5分钟, 2人) | 0.427 | 0.494 |
| Nemo(5分钟, 2人) | 0.179 | 0.544 |
| Pyannote(9分钟, 9人) | 0.103 | 0.214 |
| Nemo(9分钟, 9人) | 0.128 | 0.179 |
注意: GPT-4 后处理的 DER 偏高,原因是它无法直接访问音频数据。提供说话人时间信息和音频上下文有望改善结果。
执行时间对比
| 框架 | 5分钟音频 | 9分钟音频 |
|---|---|---|
| Pyannote.audio | 31.3秒 | 44.5秒 |
| Pyannote(预先识别说话人) | 29.8秒 | 41.5秒 |
| Nvidia NeMo | 63.9秒 | - |
| Nemo(预先识别说话人) | 49.9秒 | 108.2秒 |
Nvidia NeMo 的执行时间约为 Pyannote.audio 的 2 倍。
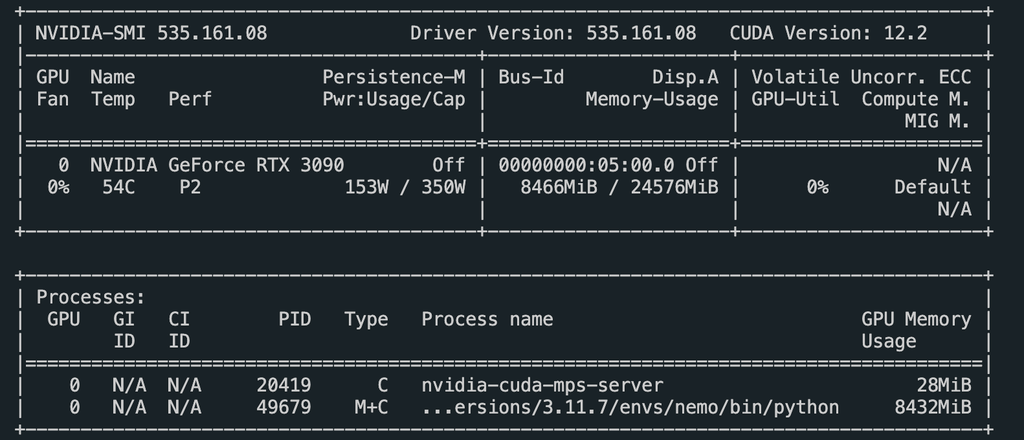
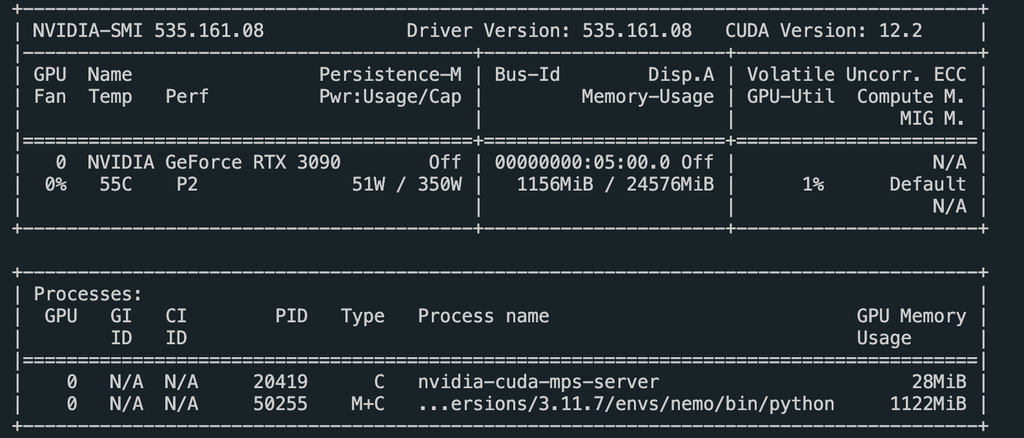
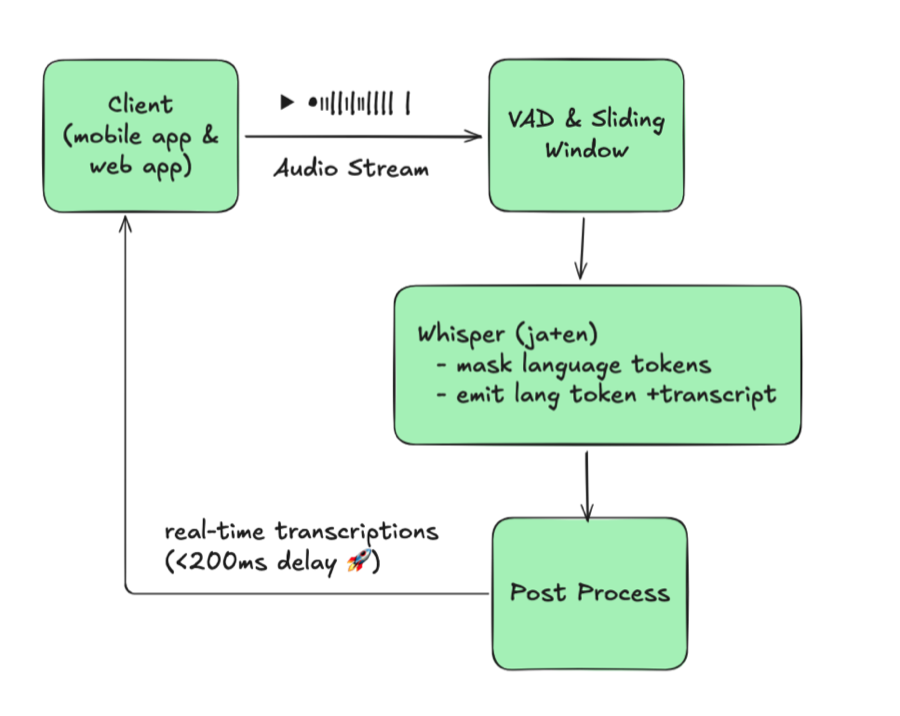
5. 实时应用
我们使用以下技术开发了实时说话人分离 Web 应用:
- WebSockets 实现音频流传输
- FastAPI 作为后端框架
- Pyannote.audio 进行说话人分离
关键实现细节
为了提升实时性能,使用 3 秒音频块替代 30 秒音频块:
| |
结果对比


改进后的分块逻辑显著减少了时间误差,说话人切换也更加流畅。
6. 总结
主要发现
- Nvidia NeMo 在短音频、少说话人场景中表现更优(DER: 0.161 vs 0.252)
- Pyannote.audio 在说话人数量较多或预先识别说话人的情况下表现更好
- GPT-4 后处理展现出潜力,但需要集成音频上下文
- 执行时间:Pyannote.audio 约快 2 倍
- 实时应用:改进的分块逻辑提升了准确率
未来工作
- 针对非电话场景调整 Nvidia NeMo 模型
- 将音频上下文集成到 GPT 后处理中
- 优化实时应用的说话人识别阈值
- 探索面向说话人分离任务的领域专用 LLM
7. 参考文献
- NIST Rich Transcription Evaluation (2022)
- Nvidia NeMo Documentation - Speaker Diarization
- Pyannote.audio GitHub Repository
- OpenAI GPT-4 Turbo Documentation
- VoxConverse Speaker Diarization Dataset
致谢
- Akinori Nakajima - VoicePing Corporation 代表董事
- Melnikov Ivan - VoicePing Corporation AI 开发者