构建用于面部分析、姿态估计和情绪检测的视频预处理流水线的研究报告。
摘要
本项目构建了一个自动化流水线,用于预处理视频和音频数据,为视频生成模型的训练提取关键信息。该流水线涵盖人脸检测、情绪分类、姿态估计和音频处理。
核心功能:
- 自动检测和分离唯一人脸
- 头部姿态估计(yaw、pitch、roll)
- 基于深度学习的情绪分类
- 音频分类与语音分离
- 片段生成(3~10 秒)
1. 引言
随着基于视频的生成模型快速发展,经过良好预处理的视频数据集需求日益增长。本项目自动化了以下视频和音频数据的预处理工作:
- 自动分类和识别唯一人脸
- 沿时间轴检测面部情绪和头部姿态
- 对背景音乐进行音频分类并分离语音
- 裁剪和精炼视频,以供生成模型使用
2. 方法
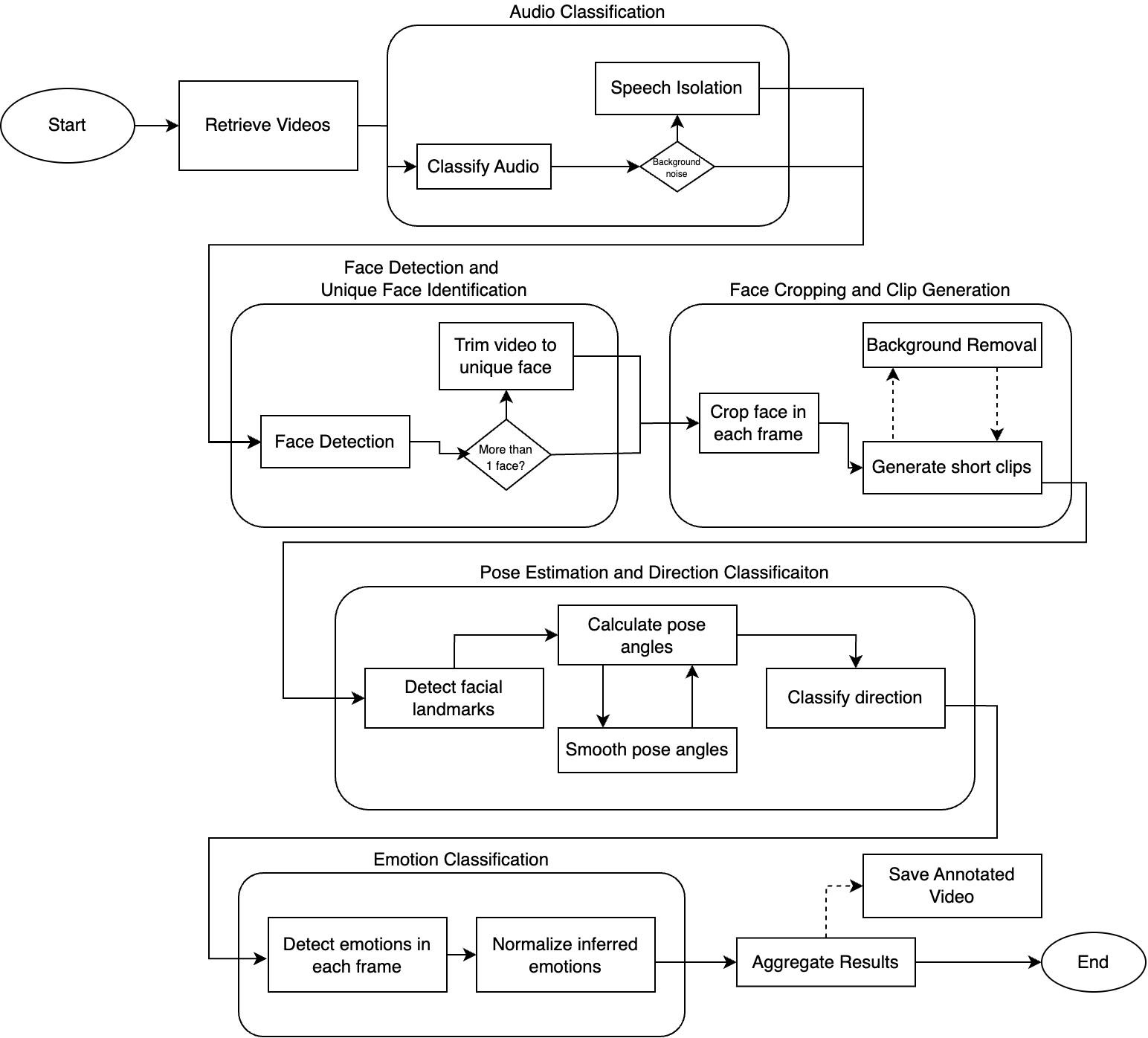
流水线概述
预处理流水线由五个主要阶段组成:
| 阶段 | 功能 |
|---|---|
| 音频分类 | 识别语音并从背景噪声中分离 |
| 人脸检测 | 检测和识别视频中的唯一人脸 |
| 人脸裁剪 | 生成以人脸为中心的片段(3~10 秒) |
| 姿态估计 | 估计头部方向(yaw、pitch、roll) |
| 情绪分类 | 在每一帧中检测情绪 |
2.1 视频处理
使用 yt-dlp 下载视频,逐帧处理:
| |
2.2 音频分类
使用 Audio Spectrogram Transformer 模型对音频进行分类:
- 将音频转换为频谱图
- 使用 Vision Transformer 进行分类
- 背景噪声检测阈值约为 20%
示例结果:
| 视频类型 | 语音 % | 音乐 % |
|---|---|---|
| 带音乐的解说 | 50.28% | 37.20% |
| 现场演出 | 1.50% | 46.54% |
| 新闻采访 | 82.64% | 0% |
2.3 人脸检测与裁剪
使用 YuNet 人脸检测模型:
- 在每一帧中检测所有人脸
- 选择最大的人脸作为目标
- 裁剪并调整为统一尺寸
- 生成 3~10 秒的片段
注意: 使用 rembg 进行可选的背景去除,可以进一步分离目标对象。
2.4 姿态估计
使用 68 个面部关键点估计头部姿态:
- Yaw:左右旋转(超过 10 度表示朝右/朝左)
- Pitch:上下旋转(超过 10 度表示朝上/朝下)
- Roll:头部倾斜
姿态值通过连续帧的缓冲区进行平滑处理。
2.5 情绪分类
使用 Hugging Face 的 facial_emotions_image_detection:
- 可检测的情绪:快乐、悲伤、愤怒、中性、恐惧、厌恶、惊讶
- 分数归一化为总和 100%
- 在整个视频范围内取平均值作为汇总
3. 结果
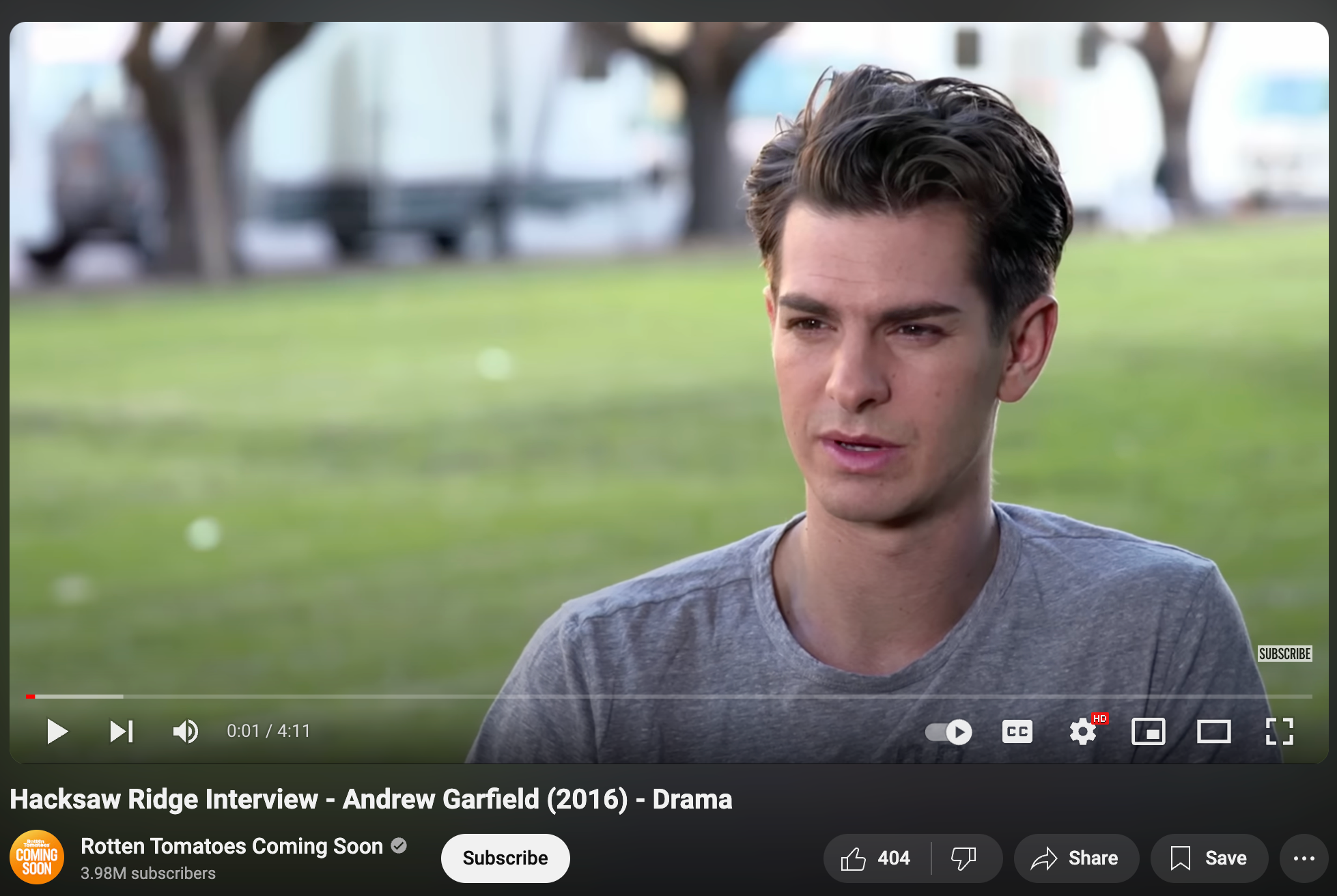
视频分析示例
测试视频:“Hacksaw Ridge Interview - Andrew Garfield”(4 分 11 秒)
| 指标 | 值 |
|---|---|
| 总帧数 | 6,024 |
| FPS | 23.97 |
| 人脸检测率 | 98.26% |
| 每帧平均人脸数 | 1.0 |
| 生成的片段数 | 26 |
音频分类
Speech: 88.89%
Rustling leaves: 1.12%
Rustle: 0.74%
由于语音置信度较高,无需进行语音分离。
姿态估计示例
正面朝向片段:
- Yaw: 0.65°, Pitch: 4.07°
- 方向:“Forward”

右侧朝向片段:
- Yaw: 10.36°, Pitch: -1.22°
- 方向:“Right”

情绪分类
模型在各种情绪之间表现出不确定性,最高概率约为 25%。这反映了从静态面部图像进行情绪检测的复杂性。
4. 未来方向
- 更多分类功能:唇语识别、手势检测
- GPU 加速:由于资源限制,目前仅使用 CPU
- 微调模型:针对特定任务的定制模型
- 高级情绪检测:超越静态图像的多模态方法
参考文献
- 1adrianb/face-alignment - 2D 和 3D 人脸对齐库
- ageitgey/face_recognition - Python 人脸识别 API
- CelebV-HQ - 大规模视频面部属性数据集
- danielgatis/rembg - 背景去除工具
- dima806/facial_emotions_image_detection - Hugging Face
- facebookresearch/demucs - 音乐源分离
- MIT/ast-finetuned-audioset - Audio Spectrogram Transformer