开源跨平台移动端完全离线语音翻译应用,集成端侧 ASR(SenseVoice)、神经机器翻译和 TTS,支持 iOS 和 Android 系统音频捕获
源代码:
- ios-android-offline-speech-translation — 集成 ASR、翻译、TTS 和系统音频捕获的 iOS/Android 跨平台离线语音翻译应用(Apache 2.0)
摘要
我们开发了一款开源跨平台移动应用,可在 iOS 和 Android 上实现完全离线的语音翻译。该应用将端侧自动语音识别(SenseVoice Small,通过 sherpa-onnx)、神经机器翻译(Apple Translation / Google ML Kit)和文本语音合成集成为统一管线。两个平台都支持麦克风和系统音频捕获——在平台捕获限制范围内,可以翻译来自其他应用(视频通话、媒体等)的音频,无需云端连接。端侧 ASR 在 iPad Pro(A12X)上达到 23.6 tok/s,在 Samsung Galaxy S10 上达到 33.6 tok/s(RTF < 0.1)。翻译和 TTS 阶段使用平台原生引擎,本次发布未进行单独基准测试。
研究动机
完整的语音翻译管线(ASR、机器翻译、TTS)能否在 2018-2019 年的消费级手机上可靠地离线运行?端侧 AI 研究的基准测试通常单独评估各个模型,但实际应用需要将多个阶段串联起来,在平台沙箱限制下管理系统音频捕获,并处理完整的生命周期(持久化、导出、后台处理)。
本项目验证的是系统可行性:整个管线能否在真实的消费级硬件上不依赖网络连接端到端运行。应用已开源,开发者可以直接评估架构设计。
应用概览
iOS
| 首页 | 转写 + 翻译 | 演示 |
|---|---|---|
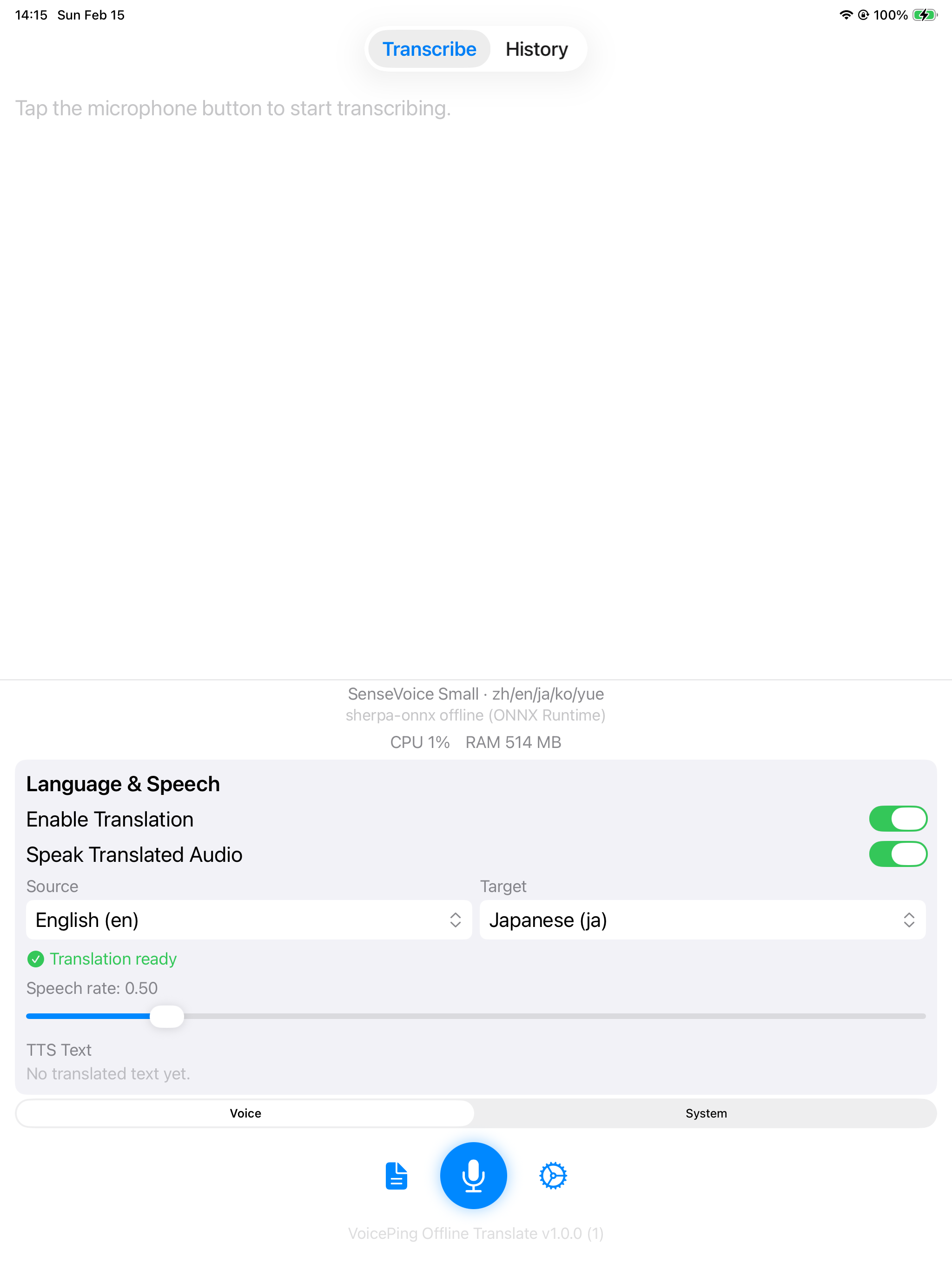 |  | 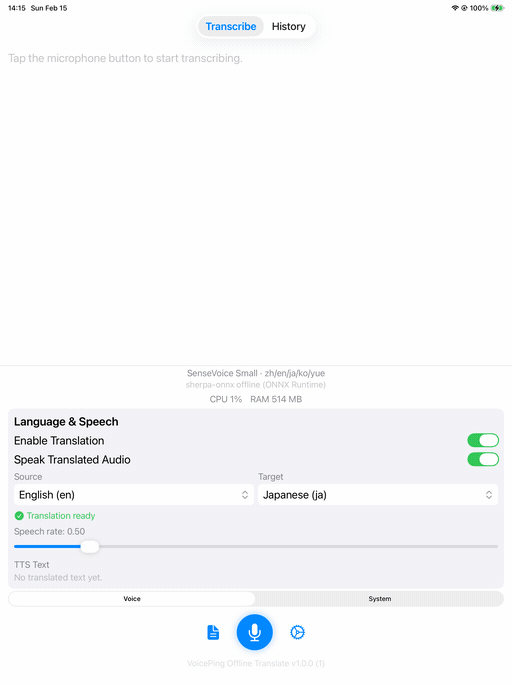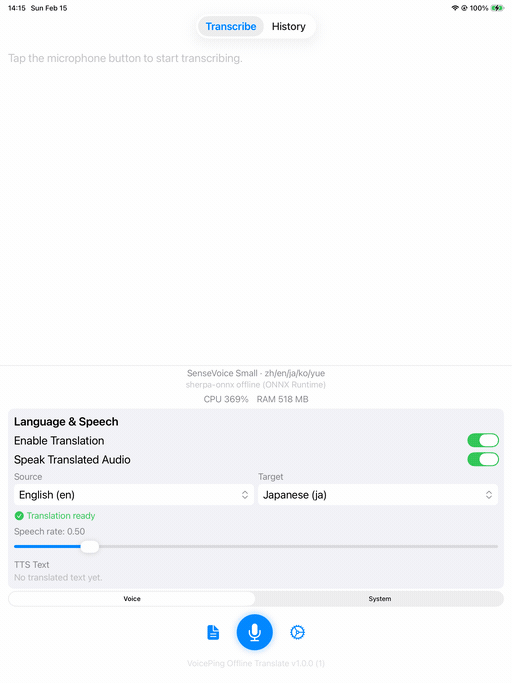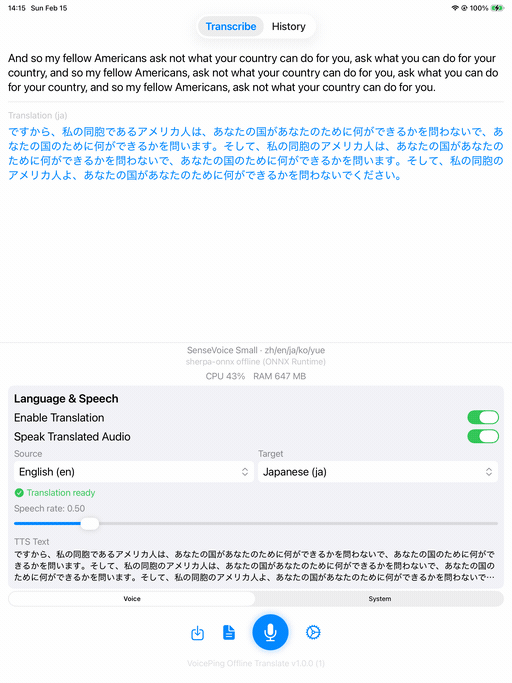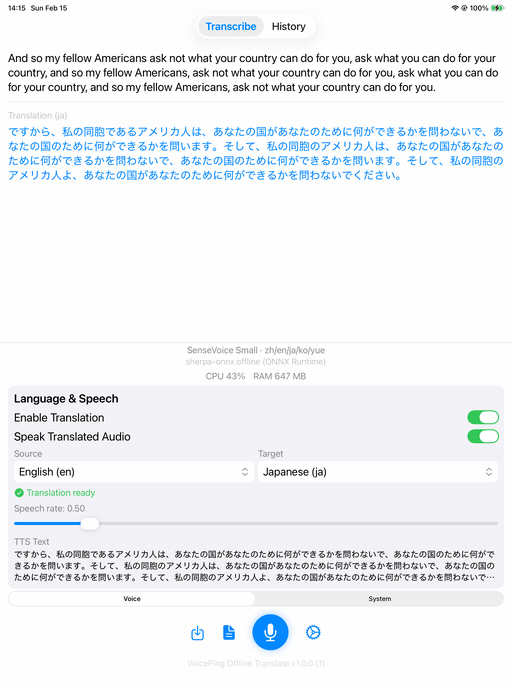 |
SenseVoice Small 搭配 Apple Translation(英语 → 日语)和 TTS。
Android
| 转写 + 翻译 | 演示 |
|---|---|
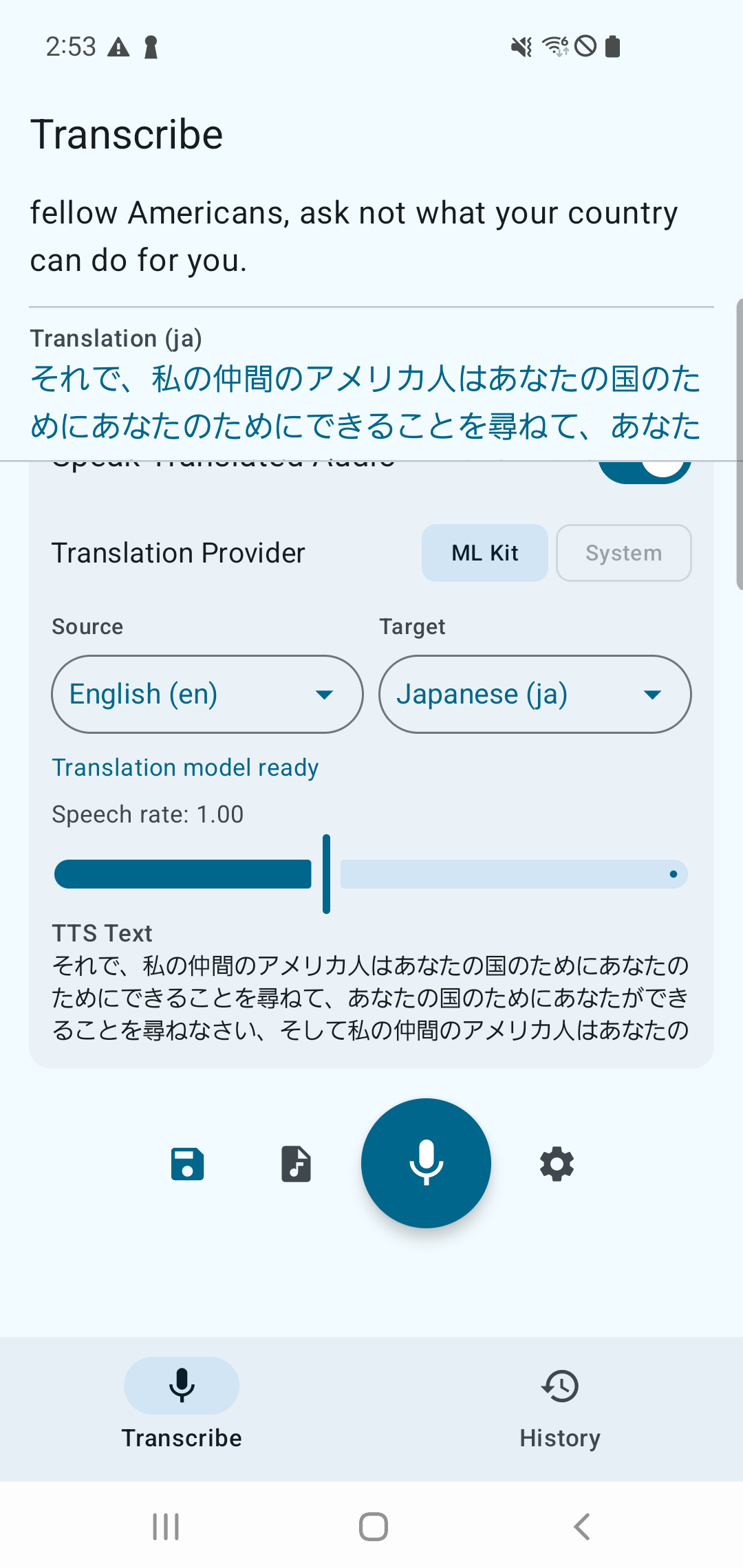 | 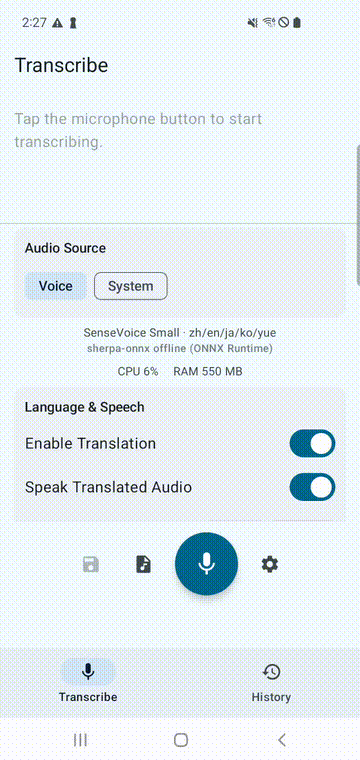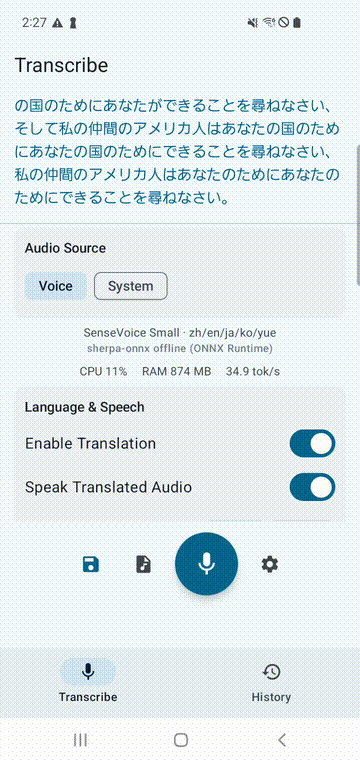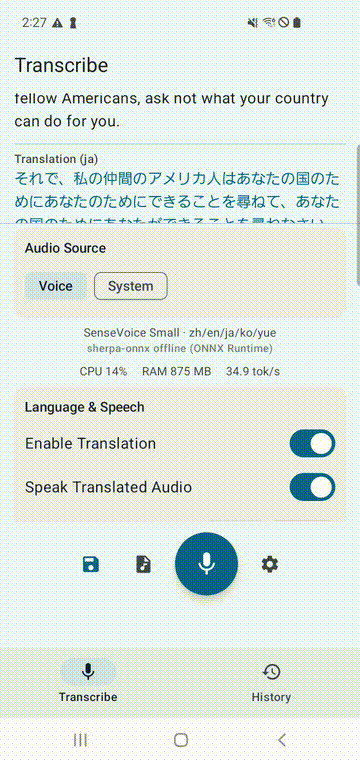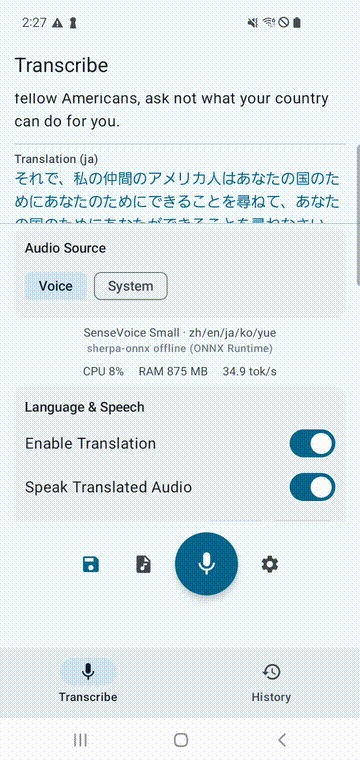 |
SenseVoice Small 搭配 ML Kit 翻译和 TTS。
管线架构
该应用实现了完整的离线语音翻译管线:
| 阶段 | 组件 | 详情 |
|---|---|---|
| 音频输入 | 麦克风 / 系统音频 | 麦克风或系统音频捕获 |
| → ASR | SenseVoice Small | 通过 sherpa-onnx 进行语音转文本(离线) |
| → 翻译 | Apple Translation / Google ML Kit | 神经机器翻译(离线) |
| → TTS | 系统 TTS | AVSpeechSynthesizer (iOS) / Android TextToSpeech |
| 音频输出 | 扬声器 | 播放翻译后的语音 |
每个阶段完全在设备上运行,推理时无需网络连接。
支持的模型
iOS:
| 模型 | 引擎 | 支持语言 |
|---|---|---|
| SenseVoice Small | sherpa-onnx offline | zh/en/ja/ko/yue |
| Apple Speech | SFSpeechRecognizer | 50+ 种语言 |
Android:
| 模型 | 引擎 | 支持语言 |
|---|---|---|
| SenseVoice Small | sherpa-onnx offline | zh/en/ja/ko/yue |
| Android Speech(离线) | SpeechRecognizer(端侧,API 31+) | 系统语言 |
| Android Speech(在线) | SpeechRecognizer(标准) | 系统语言 |
翻译服务
| 平台 | 服务商 | 模式 | 覆盖范围 |
|---|---|---|---|
| iOS | Apple Translation | 离线(iOS 18+) | 20+ 种语言对 |
| Android | Google ML Kit | 离线 | 59 种语言 |
| Android | Android System Translation | 离线(API 31+) | 系统语言 |
TTS
| 平台 | 引擎 |
|---|---|
| iOS | AVSpeechSynthesizer |
| Android | Android TextToSpeech |
音频捕获范围
本应用同时支持麦克风输入和来自其他应用的系统音频捕获(受 DRM 和应用级别退出等平台限制约束)。为使本文聚焦于管线行为和部署结果,此处省略了底层捕获实现细节。iOS 捕获内部原理详见离线转写项目:ios-mac-offline-transcribe。
数据持久化与导出
两个平台均在本地存储转写历史记录,并支持导出:
| 功能 | iOS | Android |
|---|---|---|
| 持久化 | SwiftData (TranscriptionRecord) | Room (TranscriptionEntity, AppDatabase) |
| 音频文件 | SessionFileManager | AudioPlaybackManager |
| 导出 | ZIP 导出 (ZIPExporter) | ZIP 导出 (SessionExporter) |
局限性
- 仅对 ASR 进行了基准测试:只对 ASR 阶段(SenseVoice Small)进行了速度基准测试。翻译和 TTS 阶段使用平台原生引擎,未进行单独测量——端到端管线延迟未知。
- 系统音频捕获限制:部分应用退出了音频捕获,因此"其他应用"的捕获并非通用。
- 仅测试两台设备:结果来自 Galaxy S10(2019)和 iPad Pro 第三代(2018)。其他设备上的性能可能有所不同。
- 未进行精度评估:本次发布未正式测量 ASR 转写准确率(WER)和翻译质量。
未来研究方向
- 端到端延迟分析:分别测量 ASR、翻译和 TTS 各阶段,报告完整管线延迟的百分位数据。
- 质量评估:添加 ASR 的 WER 和常用语言对的翻译质量指标,并进行人工验证。
- 扩大设备范围:在中端及配备 NPU 的新设备上进行基准测试,了解 2018-2026 年硬件的性能变化。
- 后台运行可靠性:对长时间会话、中断以及两个操作系统平台的后台执行策略进行压力测试。
- 功耗与散热:量化持续翻译会话中的电池消耗和热节流情况。
结论
完全离线的语音翻译在当前移动硬件上已切实可行。ASR 阶段(SenseVoice Small)在 2019 年的 Galaxy S10 和 2018 年的 iPad Pro 第三代上达到 23-34 tok/s,RTF < 0.1。翻译和 TTS 使用平台原生引擎(Apple Translation / Google ML Kit 及系统 TTS),未进行单独基准测试——端到端管线延迟取决于语句长度及下游阶段。
系统音频捕获功能使翻译能力从麦克风输入扩展到其他音频源,可以在无云端连接的情况下翻译视频通话、媒体和其他应用的音频。
在网络不稳定或数据隐私至关重要的边缘部署场景中,本架构证明了完整的语音翻译管线可以在消费级硬件上完全端侧部署。该应用以 Apache 2.0 许可证开源,欢迎社区贡献额外模型和基准测试结果。
参考资料
我们的仓库:
- ios-android-offline-speech-translation — 跨平台离线语音翻译应用(Apache 2.0)
ASR 模型:
- SenseVoice Small — 阿里巴巴多语言 ASR 模型(zh/en/ja/ko/yue)
- Parakeet TDT 0.6B v3 — NVIDIA NeMo,25 种欧洲语言
推理引擎:
- sherpa-onnx — Next-gen Kaldi ONNX Runtime(端侧语音处理)
翻译:
- Apple Translation Framework — iOS 18+ 端侧翻译
- Google ML Kit Translation — Android 离线翻译