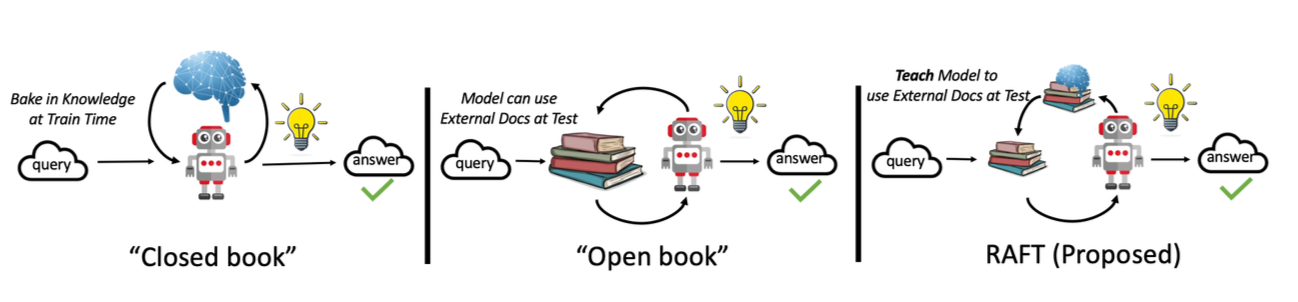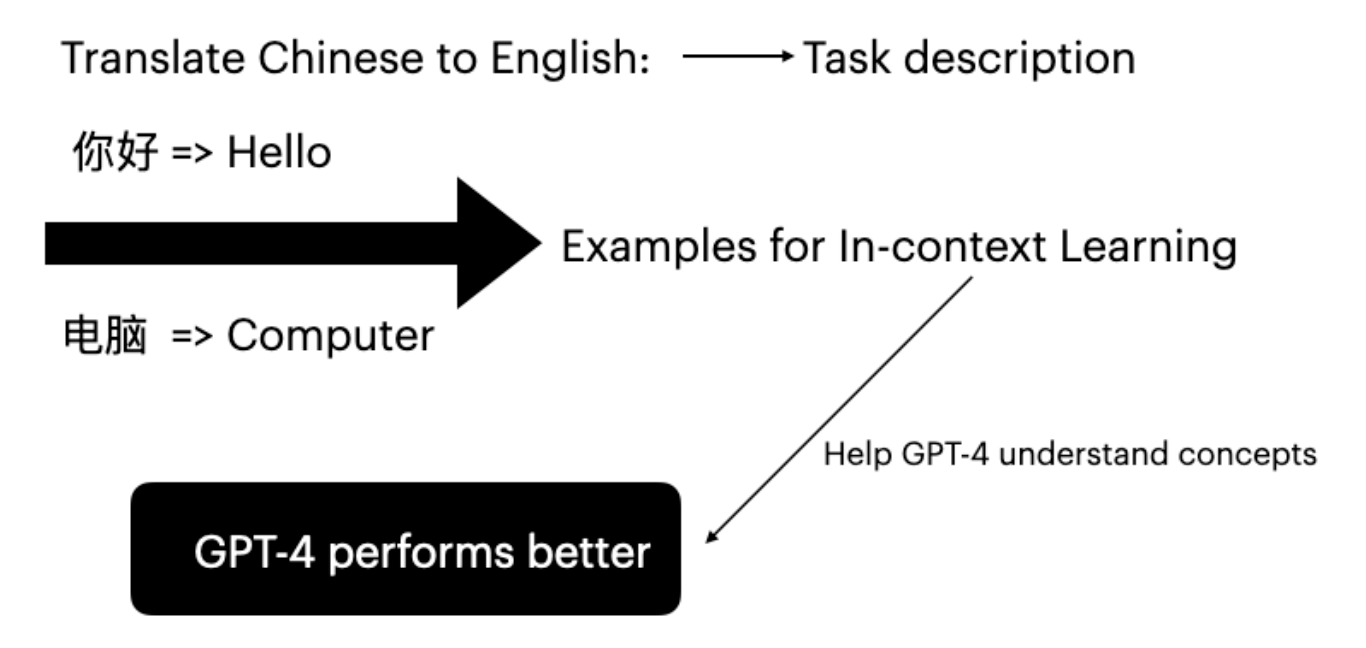
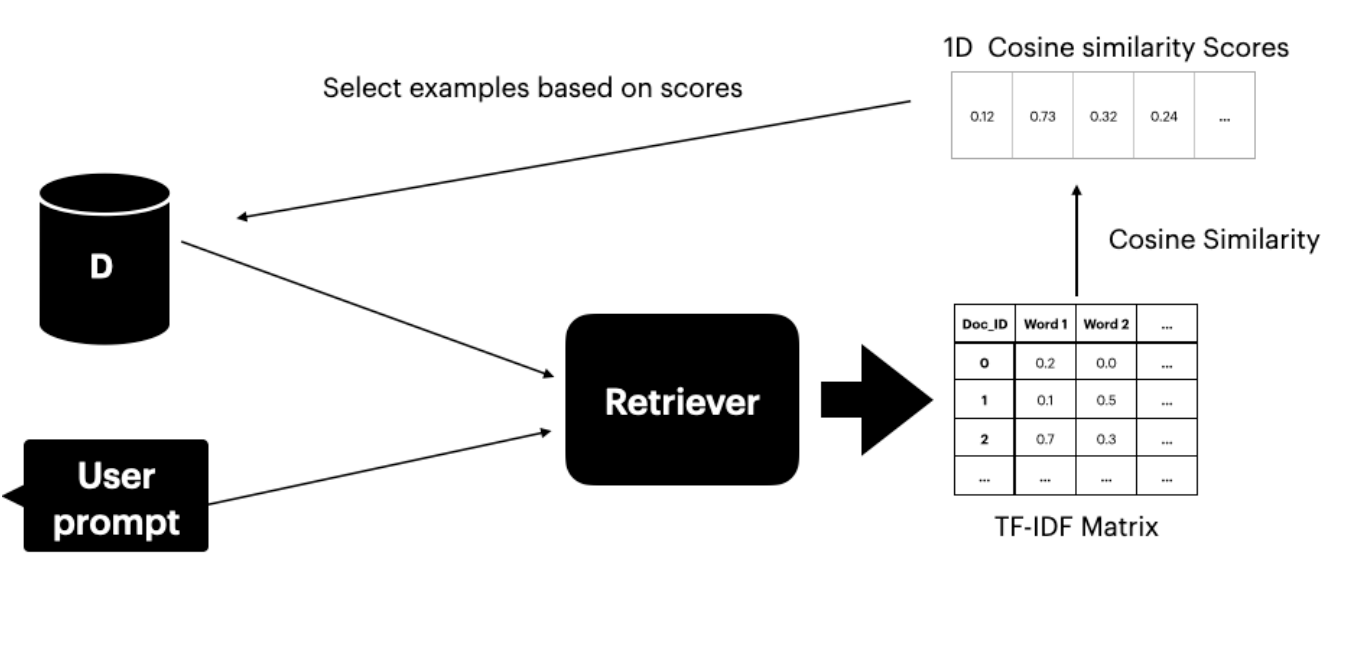
利用 TF-IDF 检索为 GPT-4 翻译提供更优质的 In-Context Learning 示例,从而提升翻译性能的研究报告。
1. 引言
大语言模型(LLM)通过以输入-标签对作为条件,在下游任务中展现出了出色的能力。这种推理方式被称为 In-Context Learning(Brown et al. 2020)。GPT-4 无需微调,仅通过提供特定任务示例即可提升翻译能力。
In-Context Learning 的有效性源于隐式贝叶斯推断(Xie et al. 2022)。随机选择示例无法有效帮助 GPT-4 理解提示的概念。本研究的主要目标是基于用户输入,策略性地选择合适的示例。
2. 方法
本方法假设可以访问包含翻译对的数据集 Ds。文本检索器(Gao 2023)从中定位并选取与用户提示语义最相似的前 K 个句子。
检索器由两个组件构成:
- TF-IDF 矩阵 — 衡量词频和逆文档频率
- 余弦相似度 — 计算 TF-IDF 向量之间的相似度
TF-IDF 分数
TF-IDF 分数衡量词语在文档中的重要程度:
- TF(词频):词语在文档中出现的频率
- IDF(逆文档频率):词语在整个语料库中的重要性
余弦相似度
余弦相似度通过考量两个向量表示之间的夹角来评估相似性。分数越高,表示用户提示与数据集文档之间的相似度越大。
3. 实验设置
3.1 实验流程
实验涵盖三种场景:
- 无 ICL:不使用 In-Context Learning 示例的 GPT-4 翻译
- 随机 ICL:随机选择翻译示例
- 本文方法:TF-IDF 检索器根据相似度分数选取前 4 个示例
评估指标
- BLEU 分数:将翻译片段与参考译文进行对比(Papineni et al. 2002)
- COMET 分数:与人工判断达到最先进相关性的多语言机器翻译评估神经框架(Rei et al. 2020)
3.2 数据集
选择 OPUS-100(Zhang et al. 2020)的原因:
- 包含多样的翻译语言对(ZH-EN、JA-EN、VI-EN)
- 覆盖多种领域,有利于有效的示例选择
配置:
- 每个语言对从 Ds 中取 10,000 个训练实例
- 从测试集的前 100 个句子进行评估
3.3 实现
使用 scikit-learn 的 TfidfVectorizer 和 cosine_similarity 函数:
- 将用户提示与 Ds 合并
- 计算提示与所有句子之间的余弦相似度分数
- 根据相似度选取前 4 个示例
- 将示例嵌入到 GPT-4 提示中

4. 结果与讨论
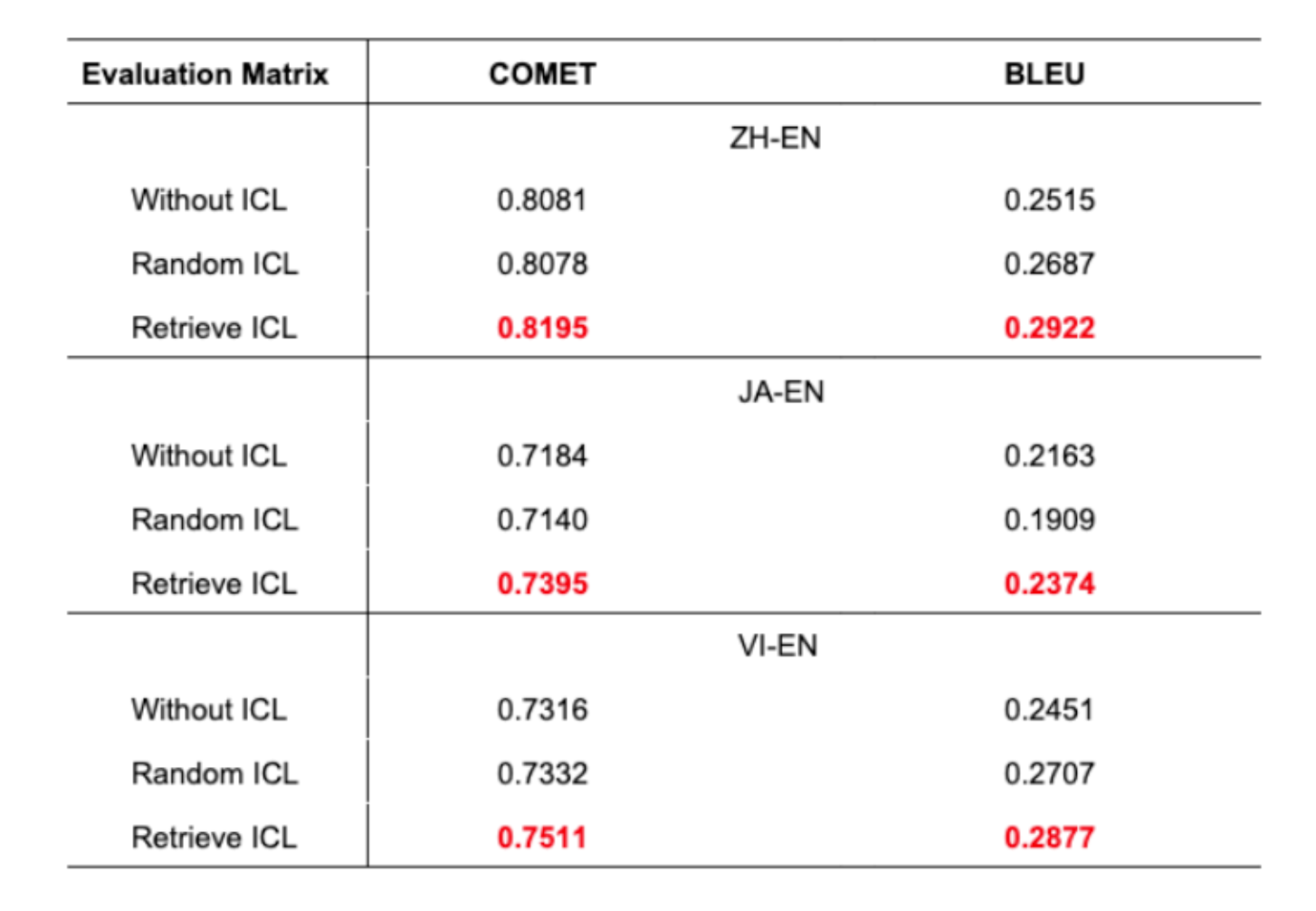
主要发现:
- 本文方法在所有语言对上均展现出更优的翻译准确度
- BLEU 分数提升 1% 在机器翻译中已是有意义的改进
- 随机 ICL 有时甚至不如不使用 ICL
- 这凸显了审慎选择示例的重要性
数据集规模的影响

使用 100 万句的测试证实,更大的 Ds 数据集能够提升 GPT-4 的任务学习效果。
5. 结论与展望
本文提出了一种通过 TF-IDF 检索实现 In-Context Learning 来提升 GPT-4 翻译性能的方法。该方法:
- 利用 TF-IDF 矩阵和余弦相似度构建检索器
- 选取与用户提示高度匹配的句子
- 在 BLEU 和 COMET 分数上均取得了提升
未来研究方向:
- 数据集构建:构建跨领域的高质量综合翻译数据集
- 示例数量:研究使用 5 个或 10 个示例(而非 4 个)时的效果变化
6. 参考文献
- Brown, T., et al. (2020). “Language models are few-shot learners.”
- Xie, S. M., et al. (2022). “An Explanation of In-context Learning as Implicit Bayesian Inference.”
- Bashir, D. (2023). “In-Context Learning, in Context.” The Gradient.
- Das, R., et al. (2021). “Case-based reasoning for natural language queries over knowledge bases.”
- Liu, J., et al. (2022). “What makes good in-context examples for GPT-3?”
- Margatina, K., et al. (2023). “Active learning principles for in-context learning with large language models.”
- Gao, L., et al. (2023). “Ambiguity-Aware In-Context Learning with Large Language Models.”
- Papineni, K., et al. (2002). “BLEU: A method for automatic evaluation of machine translation.”
- Rei, R., et al. (2020). “COMET: A Neural Framework for MT Evaluation.”
- Zhang, B., et al. (2020). “Improving Massively Multilingual Neural Machine Translation and Zero-Shot Translation.”