概述
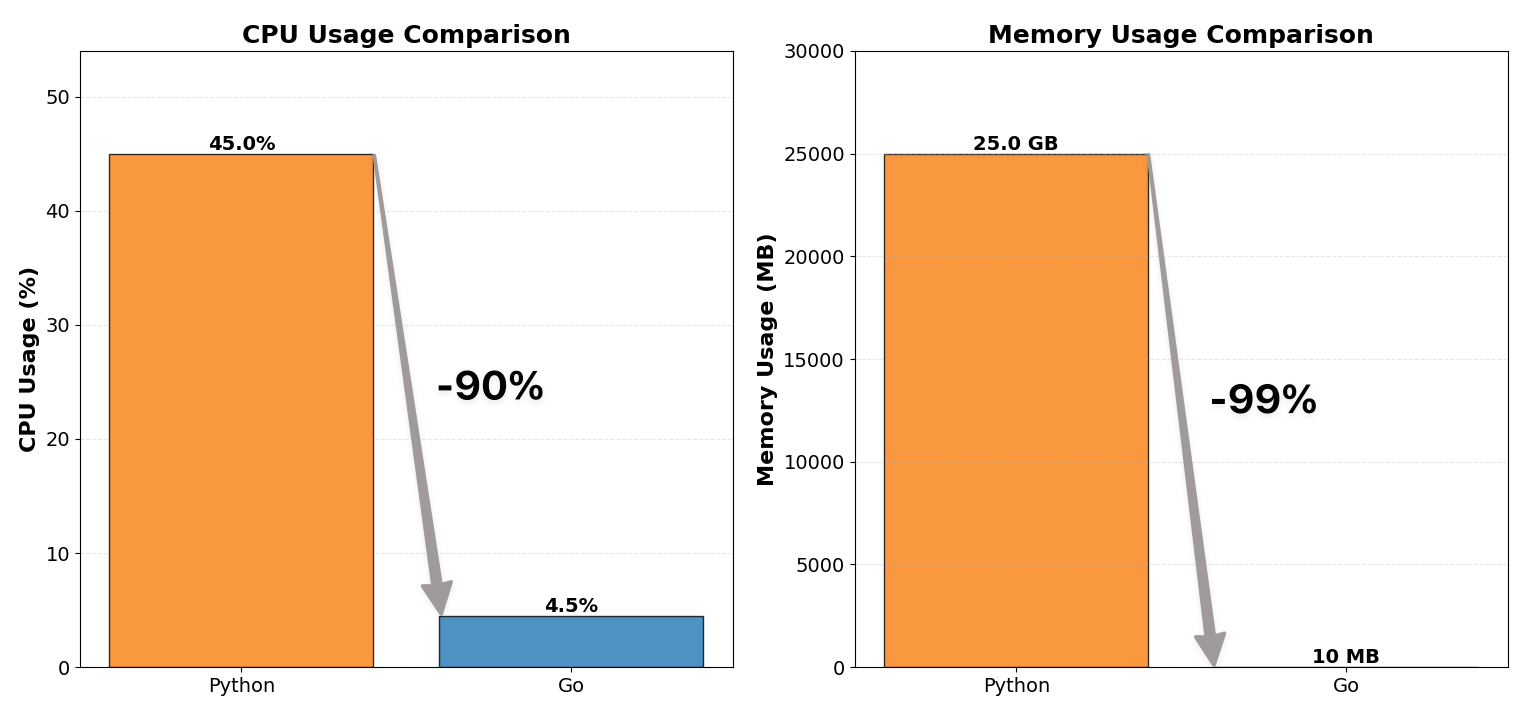
我们将 WebSocket 代理服务器从 Python 重写为 Go,将 CPU 使用率降低到 1/10,内存消耗降低到 1/100。
这个项目不仅提升了资源效率,还让我们学到了一个关于并发的重要经验:
锁越小越好,越少越好。
背景
VoicePing 的系统是一个实时 STT(语音识别)和翻译流水线。每个客户端设备将音频流式传输到后端,进行多语言的语音识别和翻译。
WebSocket 代理服务器位于流水线的中间层:
- 每个客户端与 STT 代理维持一个持久的 WebSocket 会话
- 代理将音频数据包转发到多个 GPU 推理服务器之一
- 等待转录文本并以流式方式返回部分转录结果和翻译
该架构必须以亚秒级延迟处理数千个并发实时音频会话。
然而,我们之前基于 Python 的代理成为了瓶颈。
改进前:Python 代理(低效)
第一版代理服务器使用 Python(FastAPI + asyncio + websockets)实现,通过 Gunicorn 的多工作进程部署。
在小规模下运行正常,但在生产流量下很快达到了资源上限:
| 指标 | Before (Python) | After (Go) |
|---|
| CPU 使用率 | 约 12 核 × 40~50% | 约 12 核 × 4~5% |
| 内存使用量 | 约 25 GB | 约 10 MB |
Python 遇到瓶颈的原因
尽管是异步模式,Python 的架构仍存在多个系统性瓶颈:
单线程事件循环:
asyncio 模型在单线程上多路复用数千个协程。这意味着同一时刻只有一个协程在运行,其余需要等待循环交出控制权。在高 I/O 负载下,这个单一循环成为核心瓶颈,尤其对于读写事件不断发生的 WebSocket 工作负载更为严重。
Gunicorn 多进程:
为利用所有 CPU 核心,我们启动了多个工作进程。每个进程加载完整的 Python 运行时和应用状态,导致内存使用量线性增长。
重量级任务上下文:
每个 WebSocket 连接维护自己的栈帧、Future 和回调,每连接消耗大量内存。
解释器开销:
所有协程在 CPython 解释器内运行,增加了动态类型检查和字节码调度的开销。
因此,系统看起来是并发的,但本质上是顺序执行的。所有协程在同一个事件循环中等待,随着连接数的增加,延迟和 CPU 负载不断放大。
这是不可避免的。Python 的模型根本不适合这种规模的长连接、高吞吐、低延迟 WebSocket 多路复用场景。
于是我们用 Go 进行了重写。
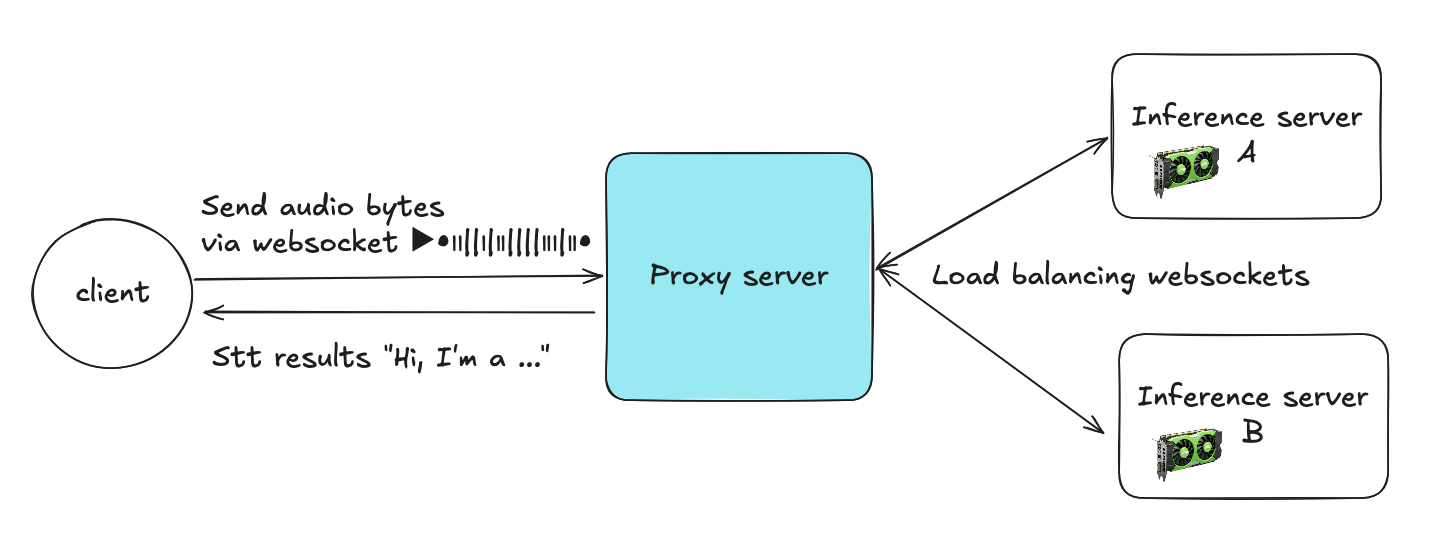
代理服务器全局视图
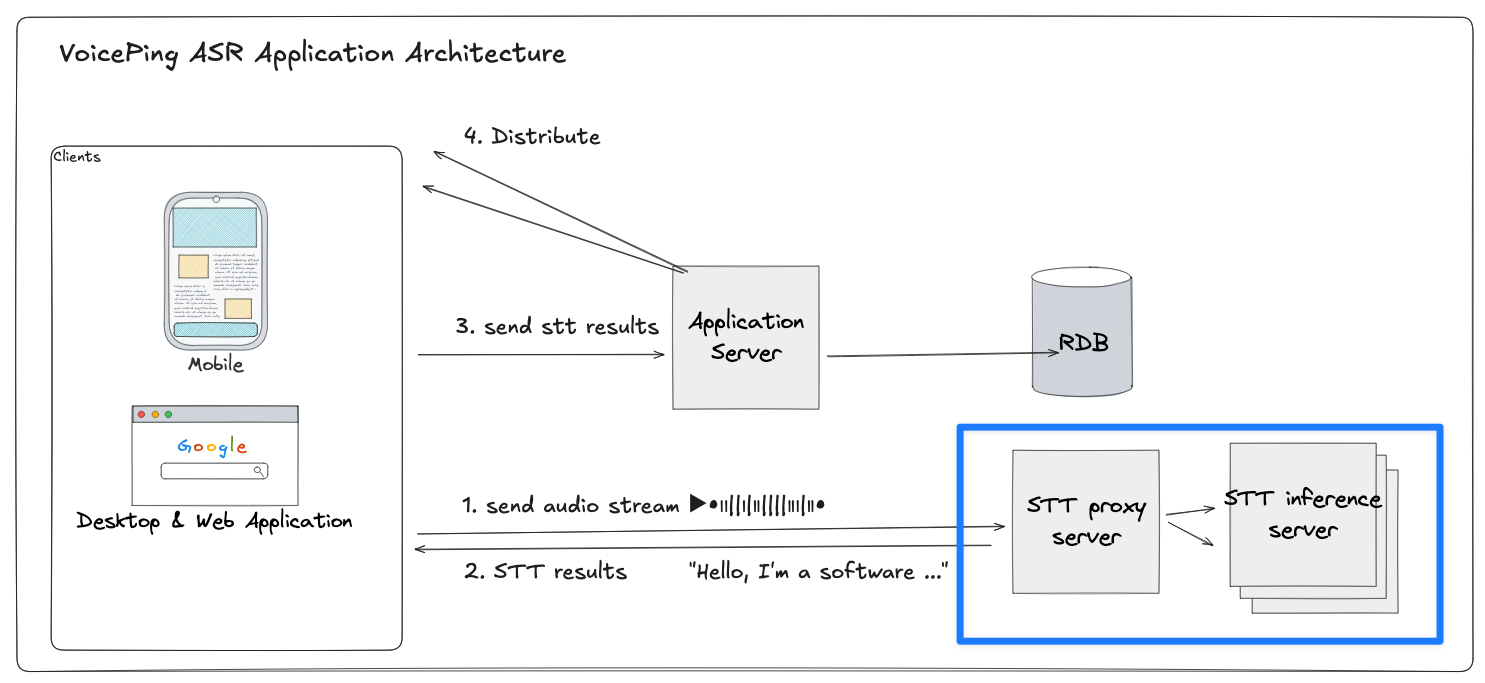
代理服务器作为客户端和多个推理服务器之间的中间层。客户端通过 WebSocket 发送音频字节,代理将每个流路由到多个 STT 推理服务器之一。
客户端 → 代理:
每个客户端打开一个到代理的 WebSocket 连接,持续发送音频块。
代理 → 推理服务器:
代理从 WebSocket 连接池(服务器 A 对应池 A,服务器 B 对应池 B 等,预建的持久后端连接池)中选择一个活跃连接。
流式处理:
代理在整个会话期间维持客户端与选定后端连接之间的映射关系,转发音频数据包并实时返回 STT 结果。
连接复用:
会话结束时(客户端断开连接),代理将后端连接归还到连接池,供其他客户端使用。这种复用机制大幅减少了连接的频繁创建/销毁和资源开销。
代理服务器主要管理两个部分:
- 连接管理器:处理客户端连接的路由和生命周期
- WebSocket 连接池:管理每个推理服务器的可复用后端连接
每个池对应一个推理目标(如 A 或 B),持有一定数量的预建 WebSocket 连接。
这种架构使代理能够:
- 在推理服务器之间高效地负载均衡
- 避免频繁建立连接的开销
连接池管理的功能需求
连接池管理的设计是新代理架构中最关键的部分。池需要高效处理数千个并发 WebSocket 会话,同时保持系统的稳定性和轻量级。
| 需求 | 目的 |
|---|
| 获取可用连接 | 每个传入请求必须在不阻塞其他客户端的情况下快速获得可用的后端连接。确保低延迟和顺畅的负载均衡。 |
| 归还连接到池 | 客户端会话结束后,释放连接使其可供复用。最小化反复开关连接的开销。 |
| 仅保留健康连接 | 定期健康检查移除或重建故障连接。防止不健康连接的积累导致静默故障。 |
| 同步数据库配置 | 从中心数据库定期同步后端连接配置,支持无需重启的动态扩缩容。 |
初始设计(朴素方案)
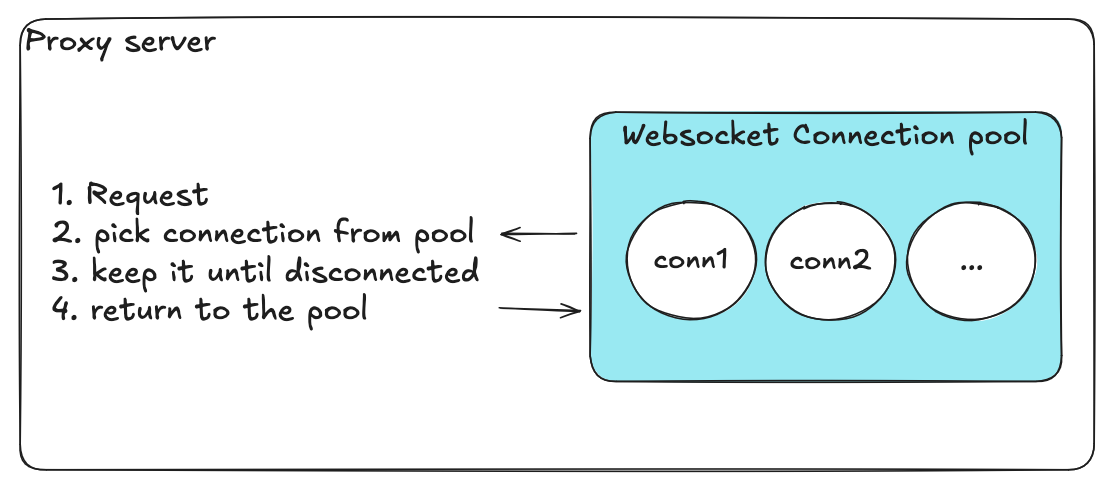
起初我们实现了一个直观但朴素的设计:
- 使用单一数组存放所有连接
- 用布尔标志表示"使用中"/“可用"状态
- 所有操作共用一把全局锁
获取连接的过程:
- 获取锁
- 扫描数组寻找可用连接
- 将其标记为"使用中”
- 释放锁
归还连接的流程类似——获取锁、翻转标志、释放锁。
我们还有一个独立的 goroutine 定期检查数据库配置。该 goroutine 从数据库刷新服务器列表或池大小等后端设置,确保代理始终拥有最新配置而无需重启。
另一个健康检查 goroutine 定期扫描所有连接,移除不健康的连接并在需要时添加新连接。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
| // ────────────────────────────
// FIRST DESIGN (naive, global mutex)
// Single slice + flags, one coarse-grained mutex.
// ────────────────────────────
type Conn struct {
id string
ws *websocket.Conn
inUse bool
healthy bool
}
type Pool struct {
mu sync.Mutex
conns []*Conn
maxSize int
dialURL string
}
// newConn dials a backend and returns a connected *Conn.
// NOTE: In this first design we (incorrectly) call this under the global lock.
func (p *Pool) newConn(ctx context.Context) (*Conn, error) {
d := websocket.Dialer{}
c, _, err := d.DialContext(ctx, p.dialURL, nil)
if err != nil {
return nil, err
}
return &Conn{
id: uuid.NewString(),
ws: c,
inUse: false,
healthy: true,
}, nil
}
// ────────────────────────────
// AdjustPool
// Check capacity vs current size; if not full, fill it.
// BAD PATTERN: holds the global mutex across slow I/O (dial).
// ────────────────────────────
func (p *Pool) AdjustPool(ctx context.Context) error {
p.mu.Lock()
defer p.mu.Unlock()
cur := len(p.conns)
if cur >= p.maxSize {
return nil
}
needed := p.maxSize - cur
for i := 0; i < needed; i++ {
conn, err := p.newConn(ctx)
if err != nil {
return fmt.Errorf("adjust: dial failed: %w", err)
}
p.conns = append(p.conns, conn)
}
return nil
}
// ────────────────────────────
// GetPoolStats
// Return total / in-use / available counts.
// BAD PATTERN: O(n) scan under global lock every call.
// ────────────────────────────
type PoolStats struct {
Total int
InUse int
Available int
Healthy int
Unhealthy int
}
func (p *Pool) GetPoolStats() PoolStats {
p.mu.Lock()
defer p.mu.Unlock()
var inUse, healthy int
for _, c := range p.conns {
if c.inUse {
inUse++
}
if c.healthy {
healthy++
}
}
total := len(p.conns)
return PoolStats{
Total: total,
InUse: inUse,
Available: total - inUse,
Healthy: healthy,
Unhealthy: total - healthy,
}
}
// ────────────────────────────
// HealthCheck
// Ping all connections and mark healthy=false on failures.
// BAD PATTERN: holds global lock during network I/O & mutates in place.
// ────────────────────────────
func (p *Pool) HealthCheck(ctx context.Context, timeout time.Duration) {
p.mu.Lock()
defer p.mu.Unlock()
deadline := time.Now().Add(timeout)
for _, c := range p.conns {
if c.ws == nil {
c.healthy = false
continue
}
if err := c.ws.WriteControl(websocket.PingMessage, []byte("ping"), deadline); err != nil {
c.healthy = false
_ = c.ws.Close()
c.ws = nil
continue
}
c.healthy = true
}
}
|
初始设计的问题
虽然在小规模测试中能正常运行,但初始池化模型在负载下崩溃了。我们观察到:
总数不准确(过冲/欠冲):
并发的获取/归还操作在一把粗粒度锁下修改同一个切片和标志,重试和超时偶尔导致连接被双重归还或丢失,使总数超过上限或池枯竭。
竞态条件导致的并发访问 → 崩溃与状态损坏:
健康检查和指标收集的 goroutine 与请求处理程序争用;长时间的健康检查占用全局锁,而读取方有时观察到半更新的标志,触发 panic 或在有容量的情况下出现"无可用连接"错误。
goroutine 泄漏:
失败的拨号和超时的健康检查并不总是被取消或回收;重试生成新的 goroutine,而旧 goroutine 的引用依然残留。
脆弱的可观测性:
从切片和标志推导的计数器经常与实际状态不符,导致告警噪音大量增加并掩盖真正的事故。
锁竞争与延迟尖峰:
单一锁下的 O(n) 扫描随着并发度的增加而放大尾延迟。
警告: 一句话总结根因:过多的共享状态被一把范围大、持有时间长的锁保护,加上本应独立运行的操作(健康检查/指标收集)争夺同一把锁。
改进后的设计
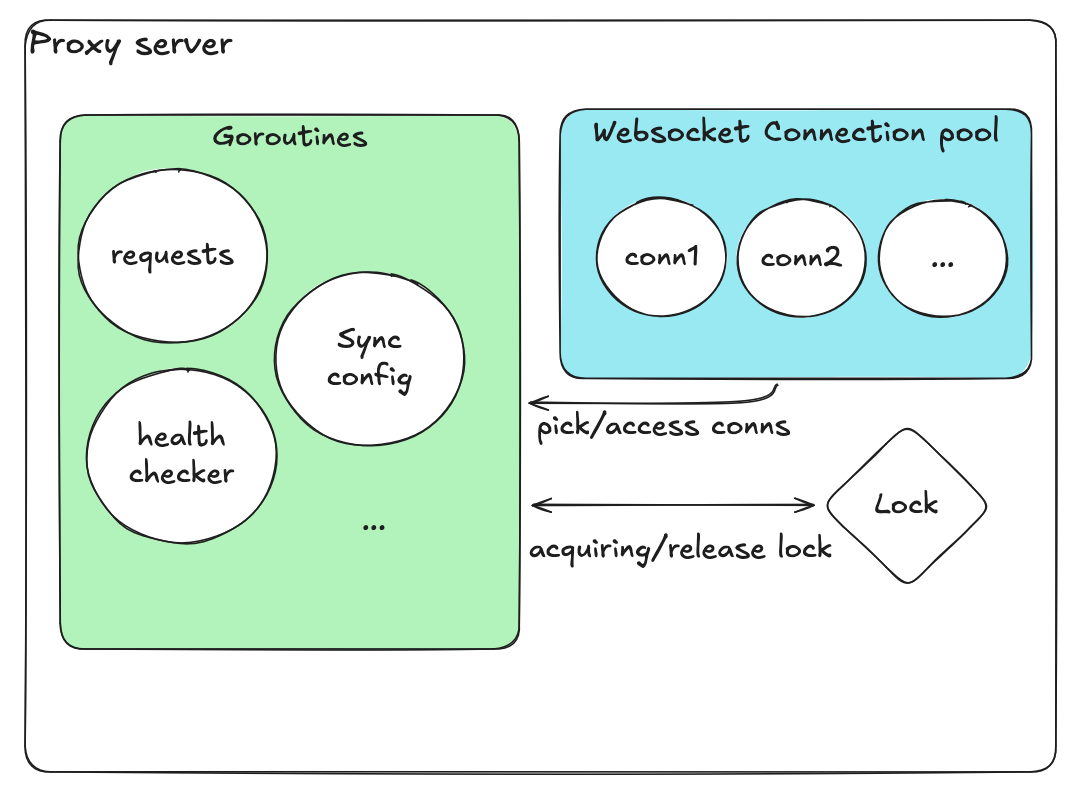
重新设计聚焦于最小化共享状态和职责隔离:
| 组件 | 目的 |
|---|
| 可用连接队列 | 入队/出队自动处理内部锁 |
| 使用中连接的 sync.Map | 无锁并发映射 |
| 原子变量 | 健康标志和计数器 |
| 每连接专用 goroutine | 独立的健康检查 |
每个组件独立运作,没有池级别的锁。锁的数量和范围大幅缩减。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
| package pool
import (
"context"
"errors"
"net/http"
"sync"
"sync/atomic"
"time"
"github.com/google/uuid"
"github.com/gorilla/websocket"
)
// ────────────────────────────
// Conn (a single reusable backend WebSocket connection)
// ────────────────────────────
//
// ✅ GOOD PATTERN:
// - Keep each connection self-contained and concurrent-safe using atomics.
// - Encapsulate health logic inside the Conn itself (no shared state mutation).
// - Avoid external locks and let each conn manage its own goroutine lifecycle.
type Conn struct {
id string
ws *websocket.Conn
healthy atomic.Bool // ✅ lock-free health status flag
lastPing atomic.Int64 // ✅ atomic timestamp for last heartbeat
}
// ✅ GOOD PATTERN: Explicit small helper methods (no external mutation)
func (c *Conn) ID() string { return c.id }
func (c *Conn) IsAlive() bool {
return c.healthy.Load()
}
// ✅ GOOD PATTERN: Safe close, idempotent and isolated
func (c *Conn) Close() error {
if c.ws != nil {
return c.ws.Close()
}
return nil
}
// ✅ GOOD PATTERN: Health loop runs independently per connection
// - No shared/global lock.
// - Non-blocking heartbeat.
// - Fails fast and marks itself dead without blocking pool operations.
func (c *Conn) StartHealthLoop(ctx context.Context, interval time.Duration) {
t := time.NewTicker(interval)
defer t.Stop()
for {
select {
case <-ctx.Done():
return
case <-t.C:
deadline := time.Now().Add(interval / 2)
if err := c.ws.WriteControl(websocket.PingMessage, []byte("ping"), deadline); err != nil {
c.healthy.Store(false)
_ = c.Close()
return
}
c.lastPing.Store(time.Now().UnixNano())
c.healthy.Store(true)
}
}
}
// ────────────────────────────
// ConnPool (fast path only — no dialing, no blocking I/O)
// ────────────────────────────
//
// ✅ GOOD PATTERN:
// - Separate responsibilities: pool only manages available connections.
// - No dialing / blocking I/O under locks.
// - Use channel buffering and atomic counters for concurrency safety.
// - Eliminates coarse-grained global mutex.
type ConnPool struct {
available chan *Conn // ✅ buffered channel for ready conns (lock-free)
inUse sync.Map // ✅ concurrent map for tracking active conns
statsIn atomic.Int64 // ✅ atomic counters (no need for locks)
statsOut atomic.Int64
}
// ✅ GOOD PATTERN: Explicit, fixed-capacity pool construction
func NewConnPool(capacity int) *ConnPool {
return &ConnPool{
available: make(chan *Conn, capacity),
}
}
func (p *ConnPool) Capacity() int { return cap(p.available) }
// ✅ GOOD PATTERN: Non-blocking Acquire
// - Never holds locks while waiting for I/O.
// - Returns instantly if no conn available.
func (p *ConnPool) Acquire(ctx context.Context) (*Conn, error) {
select {
case c := <-p.available:
p.inUse.Store(c.id, c)
p.statsIn.Add(1)
return c, nil
case <-ctx.Done():
return nil, ctx.Err()
default:
return nil, errors.New("no connection available")
}
}
// ✅ GOOD PATTERN: Non-blocking Release
// - Never waits for space in the channel.
// - Drops unhealthy or excess conns immediately.
// - No global mutex.
func (p *ConnPool) Release(c *Conn) {
p.inUse.Delete(c.id)
p.statsOut.Add(1)
if c.IsAlive() {
select {
case p.available <- c:
// ✅ returned to pool safely
default:
// ✅ pool full → discard stale conn safely
_ = c.Close()
}
} else {
// ✅ unhealthy → close immediately
_ = c.Close()
}
}
// ✅ GOOD PATTERN: Offer is used by reconciler (external goroutine)
// - Keeps dialing/repair logic out of hot path.
// - Backpressure-safe with non-blocking insert.
func (p *ConnPool) Offer(c *Conn) bool {
select {
case p.available <- c:
return true
default:
return false
}
}
// ────────────────────────────
// Stats and Metrics
// ────────────────────────────
//
// ✅ GOOD PATTERN:
// - Lock-free snapshot using atomics.
// - Avoids holding locks during metrics collection.
type PoolStats struct {
Capacity int
Available int
InUse int
Acquired int64
Released int64
}
// ✅ GOOD PATTERN: Snapshot safely aggregates pool state without blocking
func (p *ConnPool) Snapshot() PoolStats {
inUseCount := 0
p.inUse.Range(func(_, _ any) bool {
inUseCount++
return true
})
return PoolStats{
Capacity: cap(p.available),
Available: len(p.available),
InUse: inUseCount,
Acquired: p.statsIn.Load(),
Released: p.statsOut.Load(),
}
}
|
要点: 每个组件独立运作,没有池级别的锁。锁的数量和范围大幅缩减。
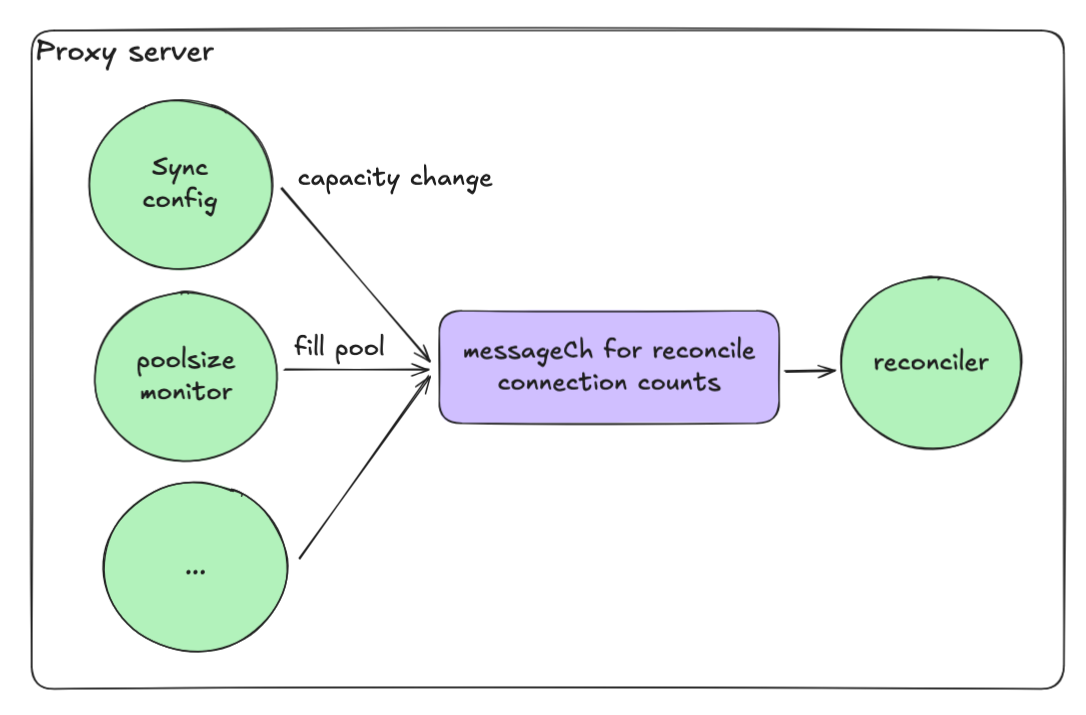
事件驱动的协调机制
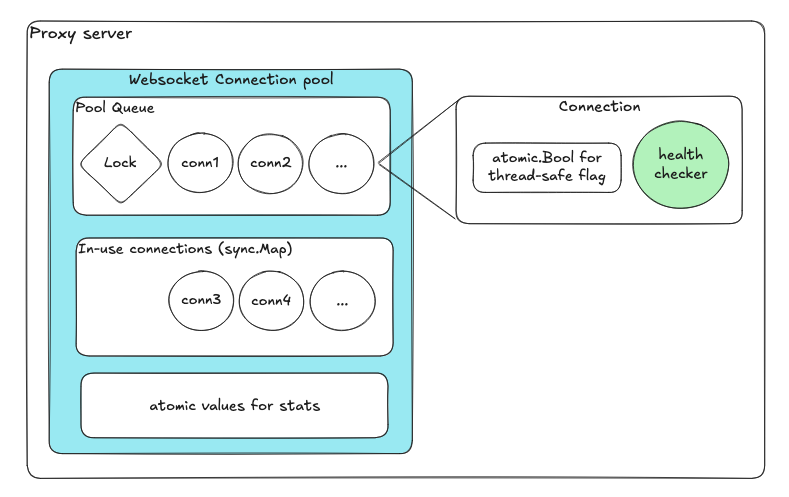
维持合适的池大小也是一个挑战。当连接失败或归还时,协调过程可能并发运行,容易超过最大池大小。
解决方案是一个事件驱动的协调循环:
- 每个操作向通道(messageCh)发送消息
- 协调 goroutine 依次处理这些消息
- 从而确保不会出现竞态条件
这种模型让我们在保持高并发的同时,使系统保持确定性和安全性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
| type ServerConnectionPool struct {
ctx context.Context
cancel context.CancelFunc
reconcileCh chan struct{}
logger *zap.Logger
// ... other fields ...
}
// ✅ GOOD PATTERN: Constructor wires a buffered (size=1) signal channel to enable coalescing.
func NewServerConnectionPool(logger *zap.Logger /* ... */) *ServerConnectionPool {
ctx, cancel := context.WithCancel(context.Background())
return &ServerConnectionPool{
ctx: ctx,
cancel: cancel,
reconcileCh: make(chan struct{}, 1), // ✅ coalescing buffer
logger: logger,
// ... init other fields ...
}
}
// ✅ GOOD PATTERN: Non-blocking signal helper; bursts coalesce into a single pending signal.
func (bp *ServerConnectionPool) trySend(ch chan struct{}) {
select {
case ch <- struct{}{}:
default:
// already queued; coalesced
}
}
// triggerReconcile only *requests* reconciliation; never performs it inline.
// ✅ GOOD PATTERN: no work on the caller's goroutine, prevents stampedes.
func (bp *ServerConnectionPool) triggerReconcile() {
bp.trySend(bp.reconcileCh)
}
// ✅ GOOD PATTERN: Public starter that owns the worker lifecycle.
func (bp *ServerConnectionPool) Start() {
go bp.reconcileWorker()
}
// ✅ GOOD PATTERN: Graceful shutdown.
func (bp *ServerConnectionPool) Stop() {
bp.cancel()
}
// reconcileWorker serializes reconciliation and coalesces bursts.
// ✅ GOOD PATTERN:
// - Single-threaded worker → no concurrent ensureCapacity() runs
// - Periodic safety net with light jitter to avoid thundering herds
// - Drain queue before each run to collapse multiple signals into one
func (bp *ServerConnectionPool) reconcileWorker() {
jitter := func(base time.Duration) time.Duration {
// small ±10% jitter
n := time.Duration(float64(base) * (0.9 + 0.2*rand.Float64()))
return n
}
ticker := time.NewTicker(jitter(5 * time.Second))
defer ticker.Stop()
bp.logger.Debug("Reconciliation worker started", zap.String("pool", bp.GetName()))
defer bp.logger.Debug("Reconciliation worker stopped", zap.String("pool", bp.GetName()))
// Optional: run once immediately on startup
bp.ensureCapacity()
for {
select {
case <-bp.ctx.Done():
return
case <-ticker.C:
// ✅ Periodic reconciliation as a safety net
bp.ensureCapacity()
// reset ticker with jitter to spread load
ticker.Reset(jitter(5 * time.Second))
case <-bp.reconcileCh:
// ✅ Drain any queued signals: burst -> single reconciliation
for {
select {
case <-bp.reconcileCh:
// keep draining
default:
bp.ensureCapacity()
goto CONTINUE
}
}
}
CONTINUE:
}
}
// ensureCapacity is the single authoritative place that:
// 1) Cleans unhealthy queued conns
// 2) Computes current vs target
// 3) Grows or shrinks the pool
// 4) Emits metrics/logs
func (bp *ServerConnectionPool) ensureCapacity() {}
// ────────────────────────────
// Event sources that *request* reconciliation
// ────────────────────────────
// Health watcher: when a server flips health, request reconcile.
// ✅ GOOD PATTERN: do not call ensureCapacity() here; just signal.
func (bp *ServerConnectionPool) startHealthWatcher(healthCh <-chan HealthEvent) {
go func() {
for {
select {
case <-bp.ctx.Done():
return
case ev := <-healthCh:
if ev.Changed {
bp.logger.Debug("health change → reconcile",
zap.String("server", ev.ServerID))
bp.triggerReconcile()
}
}
}
}()
}
// Config watcher: when scale target changes, request reconcile.
// ✅ GOOD PATTERN: apply config change, then signal worker.
func (bp *ServerConnectionPool) startConfigWatcher(cfgCh <-chan ScaleTarget) {
go func() {
for {
select {
case <-bp.ctx.Done():
return
case target := <-cfgCh:
// update internal target state...
bp.logger.Debug("scale target changed → reconcile",
zap.Int("target", target.Connections))
bp.triggerReconcile()
}
}
}()
}
|
核心模式:
- 单线程工作器将协调过程串行化
- 缓冲通道将突发信号合并为单次操作
- 带抖动的周期性安全网防止惊群效应
本地性能测试
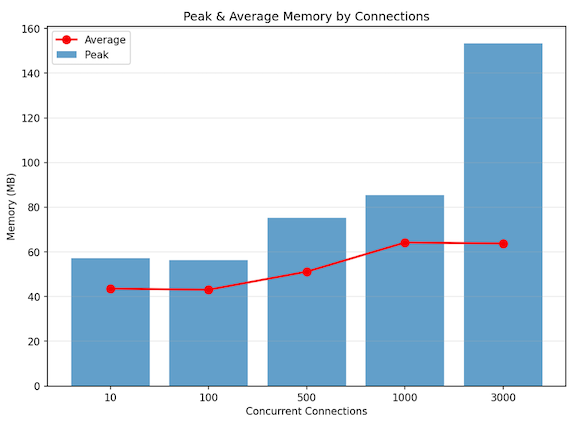
我们通过以下配置在本地验证了性能:
测试配置
| 组件 | 配置 |
|---|
| 代理 | Go 版 WebSocket 代理 |
| 后端 | 3 台 Echo WebSocket 服务器 |
| 负载 | 同时 3,000 个连接(无预热) |
| 流量 | 1 KB 文本消息 @ 每连接 100 条/秒 |
结果
| 指标 | 值 |
|---|
| 并发会话 | 约 3,000(稳定) |
| 吞吐量 | 约 30 万条消息/秒 |
| 峰值内存 | 约 150 MB |
| 平均内存 | 约 60 MB |
| CPU 使用率 | 12 核的约 4~5% |
测试证实代理在全并发连接突发场景下仍能保持平稳的内存占用,验证了连接池隔离和事件驱动协调模型的有效性。
总结
部署新的 Go 版代理后,我们在性能、可扩展性和稳定性方面都观察到了显著改善:
| 类别 | Python (FastAPI + asyncio + Gunicorn) | Go (Goroutines + Channels + Atomics) | 改善幅度 |
|---|
| CPU 使用率 | 约 12 核 × 40~50% | 约 12 核 × 4~5% | 约 90% 降低 |
| 内存使用量 | 约 25 GB | 约 60~150 MB | 约 99% 降低 |
| 可扩展性 | 仅支持数百连接 | 支撑数千连接 | 10 倍扩展 |
Go 重写不仅是语言的更换,更是一次并发模型的根本性变革。
注意: 核心要义:将并发设计为独立、相互通信的进程,而非在保护下的共享可变状态。
这一架构转型使代理能够从数百个扩展到数千个并发 WebSocket 会话,资源使用几乎恒定,同时保持了代码和运维的清晰性。
参考文献
- Go Concurrency Patterns - golang.org/doc/effective_go
- gorilla/websocket - github.com/gorilla/websocket
- Python asyncio Event Loop - docs.python.org