在 6 个真实场景中对 NeMo MSDD 和 Pyannote 3.1 进行技术对比评估的研究报告。
测试配置:6 个场景,5 种语言(EN、JA、KO、VI、ZH),3 个模型 硬件:NVIDIA GeForce RTX 4090 日期:2025年12月
摘要
我们在 6 个场景中评估了 3 个说话人分离模型:
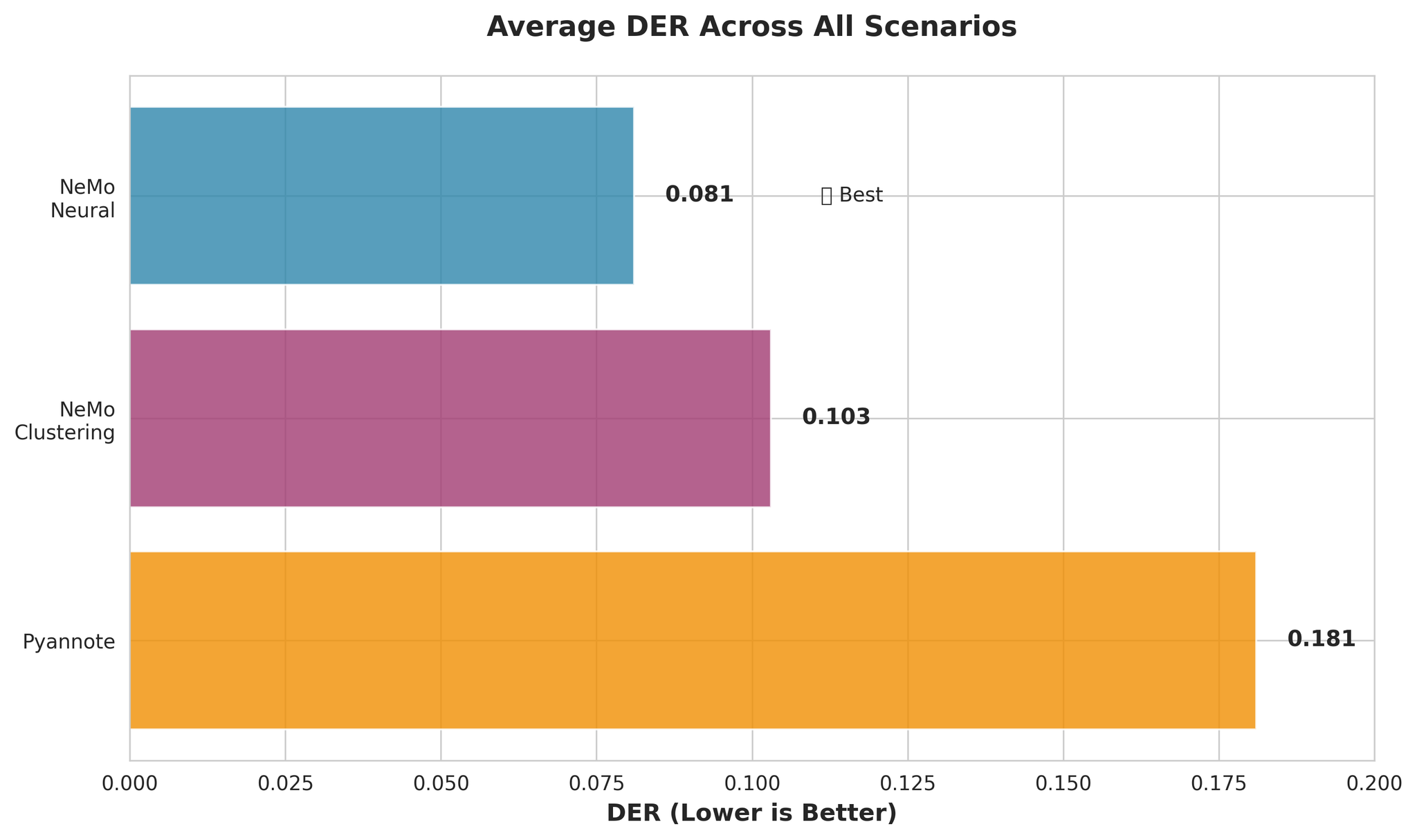
| 模型 | 说明 | 平均 DER | 平均 RTF |
|---|---|---|---|
| NeMo Neural (MSDD) | 带神经网络精炼的多尺度分离解码器 | 0.081 | 0.020 |
| NeMo Clustering | 不含 MSDD 的纯聚类方法 | 0.103 | 0.010 |
| Pyannote 3.1 | 端到端分离流水线 | 0.181 | 0.027 |
核心发现:
- NeMo Neural 兼具最佳准确度和快速处理能力
- 日语在较长上下文中表现改善:30分钟以上音频性能提升
- 不含日语的多语言处理表现优异(DER: 0.050)
1. 引言
为了选择生产环境中使用的分离模型,我们设计了 6 个反映实际运行条件的测试场景:
- 不同音频时长(10分钟至1小时)
- 不同说话人数(4至14人)
- 不同重叠程度(0%至40%)
- 多语言音频混合
2. 测试模型
NeMo Neural (MSDD)
- 使用 TitaNet-large 生成 192 维说话人嵌入
- 在 5 个时间尺度(1.0秒~3.0秒窗口)上处理音频
- MSDD 神经网络对初始聚类结果进行精炼
- 平均 RTF:约 0.015~0.032
NeMo Clustering(纯聚类)
- 使用相同的嵌入模型(TitaNet-large)
- 仅使用谱聚类,不含 MSDD 精炼
- 跳过神经网络精炼,速度显著更快
- 平均 RTF:约 0.014~0.028
Pyannote 3.1
- 包含 VAD、分割和聚类的端到端流水线
- 使用 pyannote/segmentation-3.0 和 wespeaker 模型
- 平均 RTF:约 0.018~0.043
3. 评估设置
3.1 测试场景
| 场景 | 时长 | 说话人数 | 重叠率 | 目的 |
|---|---|---|---|---|
| 长音频 | 10分钟 | 4~5 | 15% | 标准生产场景 |
| 超长音频 | 30分钟 | 10~12 | 15% | 压力测试 |
| 1小时音频 | 60分钟 | 12~14 | 15% | 极限时长测试 |
| 高重叠 | 15分钟 | 8~10 | 40% | 最差重叠场景 |
| 多语言(5种) | 15分钟 | 8 | 20% | EN+JA+KO+VI+ZH |
| 多语言(4种) | 15分钟 | 8 | 20% | EN+KO+VI+ZH(无日语) |
3.2 评估指标
准确度指标:
- DER Full(collar=0.0秒):最严格指标,无边界容差
- DER Fair(collar=0.25秒):主要指标,250ms容差
- DER Forgiving(collar=0.25秒,忽略重叠):最宽松
DER 组成:
- 漏检率:系统遗漏的语音
- 误检率:非语音被标记为语音
- 混淆率:语音被分配给错误的说话人
4. 总体性能
4.1 准确度对比
主要观察:
- NeMo Neural 比 Pyannote 准确约 55%(DER: 0.081 vs 0.181)
- NeMo Clustering 与 Neural 接近(仅差 27%)
- Pyannote 的混淆率高出 3.4 倍
4.2 处理速度对比
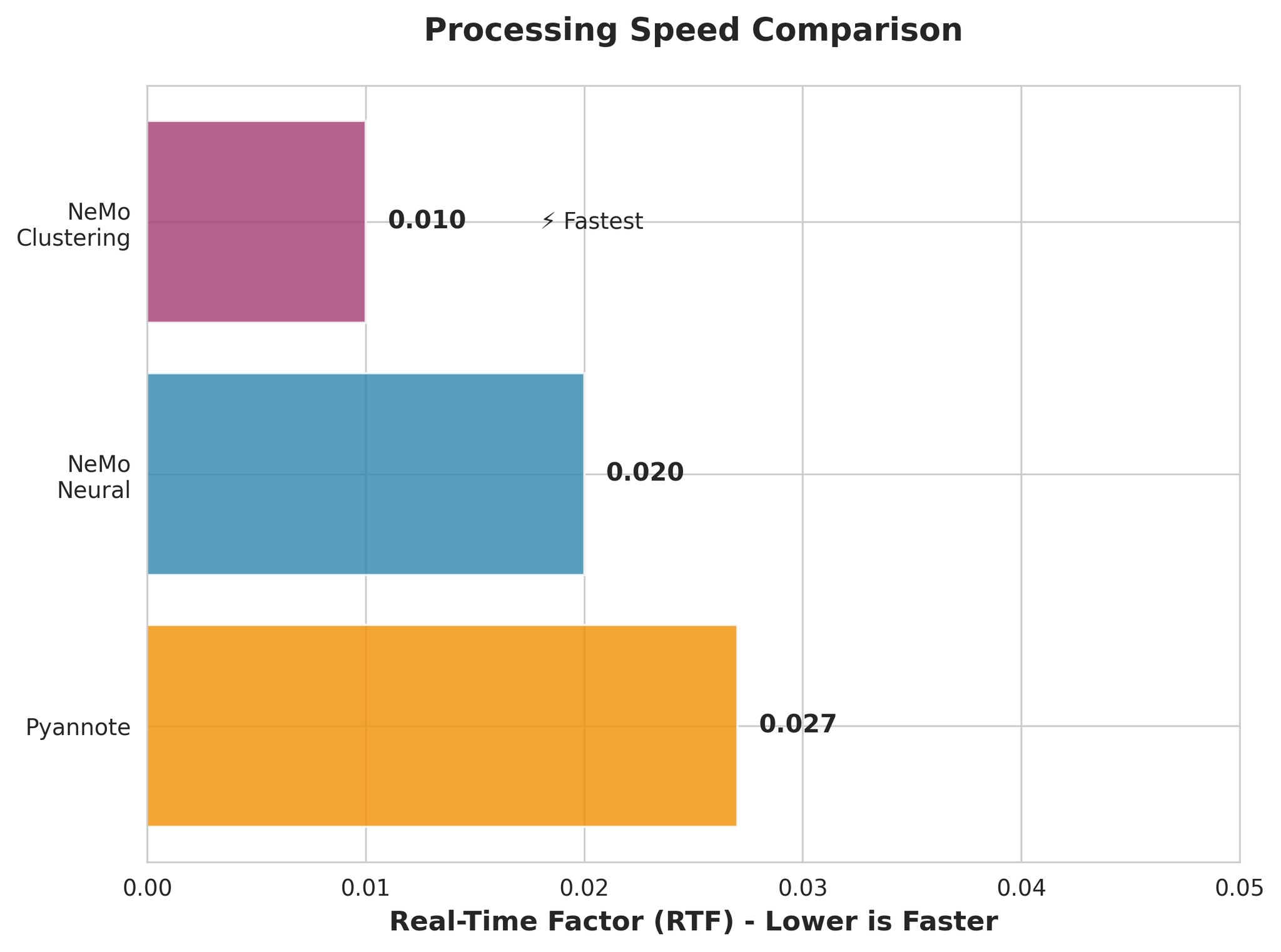
- NeMo Clustering 最快(RTF 0.010)
- NeMo Neural 也非常快(RTF 0.020)
- 所有模型都远快于实时处理
4.3 准确度与速度权衡
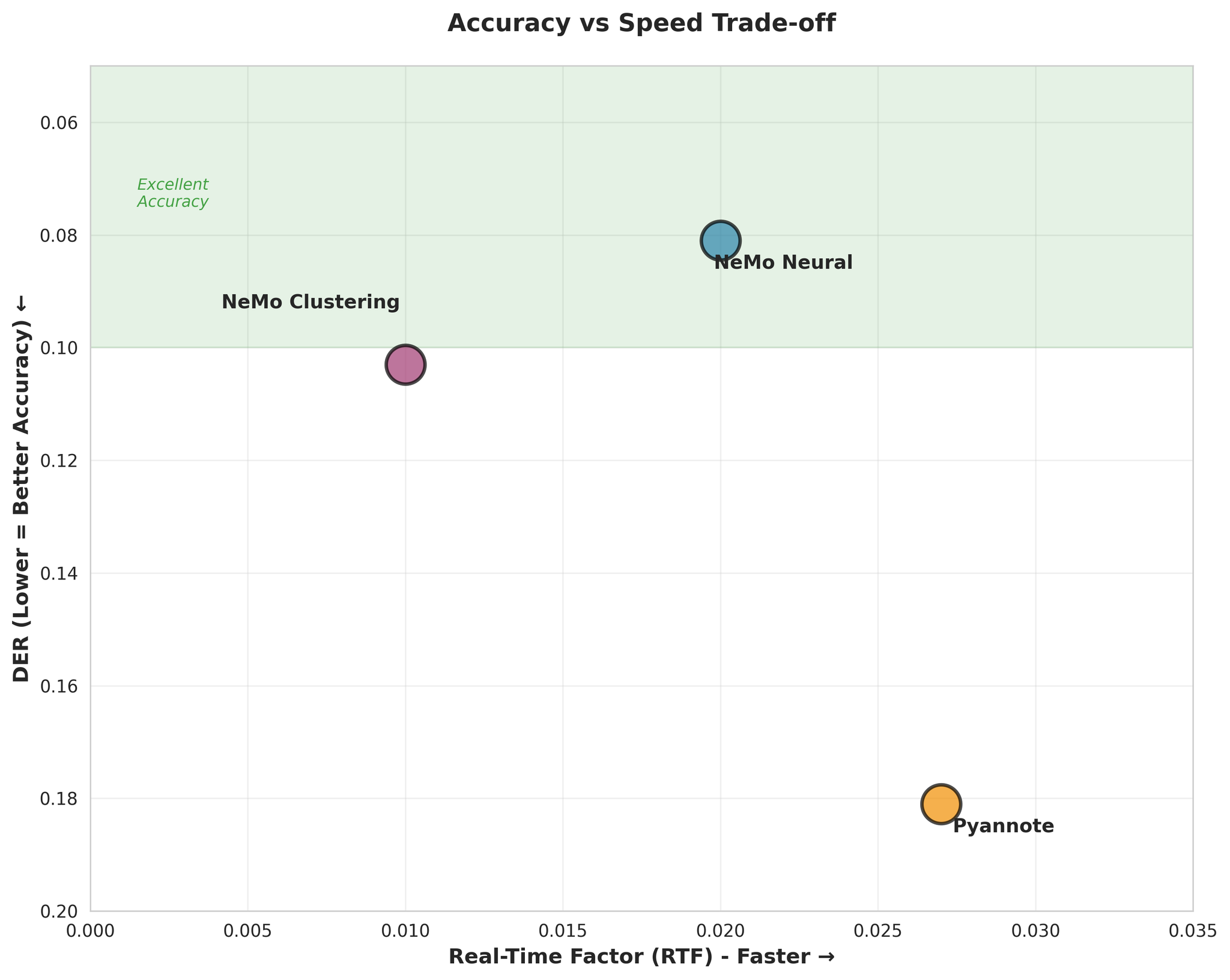
重要发现: NeMo Neural 在准确度和速度上都表现最优,是大多数场景的最佳选择。
5. 分场景结果
5.1 长音频(10分钟)
NeMo Neural 各语言结果:
- EN: 0.019(优秀)
- JA: 0.157(比英语难 8.3 倍)
- KO: 0.046
- VI: 0.037
- ZH: 0.053
- 平均: 0.062
5.2 超长音频(30分钟)
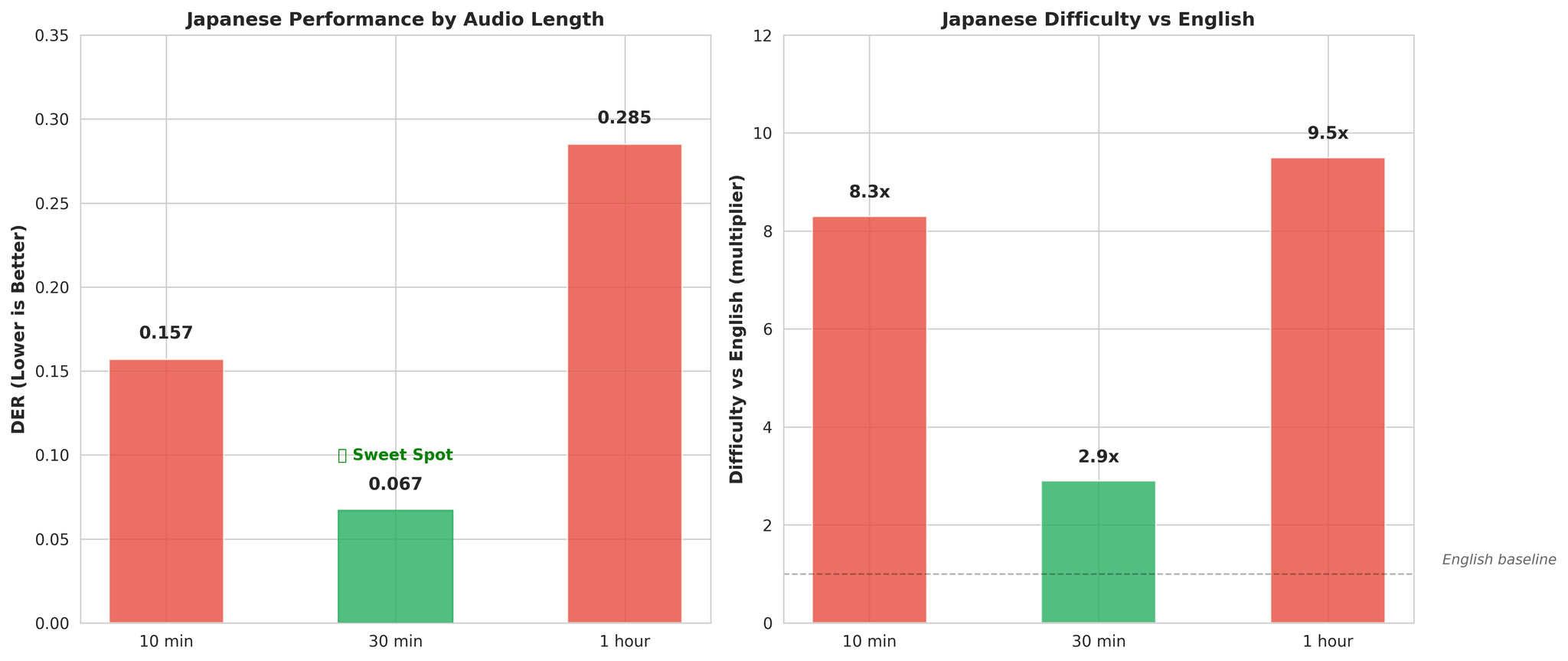
关键发现——日语在较长上下文中改善明显:
- 10分钟音频:DER 0.157(比英语难 8.3 倍)
- 30分钟音频:DER 0.067(比英语难 2.9 倍)
较长的音频为声调语言建模提供了更好的声学上下文。
5.3 高重叠(40%)
- NeMo Neural 和 Clustering 性能几乎相同(DER: 0.114 vs 0.115)
- Pyannote 表现较差(DER: 0.202,比 NeMo 差约 77%)
- 日语仍然是最困难的语言(DER: 0.232)
6. 语言分析
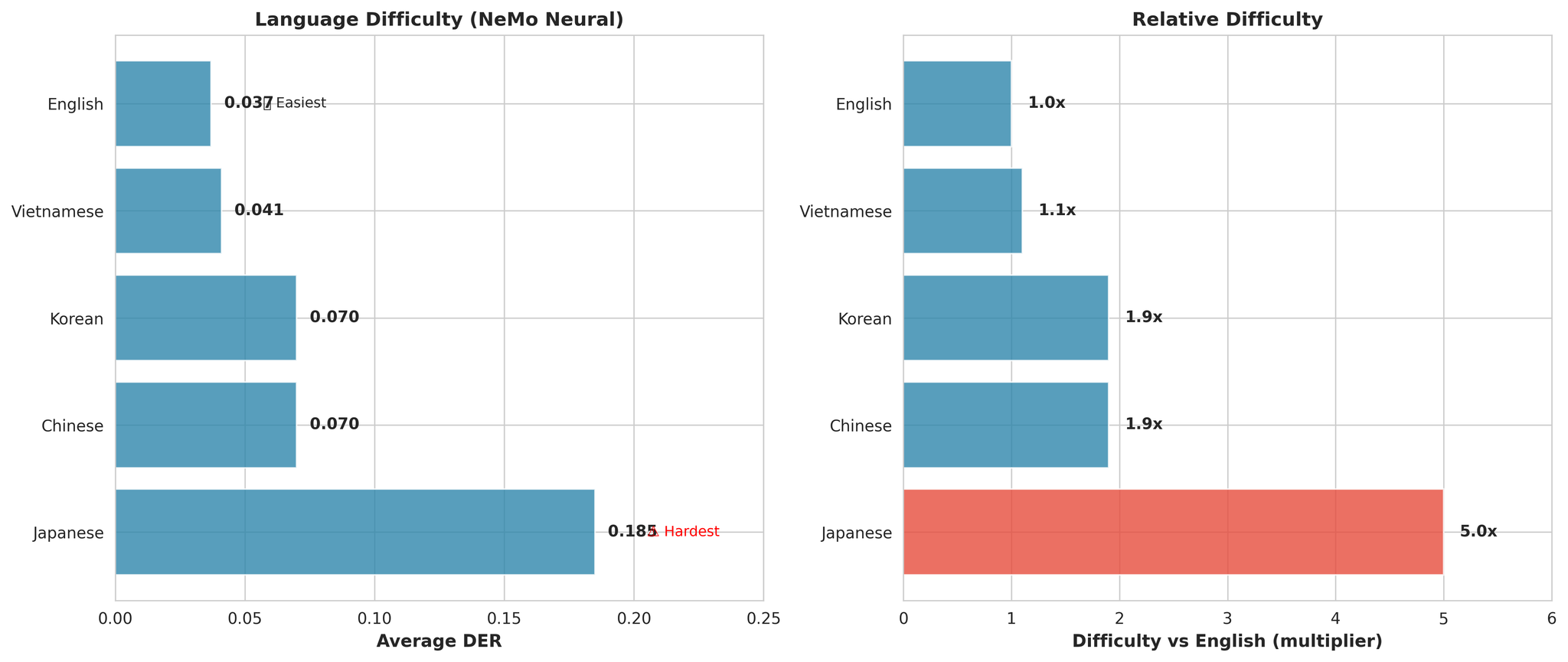
主要观察:
- 日语是所有模型中最困难的(平均比英语难 5.0 倍)
- 英语最容易(DER: 0.037)
- 越南语接近第二(仅比英语难 1.1 倍)
日语为何困难
假设:
- 声调语言:音高承载语言含义,导致说话人嵌入混淆
- 音位体系狭窄:约 100 个音拍 vs 英语数千个音素
- 音节时长较短:每个说话轮次的时间上下文较少
7. 神经式 vs 聚类式
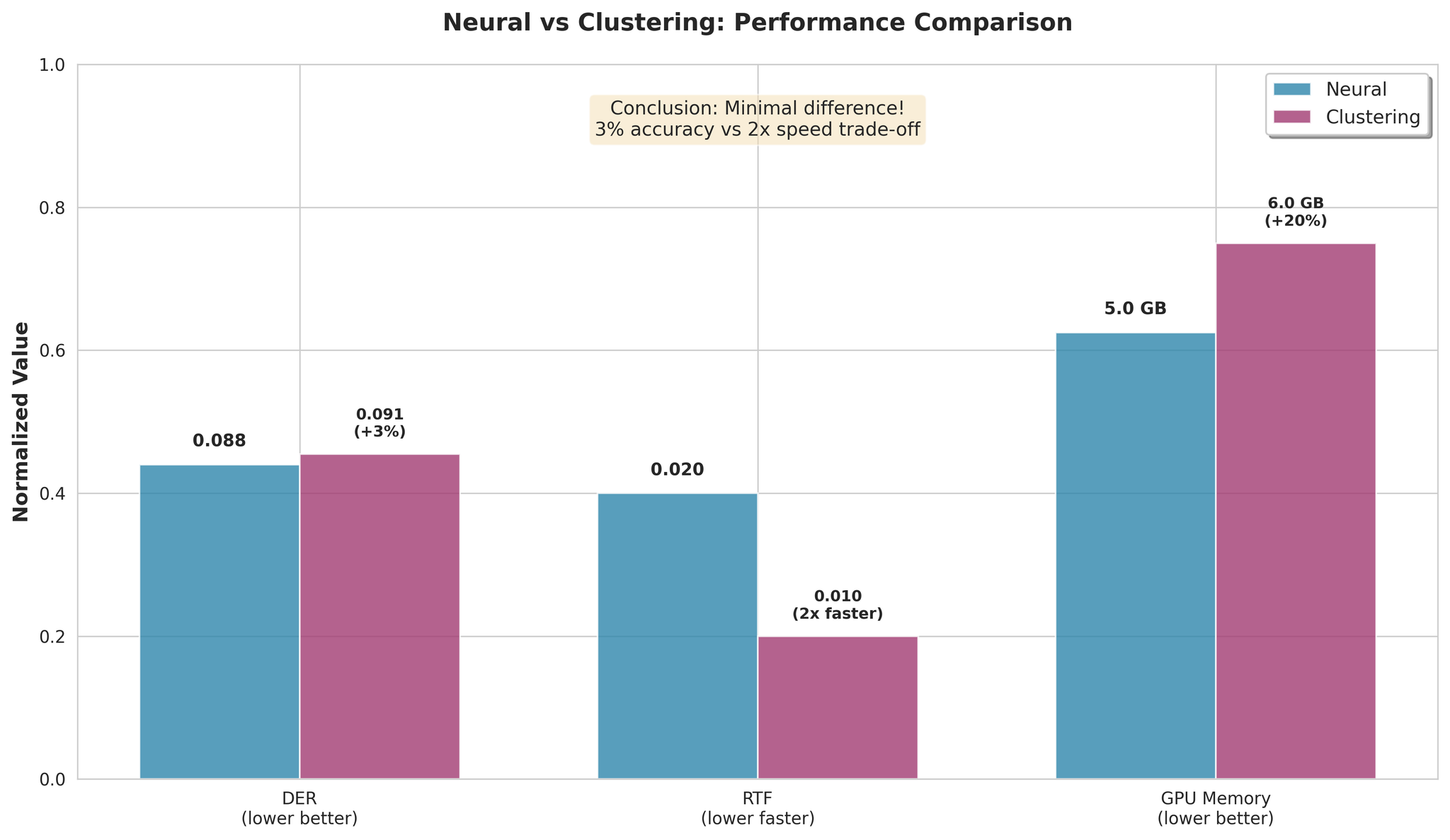
主要发现:
- Clustering 平均仅差 3%
- Clustering 处理速度快 2 倍
- 速度/准确度权衡极小
建议:
- 追求最高准确度:选择 NeMo Neural
- 追求最快速度:选择 NeMo Clustering(快 2 倍,差 3%)
8. 多语言性能
8.1 日语的影响
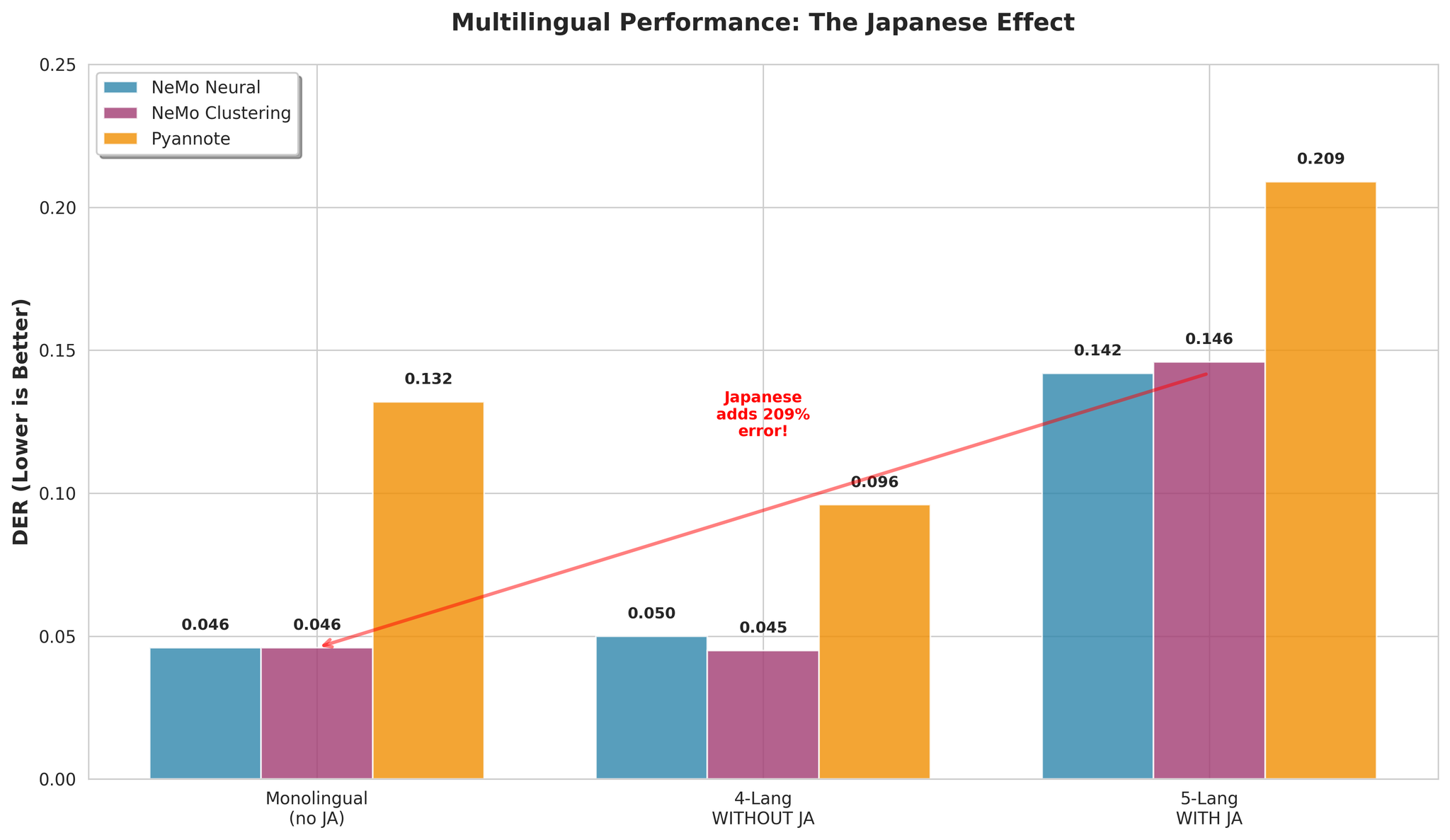
关键洞察: 日语是导致多语言分离困难的主要因素。
| 配置 | NeMo Neural DER |
|---|---|
| 含日语(5种语言) | 0.142 |
| 不含日语(4种语言) | 0.050 |
8.2 错误分析
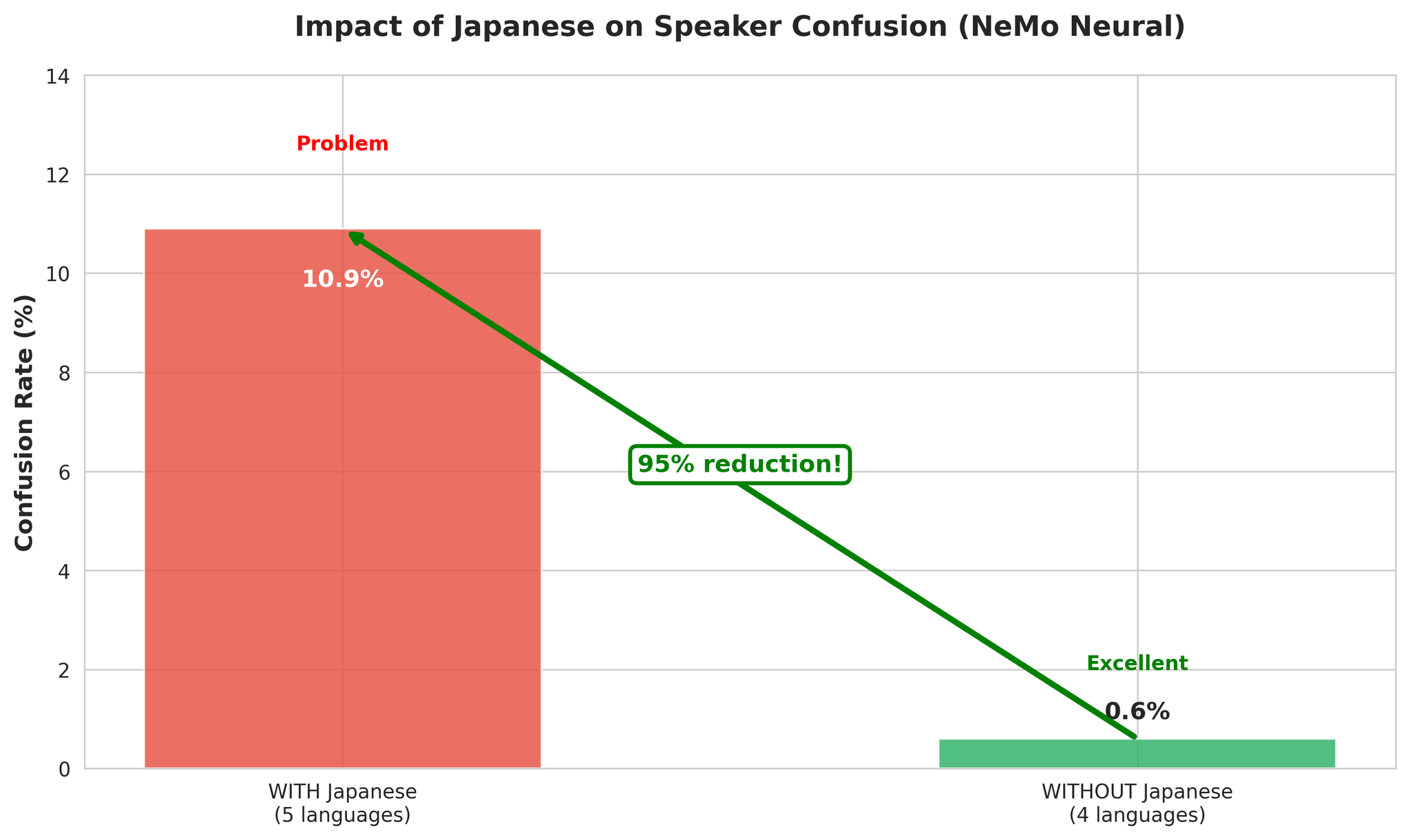
4种语言多语言表现好的原因:
- 更多的声学多样性帮助 VAD 检测语音边界
- 语言切换提供了自然的分段边界
- EN、KO、VI、ZH 具有兼容的声学特征
- 日语的声调特征导致跨语言的说话人混淆
9. 结论
核心结论
NeMo Neural 是最佳选择:
- 最高准确度:DER 0.081(平均)
- 快速处理:RTF 0.020(实时的 50 倍)
- 不含日语的多语言表现优异:DER 0.050
关键发现:
- 日语在较长上下文中显著改善(30分钟为最优)
- 含日语的多语言虽有挑战(DER 0.142)但可控
- MSDD 神经网络精炼相比纯聚类仅有适度提升(27%)
- 所有模型都足够快,可用于生产环境
建议
| 使用场景 | 模型 | 原因 |
|---|---|---|
| 最高准确度 | NeMo Neural | DER 0.081 |
| 最快速度 | NeMo Clustering | 快 2 倍 |
| 长音频(30分钟~1小时) | NeMo Neural | 应对复杂性 |
| 多语言(无日语) | NeMo Neural | DER 0.050 |
| 日语(30分钟以上) | NeMo Neural | 上下文有帮助 |
默认选择: NeMo Neural——兼具最佳准确度和快速处理。