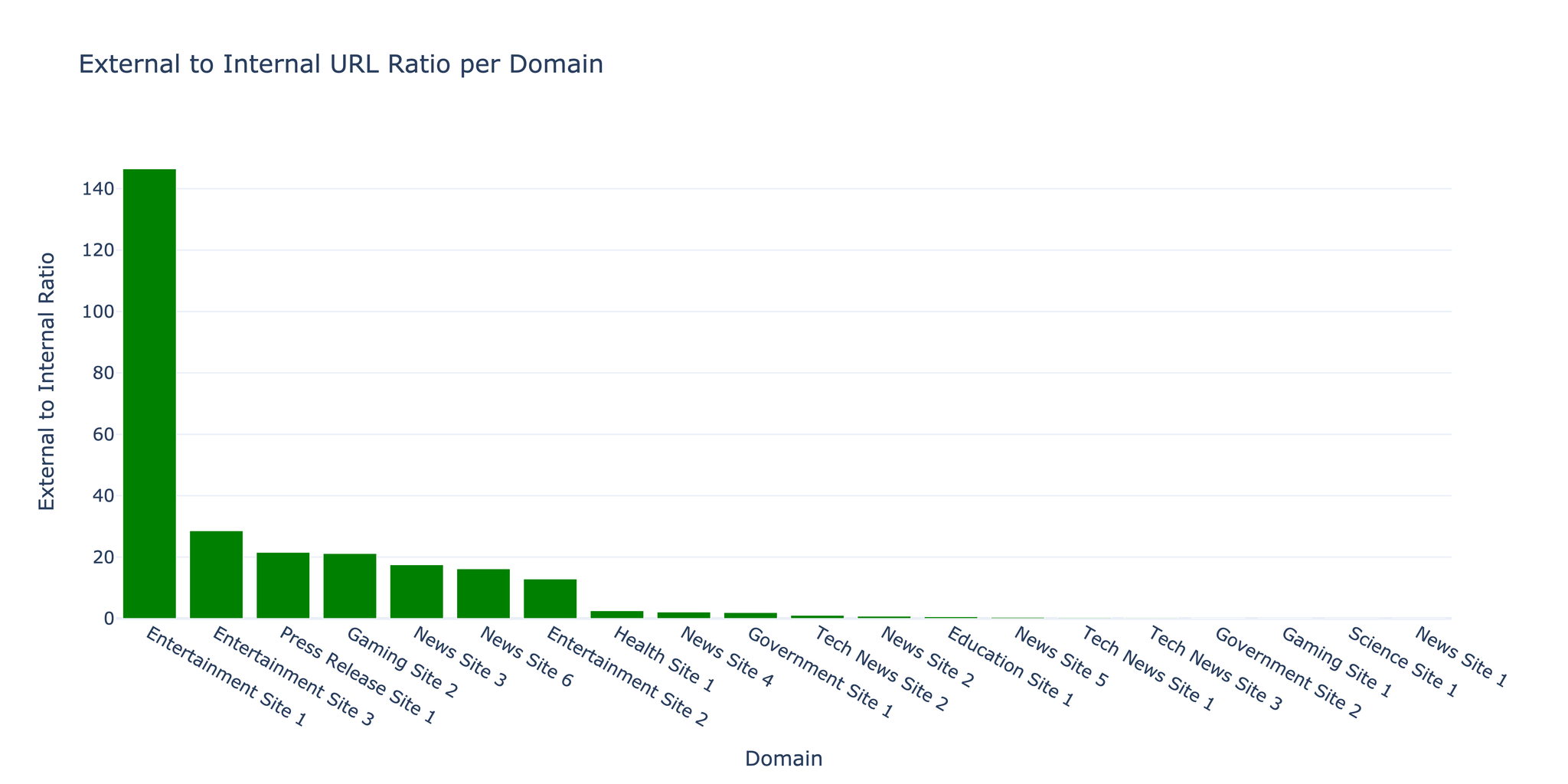
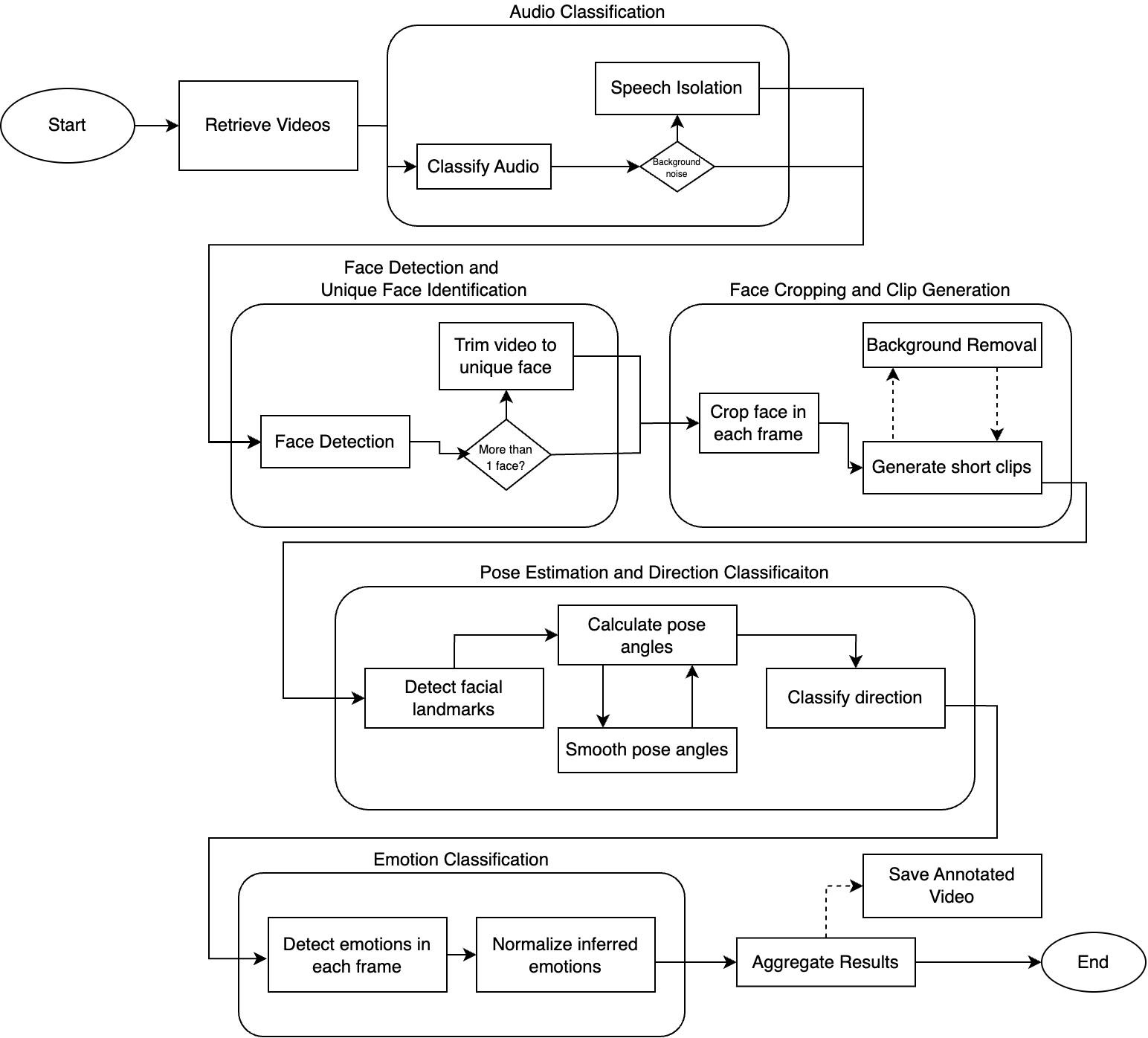
基于 AISHELL-3 数据集和 Bert-VITS2 框架开发普通话语音合成系统的研究报告。
摘要
本研究介绍了使用 Bert-VITS2 框架开发快速且自然的普通话语音合成(TTS)系统的工作。该系统专为会议场景设计,旨在生成清晰、富有表现力且符合语境的语音。
核心成果:
- 在对比模型中取得最低 WER 0.27
- 语音自然度 MOS 2.90
- 成功合成最长 22 秒的语音
- 基于 AISHELL-3 数据集训练(85小时,218名说话人)
1. 引言
什么是语音合成
语音合成(TTS)技术将书面文字转换为自然流畅的语音。现代 TTS 系统借助深度学习生成越来越自然、富有表现力的语音,应用领域包括:
- 智能助手
- 无障碍阅读方案
- 导航系统
- 自动化客户服务
为什么选择中文
普通话是全球使用人数最多的语言,拥有超过十亿使用者。然而,由于其声调特性和复杂的语言结构,普通话为 TTS 带来了独特的挑战。
什么是 Bert-VITS2
Bert-VITS2 将预训练语言模型与先进的语音合成技术相结合:
- BERT 集成:深度理解语义和上下文细微差异
- GAN 风格训练:通过对抗学习生成高度逼真的语音
- 基于 VITS2:最先进的语音合成架构
2. 方法
2.1 数据集选择
本研究选用了 AISHELL-3 数据集:
- 85 小时音频数据
- 218 名说话人
- 每位说话人平均约 30 分钟
- 高质量转录文本
注意: 最初使用 Alimeeting(118.75 小时)进行实验,但由于转录质量不佳和每位说话人音频时长不足,生成了空白音频。
2.2 模型架构
Bert-VITS2 框架由四个主要组件构成:
| 组件 | 功能 |
|---|---|
| TextEncoder | 使用预训练 BERT 处理输入文本以理解语义 |
| DurationPredictor | 带有随机变化的音素时长估计 |
| Flow | 使用归一化流对音高和能量建模 |
| Decoder | 合成最终语音波形 |
2.3 训练过程
损失函数
- 重建损失:使生成语音匹配真实语音
- 时长损失:最小化音素时长预测误差
- 对抗损失:促进生成逼真语音
- 特征匹配损失:对齐中间层特征
模式崩溃缓解
- 用于稳定判别器的 Gradient Penalty
- 生成器和判别器的 Spectral Normalization
- 逐步增加复杂度的渐进式训练
超参数
| |
提示: 训练在单张 RTX 4090 GPU 上使用 bfloat16 精度进行。
3. 结果与讨论
训练过程
初始训练出现了模式崩溃(生成空白语音)。调整后:
- 判别器损失趋于稳定
- 生成器损失呈现明显下降趋势
- 训练过程中 WER 从约 0.5 降至约 0.2
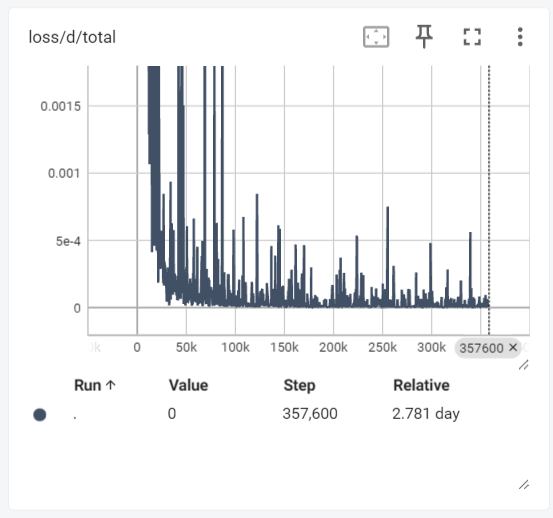
与其他模型的对比
| 模型 | WER | MOS |
|---|---|---|
| 本模型(Bert-VITS2) | 0.27 | 2.90 |
| myshell-ai/MeloTTS-Chinese | 5.62 | 3.04 |
| fish-speech (GPT) w/o ref | 0.49 | 3.57 |
注意: 本模型取得了最低 WER,表明语音生成准确度高。但在 MOS(自然度)方面,与参数量远超本模型的 fish-speech 相比仍有提升空间。
生成示例
成功合成了以下类型的语音:
- 短语(2-10 秒)
- 长语音(22 秒)——超出训练数据范围
局限性
语码转换:模型无法处理混合语言的文本(如中文中夹杂英文术语 “Speech processing”)。
4. 结论与展望
成果
- 成功对 Bert-VITS2 进行普通话 TTS 微调
- 在对比模型中取得最低 WER
- 掌握了缓解 GAN 训练挑战的方法
- 在各种时长条件下生成清晰可识别的语音
未来方向
- 增加训练步数以提升 MOS 分数
- 解决语码转换的局限性
- 扩展到更多说话人和应用领域
5. 参考文献
- Ren, Y., et al. (2019). “Fastspeech: Fast, robust and controllable text to speech.” NeurIPS.
- Wang, Y., et al. (2017). “Tacotron: Towards end-to-end speech synthesis.” Interspeech.
- Kim, J., et al. (2021). “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech.” ICML.
- Kong, J., et al. (2023). “VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech.” INTERSPEECH.
- Shi, Y., et al. (2020). “AISHELL-3: A Multi-speaker Mandarin TTS Corpus and the Baselines.” ArXiv.
- Saeki, T., et al. (2022). “UTMOS: UTokyo-SaruLab System for VoiceMOS Challenge 2022.” INTERSPEECH.
资源
- Bert-VITS2 代码仓库:github.com/fishaudio/Bert-VITS2
- AISHELL-3 数据集:openslr.org/93