基于 Llama 3.1 的中英翻译微调及幻觉缓解策略研究
摘要
大语言模型(LLM)在自然语言处理任务中展现出卓越的性能。本研究探索了对 Llama 3.1 进行中译英机器翻译的微调,并通过训练和解码策略来应对幻觉问题。
主要成果:
- 微调模型在文档级数据上达到 BLEU 40.8(基线 19.6)
- COMET 0.891(基线 0.820)
- 成功缓解长上下文翻译中的幻觉现象
- 在提升文档级性能的同时保持了句子级质量
1. 背景
大语言模型
以 Llama 为代表的 LLM 正在革新自然语言处理领域,在理解和生成类人文本方面展现出非凡的能力。由于能够针对特定任务进行微调,LLM 非常适合用于提升机器翻译水平。
参数高效微调(LoRA)
LoRA(Low-Rank Adaptation)能够在不更新全部模型参数的情况下实现微调:
- 冻结预训练模型参数
- 插入可训练的低秩矩阵
- 大幅降低训练成本和时间
神经机器翻译与幻觉
NMT 中的幻觉是指不忠实、虚构或无意义的输出内容:
| 类型 | 说明 |
|---|---|
| 内在幻觉 | 输出包含与原文不符的错误信息 |
| 外在幻觉 | 模型生成与原文无关的额外内容 |
| 扰动幻觉 | 输入轻微变化导致输出截然不同 |
| 自然幻觉 | 源于训练数据集中的噪声 |
解码策略
| 方法 | 说明 |
|---|---|
| 贪心搜索 | 每步选择概率最高的 token |
| 束搜索 | 同时考虑概率最高的 N 个序列 |
| 温度采样 | 调整概率分布的锐度 |
| Top-p 采样 | 从累积概率超过阈值的 token 中采样 |
| Top-k 采样 | 从概率最高的 k 个 token 中采样 |
2. 实验
数据集
| 数据集 | 文档数 | 句子数 | 词数(源/目标) |
|---|---|---|---|
| NewsCommentary-v18.1 | 11,147 | 443,677 | 1,640万/970万 |
| Ted Talks | 22 | 1,949 | 5.1万/3.2万 |
评估指标
- BLEU:Bilingual Evaluation Understudy — 将译文 n-gram 与参考译文进行比较
- COMET:与人工评判相关性最高的神经网络评估框架
实验环境
- 模型:Llama 3.1 8B Instruct
- GPU:NVIDIA A100(80GB)
- 框架:Unsloth 加速训练
微调配置
| |
3. 结果
分布内性能(文档级)
| 训练样本数 | BLEU | COMET |
|---|---|---|
| 10 | 35.8 | 0.885 |
| 100 | 36.9 | 0.889 |
| 1,000 | 39.7 | 0.890 |
| 10,000 | 40.8 | 0.891 |
| 基线 | 19.6 | 0.820 |
要点: 微调使文档级翻译的 BLEU 相比基线提升了 100% 以上。
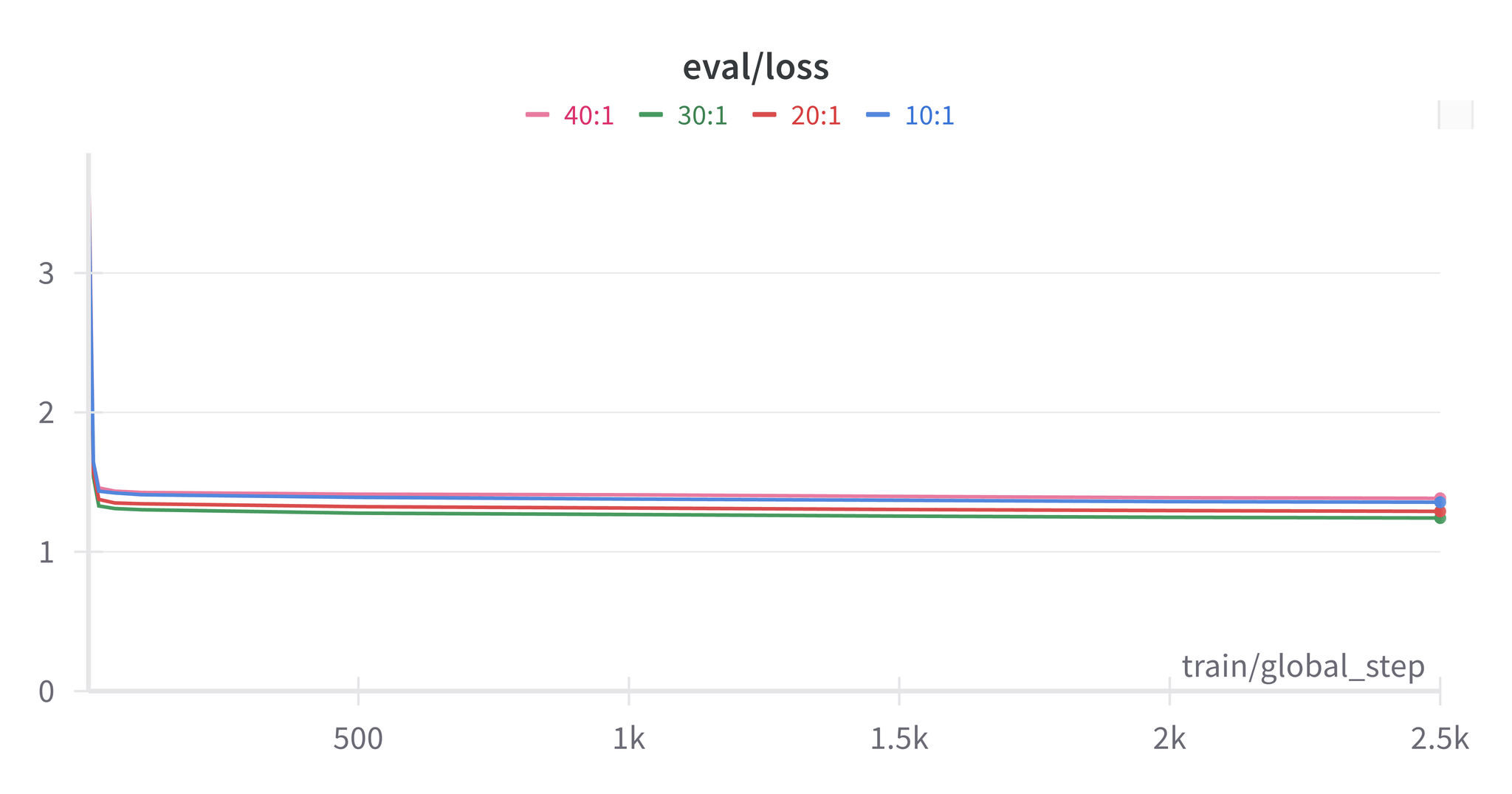
混合训练最终结果
使用句子与文档 30:1 的比例:
| 评估级别 | 微调 BLEU | 微调 COMET | 基线 BLEU | 基线 COMET |
|---|---|---|---|---|
| 文档级 | 37.7 | 0.890 | 19.6 | 0.820 |
| 句子级 | 30.7 | 0.862 | 30.9 | 0.864 |
幻觉分析
观察到的类型:
- 过早停止:模型在翻译完成前生成 EOS token
- 冗余内容:文档级模型生成翻译之外的冗长解释
缓解策略:
- EOS token 概率阈值设定
- 文档级与句子级混合训练
- 精心准备数据集
注意: 经文档级微调的模型倾向于生成包含隐式先验知识的冗长输出,有时会产生事实正确但偏离主题的内容。
4. 结论
通过合理的数据集准备和微调技术,能够实现:
- 翻译质量的显著提升(BLEU 提高2倍)
- 幻觉问题的有效缓解
- 在提升文档级性能的同时保持句子级质量
- 生成更可靠、更连贯的翻译
5. 未来工作
- 准备涵盖多种输入场景的数据集(语言风格、文化背景、对话主题)
- 平衡训练数据中的内容类型以避免偏差
- 通过后处理方法解决命名实体错误
- 探索更多幻觉缓解技术
参考文献
- Kocmi, T., et al. (2022). “Findings of the 2022 conference on machine translation (WMT22).”
- Hu, E., et al. (2021). “LoRA: Low-Rank Adaptation of Large Language Models.”
- Meta AI. (2024). “Llama 3.1 Model Documentation.”
- Ji, Z., et al. (2023). “Survey of Hallucination in Natural Language Generation.”