Voice Activity Detection(VAD)을 활용하여 클라우드 STT 서비스의 이용 비용을 대폭 절감한 VoicePing의 구현 방법을 소개합니다.
이 글에서는 VoicePing에서 Speech to Text를 구현한 세부 사항과, 개발팀이 클라우드 서비스의 효율을 최대한 끌어낸 방법을 설명합니다.
VoicePing은 풍부한 기능을 갖추고 있으며 원격 팀을 위한 최적의 솔루션입니다! 현재 프리미엄 구독을 1년간 무료로 제공하고 있습니다. https://voiceping.net/ 에서 시작해 보세요!
개요
Speech-to-Text를 처음부터 구현하여 좋은 인식 정확도를 달성하는 것은 매우 어렵습니다. 그래서 많은 기업과 개발자들이 뛰어난 성능을 갖추고 다양한 언어를 지원하는 SaaS 솔루션을 선택합니다.
사용량에 따라 저렴한 솔루션이 될 수 있습니다. 과금 방식이 “종량제"이기 때문입니다. 하지만 이는 사용량이 많을 경우 비용이 높아질 수 있는 이유이기도 합니다. 사용 방식과 사용량에 따라 달라집니다.
이 글에서는 회의 중 사용자 오디오에 STT를 적용할 때 발생하는 높은 비용을 줄이기 위해 VoicePing이 사용하는 전략을 소개합니다. 회의에서는 대부분의 사용자가 청취자이며, 회의 시간의 대부분 동안 발화하지 않기 때문에 이 전략이 가능합니다. Voice Activity Detection(VAD) 라이브러리를 사용하여 무음 오디오가 서비스로 스트리밍되는 것을 방지하는 것이 핵심입니다.
이 전략을 구현하면서 겪었던 문제들과 해결 방법도 함께 소개합니다.
서론
Speech-to-Text(STT)는 자동 음성 인식(ASR)이라고도 하며, 다양한 활용 사례가 있는 기능입니다. YouTube에서의 자동 자막 생성, Siri, Alexa, Cortana와 같은 개인 가상 비서, 그리고 이 기능을 활용하는 수많은 음성 기반 애플리케이션이 있습니다.
VoicePing에서는 회의 중 발화 시 실시간 전사를 표시하는 데 사용하며, 이 전사에 대한 실시간 번역도 제공합니다. 또한 이러한 전사를 Slack 워크스페이스의 퍼블릭 또는 프라이빗 채널에 자동으로 동기화하도록 설정할 수 있어, 회사의 업무 관련 모든 커뮤니케이션 기록을 안전하게 보관할 수 있습니다.
Slack에 동기화된 전사는 Slack의 다양한 기능을 활용할 수 있습니다. 회의 중 할당된 태스크에 관한 메시지를 북마크하거나, 특정 논의 항목을 채널에 고정하여 팀이 잊지 않도록 하거나, 회의가 일찍 끝나 논의가 충분하지 못한 경우 Slack 스레드에서 논의를 이어갈 수 있습니다.
구현
오디오를 텍스트로 변환하는 AI 시스템을 구현하는 것은 쉽지 않으며, 학습과 검증을 위한 대량의 오디오 파일과 전사 데이터가 필요합니다. 지원하는 언어가 많아질수록 작업량도 증가합니다.
다행히 다양한 서비스가 있으며, 이러한 서비스의 품질은 날로 향상되고 있습니다. 경우에 따라서는 전문 인간 전사가에 필적하는 정확도를 보여줍니다. 그러나 앱의 사용자 수와 매출에 따라 비용이 너무 높고 지속 불가능할 수 있습니다. 비용 문제를 해결하기 위한 두 가지 솔루션을 제안합니다.
첫 번째 솔루션은 가장 저렴한 옵션으로, 무료 서비스를 이용하는 것입니다. 대부분의 서비스에는 동시 사용량과 이용 시간에 제한이 있는 무료 티어가 있습니다. 무료 티어가 충분하지 않다면, 과금 없는 SaaS STT 솔루션은 알지 못하지만, 실험적인 Web Speech API가 있습니다. Google Chrome과 Microsoft Edge 등 일부 브라우저에서 이미 구현되어 있습니다.
뛰어난 기능이지만 한계가 있습니다. 실험적 API이기 때문에 모든 브라우저가 지원하지 않으며, 사용자에게 다른 브라우저를 사용하라고 요구하면 앱 평판에 영향을 줄 수 있습니다. 또한 어떤 입력 장치를 사용할지 선택할 수 없고, .start()를 호출하면 항상 기본 입력 장치에서 녹음이 시작되는 제한도 있습니다.
이로 인해 서드파티 서비스를 선택하고, 비용을 절감하는 방법을 찾기로 했습니다. 다음 섹션에서 이 두 번째 솔루션에 대해 설명합니다.
비용 절감
이러한 서비스를 사용할 때, 서버에 생성하는 워크로드에 따라 비용을 지불하는 것은 당연합니다. Speech to Text 솔루션에서는 시간당 약 1.00~1.50 USD의 비용이 발생합니다. 월 80,000시간 이상의 대량 사용 시 시간당 약 0.50 USD까지 내려갈 수 있습니다. 문제는 오디오 스트림이나 파일을 처리에 보낼 때, 발화가 포함되어 있든 없든 서비스 측에서는 처리해야 할 바이트 묶음으로만 인식한다는 점입니다. 수신 대역폭 비용이 있으며, 무음 처리 비용이 다소 낮더라도 처리는 이루어지므로 과금됩니다.
VoicePing에서 5명 참가자의 1시간 회의가 있으면, 이 한 건의 회의에만 5 USD를 지불해야 합니다. 같은 팀이 월 6회 이런 회의를 하면 30 USD입니다. 참가자가 10명이면 60 USD, 팀 하나만으로도 이 금액입니다. 이런 팀이 10개라면 월 600 USD가 됩니다. 가치 있는 활용이라면 문제없지만, 10명 참가 회의의 경우 실제로는 전원이 동시에 말하지 않습니다. 대부분의 시간에는 한 명만 말하고 있습니다. 아무도 말하지 않을 때도 있습니다. 스크럼 회고 미팅에 참여해 본 적이 있다면 아실 것입니다. 화면에 카운트다운 타이머를 설정하고, 지난 스프린트의 좋았던 점과 나빴던 점을 적는 몇 분 동안은 아무도 말하지 않습니다. 이것은 STT 사용 시간의 큰 낭비입니다.
이 낭비를 줄이기 위한 가장 확실한 방법은 마이크가 음소거되었을 때 STT를 끄는 것입니다. 저희도 이렇게 하고 있으며, 사용량을 상당히 줄일 수 있지만, 사용자가 말하지 않을 때 마이크를 끄는지 여부에 의존하기 때문에 충분하지 않습니다. 많은 회의에 참여해 본 사람이라면, 말하지 않으면서도 마이크를 켜둔 사용자가 항상 있다는 것을 알 것입니다. 말할 때마다 마이크를 켜고 끄는 것은 번거로우며, 소음을 내지 않는 한 켜둬도 문제가 없기 때문입니다.
VoicePing에서는 기본 활성화되어 있는 우수한 노이즈 리덕션 기능 덕분에 회의 내내 마이크를 켜두어도 다른 참가자에게 방해가 되지 않습니다. 이것은 다른 주제의 글에서 다루겠지만, VoicePing 노이즈 리덕션에 대해서는 여기에서 확인하실 수 있습니다: https://tagdiwalaviral.medium.com/struggles-of-noise-reduction-in-rtc-part-1-cfdaaba8cde7
실제로 많은 사용자가 마이크를 켜둔 채로 두므로, 무음 오디오에 의한 STT 사용 시간 낭비를 방지해야 합니다. 서비스에 오디오를 보내 텍스트 변환 처리를 하기 전에, Voice Activity Detection이라는 기술을 사용하여 클라이언트/브라우저에서 먼저 전처리합니다.
코드를 살펴보겠습니다. 초기 설정과 기대 결과부터 시작합니다.
초기 설정
React와 TypeScript를 사용하므로, React Hooks를 활용한 예제를 보여드립니다. Azure Speech to Text 서비스를 사용하므로 예제에서 Azure API를 사용하지만, 사용량 절감 전략은 어떤 서비스에도 적용 가능합니다.
커스텀 훅 useSpeechToText를 만들었습니다. 코드는 나중에 보여드리지만, 먼저 이 커스텀 훅을 호출하는 루트 컴포넌트 예제를 살펴보겠습니다:
위 코드에는 두 가지만 있습니다:
- 마이크 음소거/음소거 해제 버튼
- 인식된 음성 목록:
컴포넌트 state에 결과 배열을 정의하고, showMessage 함수에서 마지막 STT 결과를 배열에 삽입하거나, 부분 결과인 경우 마지막 요소를 교체합니다. 아래 예제 영상에서 동작을 확인할 수 있습니다. 다음 사항에 주목해 주세요:
위 코드에서 볼 수 있듯이, STT 서비스 호출 로직은 포함되어 있지 않습니다. 이 로직은 모두 useSpeechToText 훅 내부에 있으며, 아래 코드에서 확인할 수 있습니다:
세부 사항이 많지만, 가장 중요한 부분은 서비스에 데이터를 전송하는 곳으로, onAudioProcess 함수 내의 pushStream.write(block.bytes); 호출(73번째 줄)입니다. 사용량을 줄이기 위한 가장 중요한 변경은 이 줄 주변에서 이루어집니다.
위 영상에서 확인할 수 있듯이, 마이크가 음소거 해제되어 있는 동안 데이터가 서비스로 계속 전송됩니다. 이를 수정하기 위해 이 훅에 VAD를 통합합니다.
Voice Activity Detection (VAD)
음성을 텍스트로 변환하는 것은 복잡한 작업이지만, 무음에는 발화가 없으며, 오디오에 발화가 포함되어 있는지 식별하는 것은 그다지 복잡하지 않습니다. 이미 오픈소스 코드가 무료로 제공되고 있으므로 바퀴를 다시 만들 필요가 없습니다. 이를 구현하는 npm 패키지가 두 가지 있습니다.
hark 패키지를 사용하기로 했습니다. 사용이 매우 간편하며, 재사용 가능한 훅을 만들었습니다:
이 코드는 이미 가지고 있는 MediaStream 객체를 파라미터로 받아, 이 스트림에서 hark를 인스턴스화하고, hark의 speaking과 stopped_speaking 이벤트에 사용자가 발화 중인지 나타내는 boolean state를 설정하는 함수를 바인딩합니다. 이 state를 사용하여 STT를 켜거나 끕니다. 하지만 처리해야 할 몇 가지 문제가 있으며, 다음 예제에서 다루겠습니다.
VAD 코드를 STT 코드에 통합
useSpeechToText 훅의 이전 버전에서는, 서비스에 데이터를 보낼지 여부를 확인하기 위해 mutedRef react ref를 사용했습니다. onAudioProcess 함수는 Azure의 SpeechRecognizer 인스턴스를 생성하는 것과 동일한 useEffect 훅 내에서 정의되므로, Azure 인스턴스의 재생성을 방지하기 위해 ref를 사용했습니다.
VAD를 통합하기 위해, muted state(파라미터 muted)와 useAudioActive 훅에서 정의한 VAD state(여기서는 speakerActive 변수)에 기반한 streamingFlagRef라는 새 플래그를 사용합니다. Azure 인스턴스가 초기화되기 전에 스트리밍이 시작되지 않도록 running.current도 사용합니다.
이 모든 변수를 shouldStream 변수의 AND 불리언 표현식으로 유지하며, 그 변경이 streamingFlagRef ref 값을 업데이트하는 useEffect를 트리거합니다.
이제 pushStream.write(block.bytes);로 서비스에 데이터를 전송할 때 if (!mutedRef.current) 대신 if (streamingFlagRef.current)를 확인합니다. 코드 변경 사항은 다음과 같습니다:
아래 영상에서 확인할 수 있듯이, 말을 멈추면 데이터 전송이 중단되지만, 새로운 문제가 발생했습니다:
위 영상에서 볼 수 있듯이, 말을 멈추면 스트리밍이 너무 일찍 중단된 것처럼 보입니다. 서비스가 이전 문장의 끝과 다음 문장의 시작을 식별하기 위해서는 발화의 일시 정지가 필요하기 때문입니다. 최소한 약간의 무음을 스트리밍하지 않으면, 서버는 두 문장을 일시 정지 없는 하나의 연속된 문장으로 인식합니다.
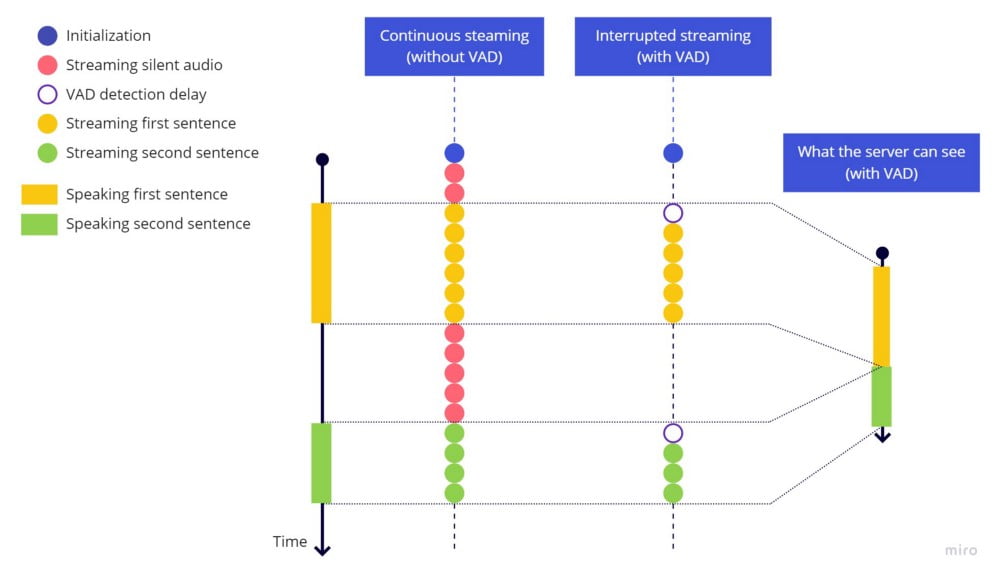 연속 스트리밍(VAD 없음) vs 중단 스트리밍(VAD 있음)
연속 스트리밍(VAD 없음) vs 중단 스트리밍(VAD 있음)
이 문제의 간단한 해결책은 스트리밍 중단 전에 타임아웃을 추가하는 것입니다. 하이라이트된 줄을 추가하여 시도해 보겠습니다:
다시 테스트하면 다음과 같은 결과가 나옵니다:
스트리밍 중단 전의 타임아웃이 작동하여 각 문장이 적절히 끝나고, 다음 문장은 무음 후 새 문장으로 식별됩니다. 하지만 빠르게 말하면 문장 시작 부분이 잘립니다. 발화를 시작한 시점부터 VAD 라이브러리가 소리를 감지하여 스트리밍을 재개할 때까지의 지연 때문입니다.
실제로 일어나고 있는 상황입니다. 각 문장 시작 부분에 VAD 감지 지연에 의한 빈 구간이 남아 있는 것에 주목하세요:
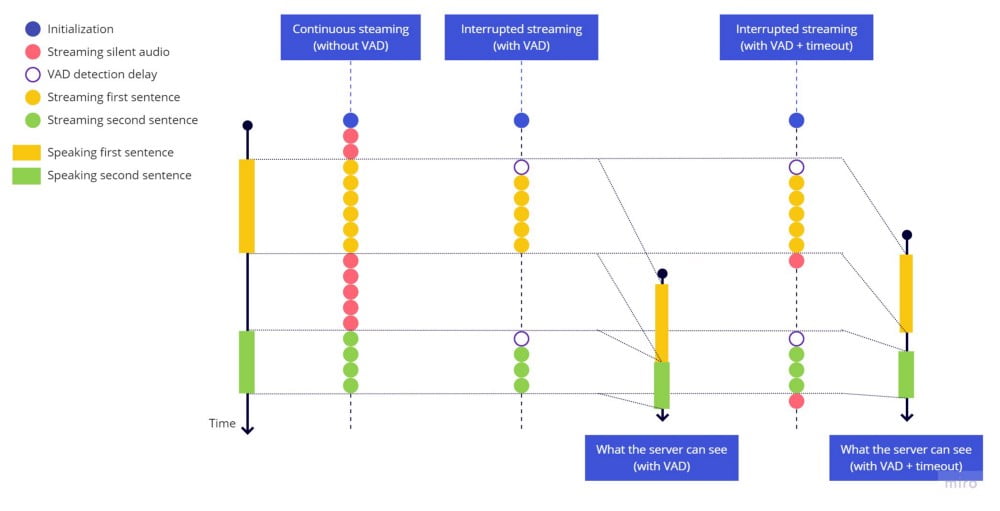 연속 스트리밍 vs 중단 스트리밍(VAD만) vs 중단 스트리밍(VAD+타임아웃)
연속 스트리밍 vs 중단 스트리밍(VAD만) vs 중단 스트리밍(VAD+타임아웃)
스트리밍을 시작하는 시점에서 첫 번째 단어의 시작에 해당하는 오디오 부분은 이미 이 지연으로 인해 손실됩니다. 문장 끝에서 발생한 문제와 유사하지만, 여기서는 타임아웃을 추가해도 해결할 수 없습니다. 과거에 실행되는 타임아웃을 설정하는 것은 불가능하기 때문입니다.
이 문제는 VAD 라이브러리가 매우 민감하여 작은 일시 정지에도 hark_stopped가 트리거되어 바운싱 효과가 발생하고, 문장 도중에 스트리밍이 여러 번 시작과 중단을 반복하는 문제와 결합되어 악화됩니다.
최종 해결책
두 문제가 관련되어 있고, 잘림 문제 없이 바운싱 문제를 보여주기 어려우므로 두 가지를 동시에 처리합니다.
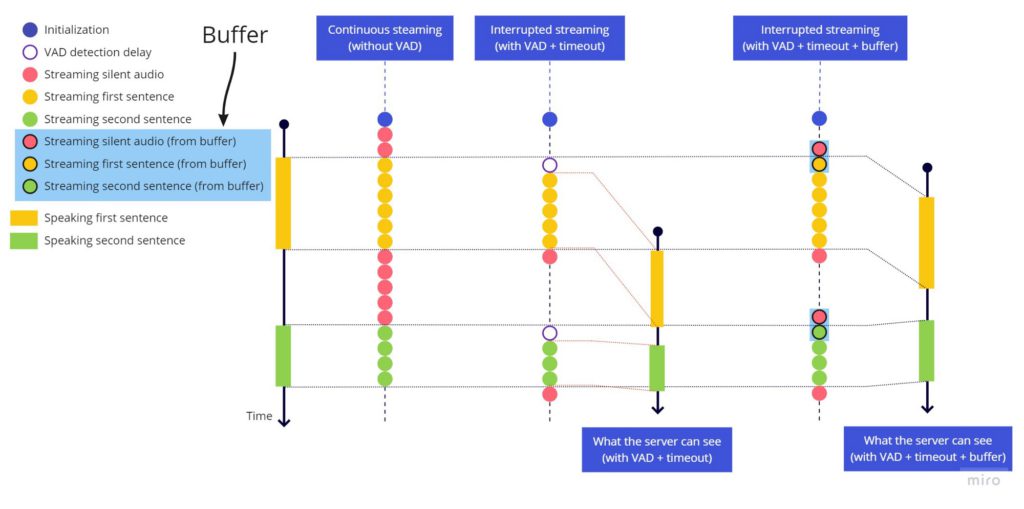
잘림 문제를 수정하기 위해, 문장 끝에 타임아웃을 추가한 것과 같은 방식으로 문장 시작에 타임아웃을 추가하는 것은 의미가 없으므로, 항상 최근 2초의 오디오를 보유하는 버퍼를 추가합니다. hark가 음성 활동을 감지하면 라이브 스트리밍을 보내기 직전에 버퍼 전체를 먼저 전송합니다. 지연이 그리 크지 않지만, 일부 언어에서는 발화 시작 전에 약간의 무음이 있을 때 인식 정확도가 향상되므로 2초로 설정했습니다.
바운싱 효과를 수정하기 위해, stop_speaking hark 이벤트가 트리거되면 2초 타임아웃을 시작하고, 2초 후에만 스트리밍을 중단합니다. 단, 이 기간 중 음성 활동(speaking hark 이벤트)이 감지되면 타임아웃을 취소하고, 음성 활동 중단을 감지하지 않은 것처럼 스트리밍을 계속합니다.
변경 사항:
파일 상단에 버퍼 크기(초)를 저장하는 BUFFER_SECONDS 상수 추가
훅 구현 상단에 버퍼 배열을 저장하는 bufferBlocks ref 추가
streamingFlagRef ref 값을 제어하는 useEffect 훅 내에 바운싱 효과를 처리하는 타임아웃 추가
onAudioProcess 내에서 서비스로 오디오를 스트리밍할 수 있는지 확인:
마지막 useEffect 클린업 함수에서 버퍼를 정리하여, 마이크 음소거/해제 시 깨끗한 버퍼로 시작하도록 보장
동작을 확인해 보겠습니다:
음성 활동 감지 시 라이브 스트림 시작 전에 전송할 수 있도록 최근 몇 초를 항상 이용 가능하게 유지하는 버퍼의 동작 방식:
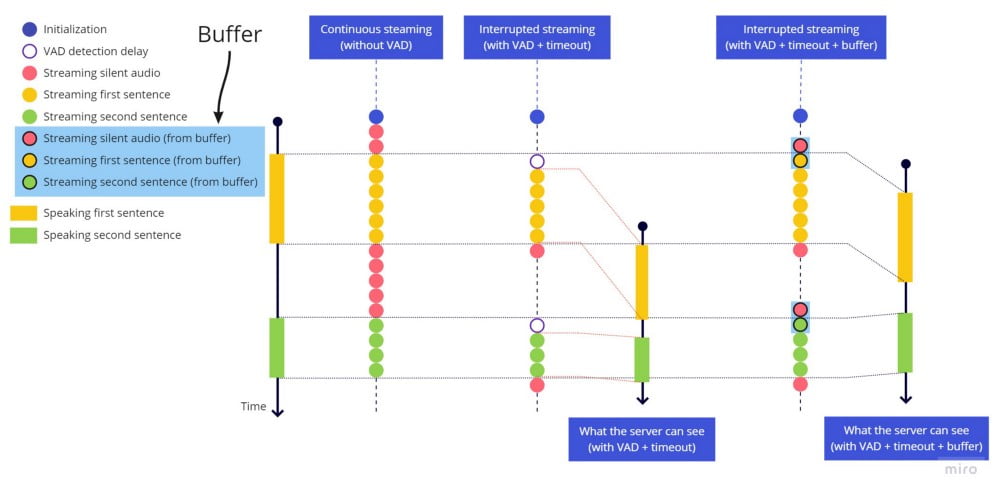 연속 스트리밍(VAD 없음) vs 중단 스트리밍(VAD+타임아웃) vs 중단 스트리밍(VAD+타임아웃+버퍼)
연속 스트리밍(VAD 없음) vs 중단 스트리밍(VAD+타임아웃) vs 중단 스트리밍(VAD+타임아웃+버퍼)
마무리
Chrome 개발자 도구의 네트워크 탭에서 확인할 수 있듯이, Azure 서비스로 전송되는 데이터는 발화 중에만 발생합니다. 이 글에서 해결한 모든 문제는 VoicePing 개발 과정에서 실제로 직면한 문제입니다. 이 코드는 현재 프로덕션 코드와 완전히 동일하지는 않습니다. 차이점 중 하나는 createScriptProcessor(지원 중단된 API)를 AudioWorkletNode로 교체하여 Web Workers를 사용해 앱의 메인 이벤트 루프 밖에서 오디오를 처리하는 점입니다. 튜토리얼을 간단하게 유지하기 위해 여기서는 script processor 버전을 보여드렸습니다.
또 다른 권장 아키텍처 변경은, 바운싱 효과 처리를 streamingFlagRef 플래그 값을 정의하는 코드에 혼재시키지 않고, hark 사용을 캡슐화하는 useAudioActive 내에 유지하는 것입니다. 실제 코드에서는 그렇게 하지 않았는데, useAudioActive가 여러 곳에서 사용되며, 다른 곳에서는 바운싱 효과를 그대로 유지하고 싶기 때문입니다.
VoicePing에서 이러한 기능들을 직접 사용해 보세요: https://voiceping.net/
소스 코드
이전의 모든 변경 사항을 적용한 최종 버전입니다. 읽어 주셔서 감사합니다.


