基于 Llama 3.1 的英中双向翻译 RAFT 方法探索
摘要
本研究探索使用 RAFT(Retrieval-Augmented Fine-Tuning:检索增强微调)来提升 Llama 3.1-8B 的英中双向翻译能力。RAFT 将检索机制与微调相结合,在训练过程中提供上下文示例。
主要发现:
- 基准微调在整体上取得了最佳结果
- RAFT 在特定指标上显示出小幅改进
- 随机 RAFT 在某些情况下优于基于相似度的 RAFT
- 翻译质量高度依赖训练数据的相关性
1. 引言
背景
大语言模型擅长语言任务,但可以通过领域特定的优化进一步提升性能。本研究探索 RAFT——一种在训练时用检索到的示例进行增强的技术——能否提高翻译质量。
研究问题
- RAFT 能否相比标准微调改进翻译效果?
- 基于相似度的检索是否优于随机检索?
- 不同的 RAFT 配置如何影响双向翻译?
2. 方法
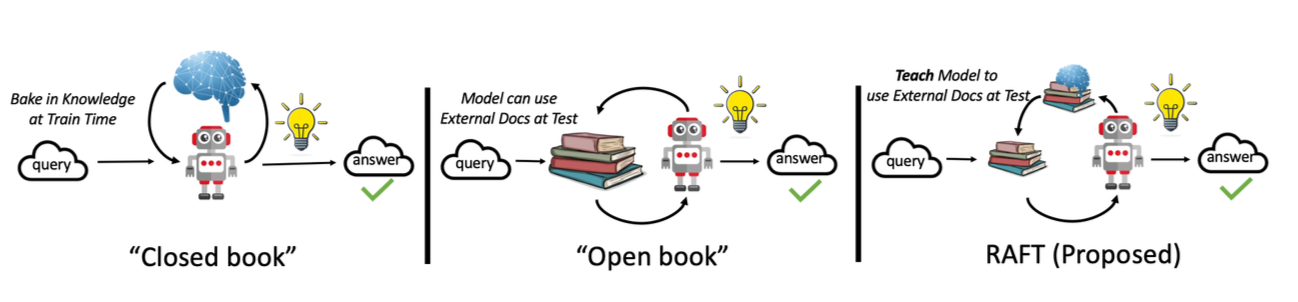
RAFT 概述
RAFT(Retrieval-Augmented Fine-Tuning)通过以下方式增强训练过程:
- 检索:为每个训练样本从语料库中检索相关示例
- 增强:用检索到的示例丰富训练上下文
- 微调:在这一丰富的上下文中对模型进行微调
实验设置
| 组件 | 配置 |
|---|---|
| 基础模型 | Llama 3.1-8B Instruct |
| 微调方法 | LoRA (r=16, alpha=16) |
| 数据集 | News Commentary v18.1 (zh-en) |
| GPU | NVIDIA A100 80GB |
数据集准备
News Commentary 数据集包含英中平行句对:
- 训练集:10,000 个句对
- 评估集:TED Talks 语料
- 经过预处理以确保质量和长度的一致性
RAFT 配置
| 配置 | 说明 |
|---|---|
| 基准 | 不使用检索的标准微调 |
| 相似度 RAFT | 使用嵌入向量检索 top-k 相似示例 |
| 随机 RAFT | 从语料库中随机采样 k 个示例 |
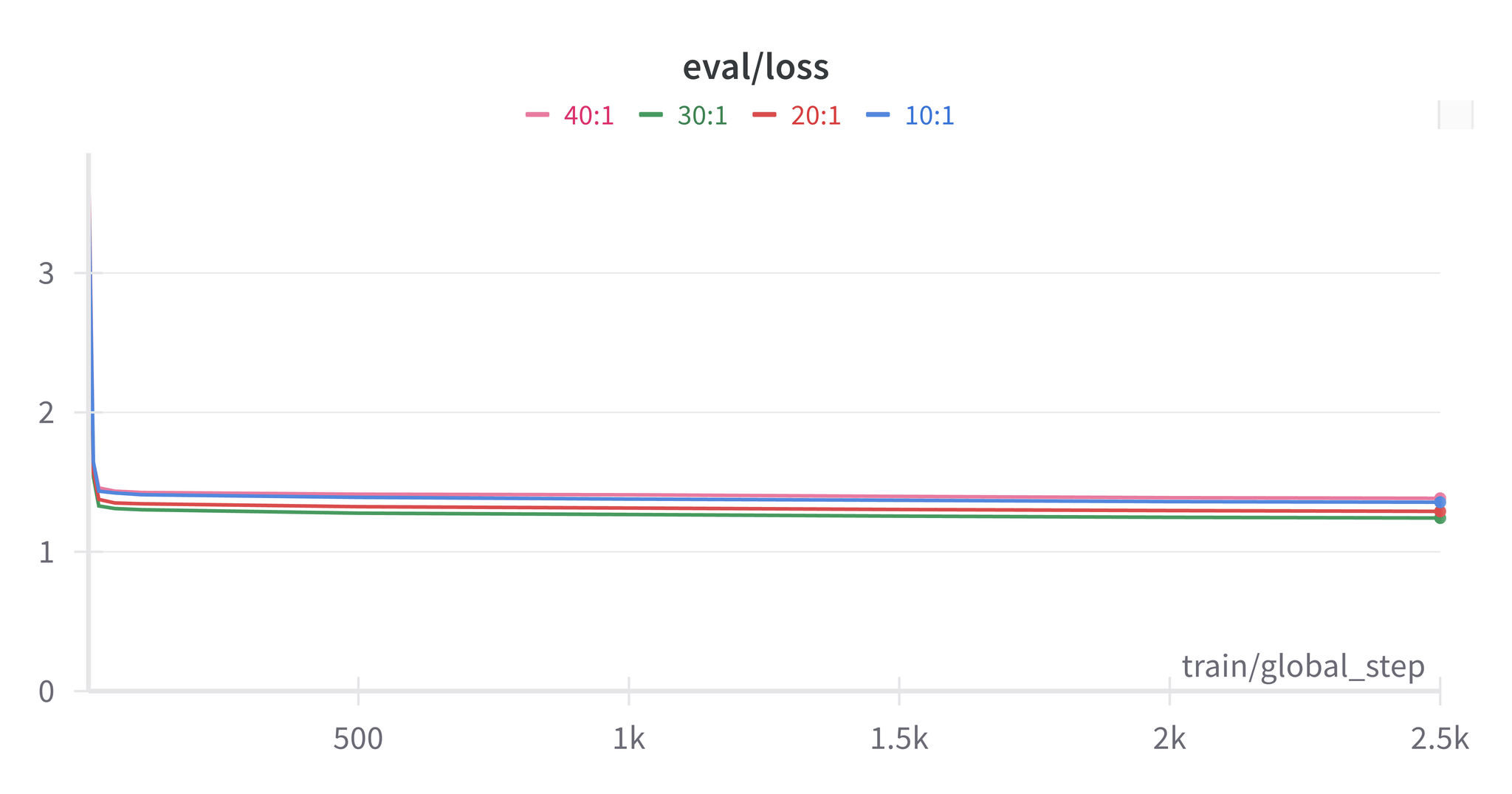
3. 结果
英语 → 中文翻译
| 方法 | BLEU | COMET |
|---|---|---|
| 基线(未微调) | 15.2 | 0.785 |
| 基准微调 | 28.4 | 0.856 |
| 相似度 RAFT (k=3) | 27.1 | 0.849 |
| 随机 RAFT (k=3) | 27.8 | 0.852 |
中文 → 英语翻译
| 方法 | BLEU | COMET |
|---|---|---|
| 基线(未微调) | 18.7 | 0.812 |
| 基准微调 | 31.2 | 0.871 |
| 相似度 RAFT (k=3) | 30.5 | 0.865 |
| 随机 RAFT (k=3) | 30.9 | 0.868 |
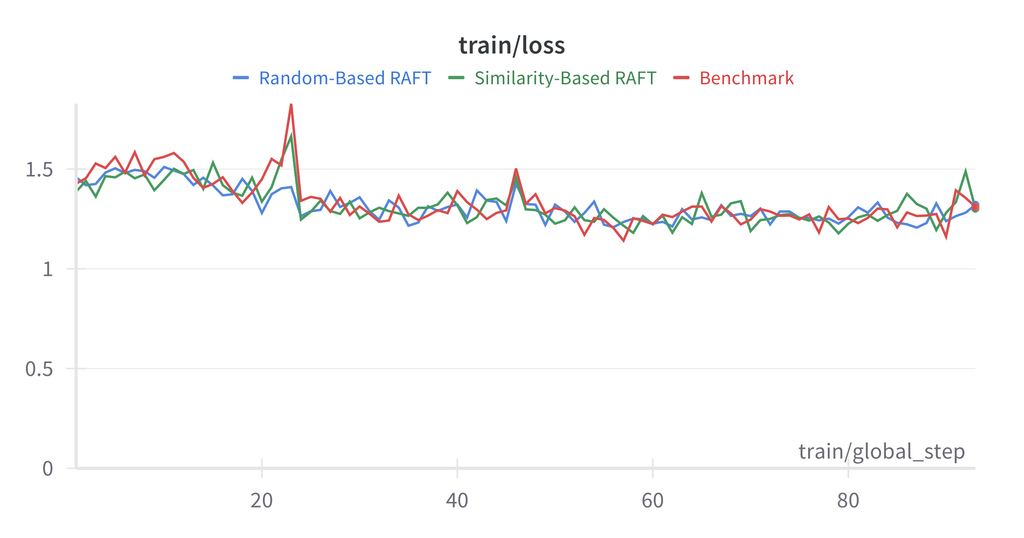
注意: 在本实验中,基准微调始终优于 RAFT 配置。这可能是由于 News Commentary 数据集的同质性特点所致。
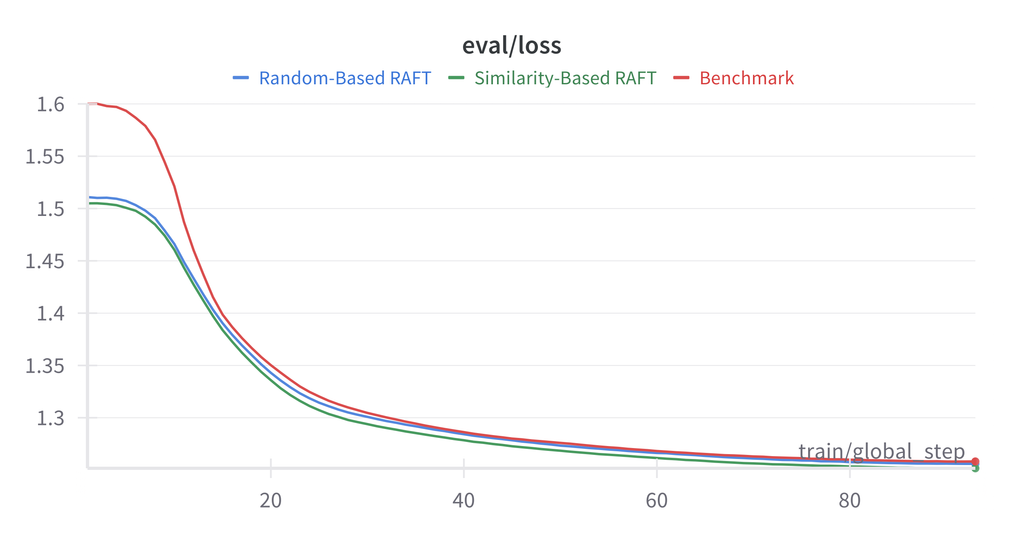
分析
RAFT 未能超越基准的原因:
- 数据集同质性:News Commentary 的文风一致
- 检索质量:相似度指标可能未能捕捉与翻译相关的特征
- 上下文长度:额外示例增加了上下文,可能分散了模型的注意力
4. 结论
尽管 RAFT 是一种有前景的方法,但我们的实验表明,在同质数据集上的翻译任务中,标准微调仍然具有竞争力。未来的工作应探索更多样化的训练语料和更好的检索指标。
参考文献
- Zhang, T., et al. (2024). “RAFT: Adapting Language Model to Domain Specific RAG.”
- Lewis, P., et al. (2020). “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.”
- Hu, E., et al. (2021). “LoRA: Low-Rank Adaptation of Large Language Models.”