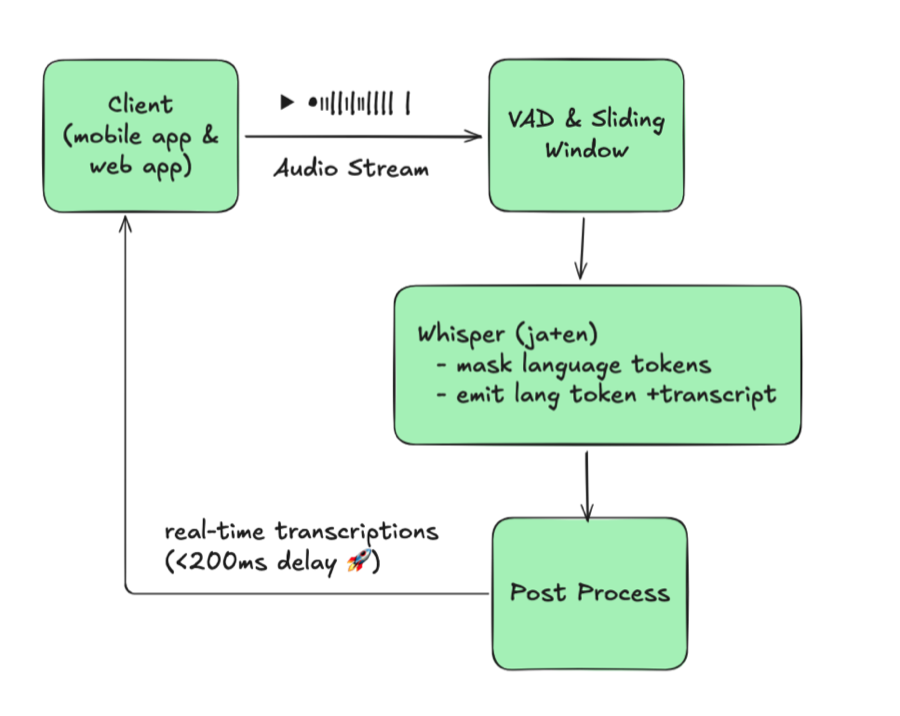
AsyncLLMEngine과 적절한 Continuous Batching 설정으로 vLLM 추론 처리량을 82% 향상시킨 방법
요약: 문제 상황
Part 1에서 병목 지점을 확인했습니다. FastAPI 서비스가 멀티프로세싱 워커와 IPC 큐를 사용하여 번역 태스크를 분배하고 있었으며, 다음과 같은 문제가 발생했습니다:
- 큐 직렬화 오버헤드
- 워커 프로세스 간 GPU 연산 경합
- 스파이크형 GPU 사용률 패턴
베이스라인: 동시 요청 25건에서 2.2 RPS
개선 방향: 멀티프로세싱을 제거하고 vLLM의 배치 추론을 활용하기.
시도 2: 정적 배치 처리
기존 워커 프로세스 내에서 정적 배치 처리를 구현했습니다.
구현
| |
핵심 사항:
- 배치 크기: 16개 요청
- 타임아웃: 50ms (배치가 가득 찰 때까지 무한 대기하지 않음)
- vLLM이 여러 시퀀스를 함께 처리
- 멀티프로세싱 워커는 그대로 유지
결과
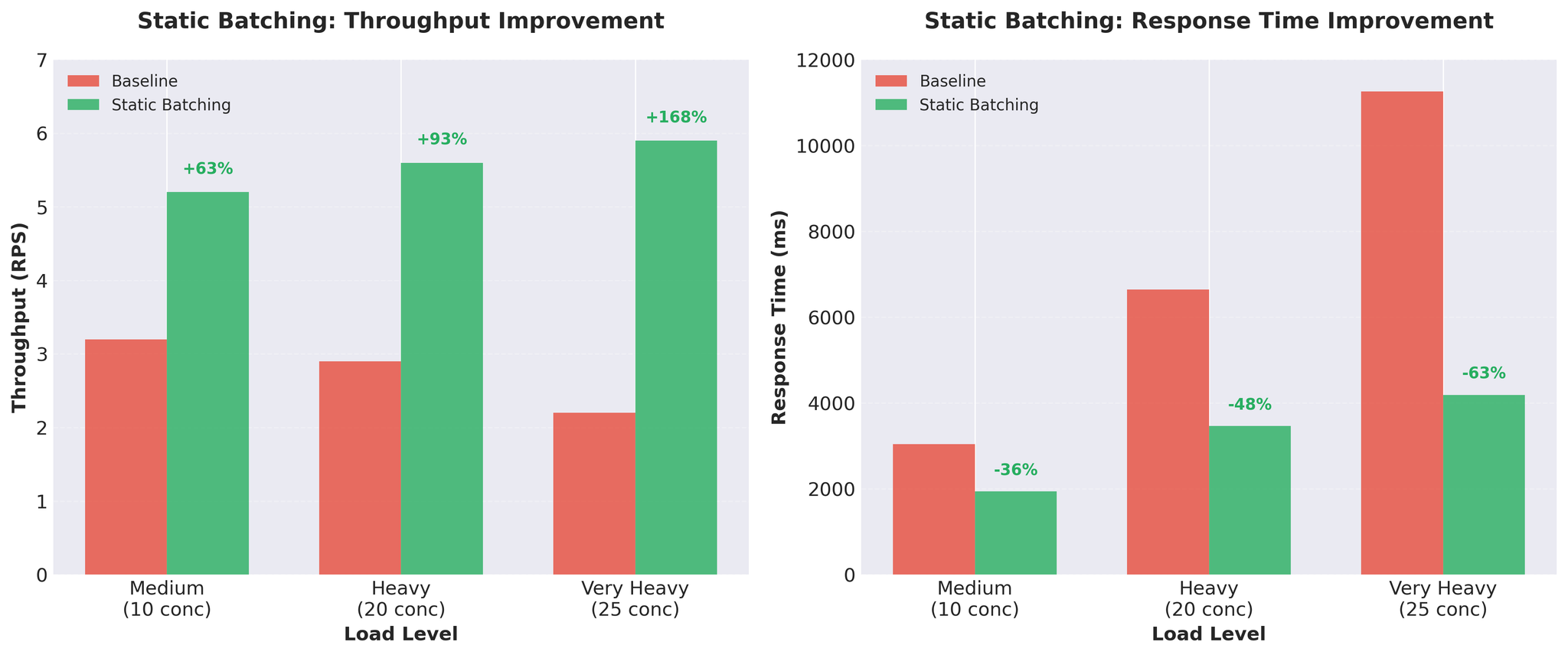
처리량이 약 3배 향상. 요청당 추론 시간: 452ms → 171ms.
장단점
장점:
- 대폭적인 처리량 향상
- GPU 활용도 개선
- 간단한 구현
단점:
- Head-of-Line 블로킹: 모든 요청이 가장 느린 요청을 기다림
- 입력 길이가 다양할 경우, 짧은 번역이 긴 번역을 기다림
- 예: [50 토큰, 50 토큰, 200 토큰] → 처음 두 개가 200 토큰 번역 완료를 대기
좋은 진전이었지만, Head-of-Line 블로킹 문제를 해결하고 싶었습니다.
시도 3: Continuous Batching
해결책: vLLM의 AsyncLLMEngine을 활용한 Continuous Batching.
Continuous Batching이란?
정적 배치와 달리 Continuous Batching은 배치를 동적으로 구성합니다:
- 새 요청이 생성 도중에도 배치에 합류
- 완료된 요청은 즉시 이탈 (다른 요청을 기다리지 않음)
- 매 토큰마다 배치 구성이 업데이트
- vLLM의 AsyncLLMEngine이 자동으로 처리
Head-of-Line 블로킹 없음. 짧은 번역은 완료 즉시 반환됩니다.
구현
| |
아키텍처 변경:
- AsyncLLMEngine을 FastAPI에서 직접 사용
- vLLM이 Continuous Batching 엔진으로 배치를 내부 관리
- 전체가 순수 async/await
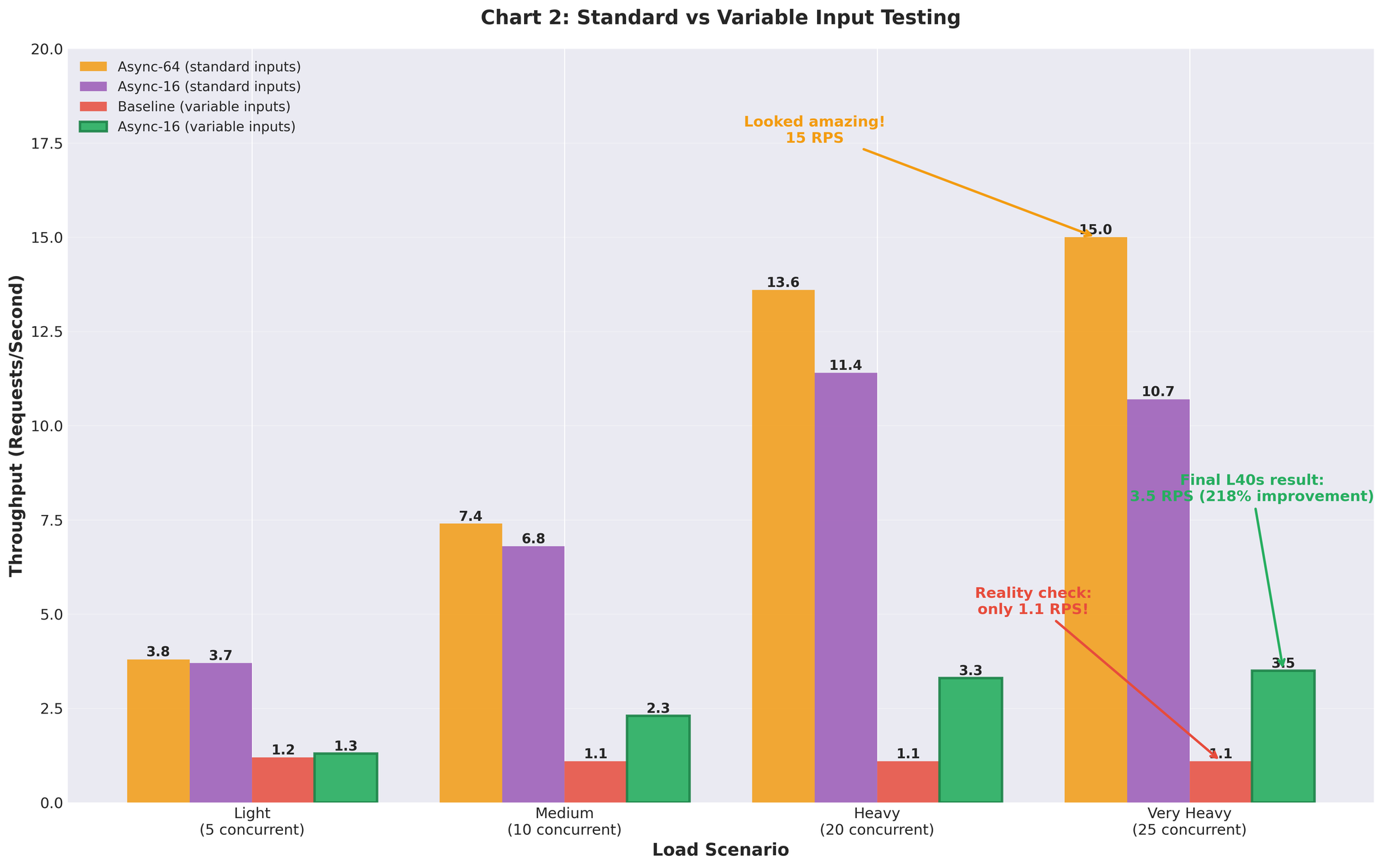
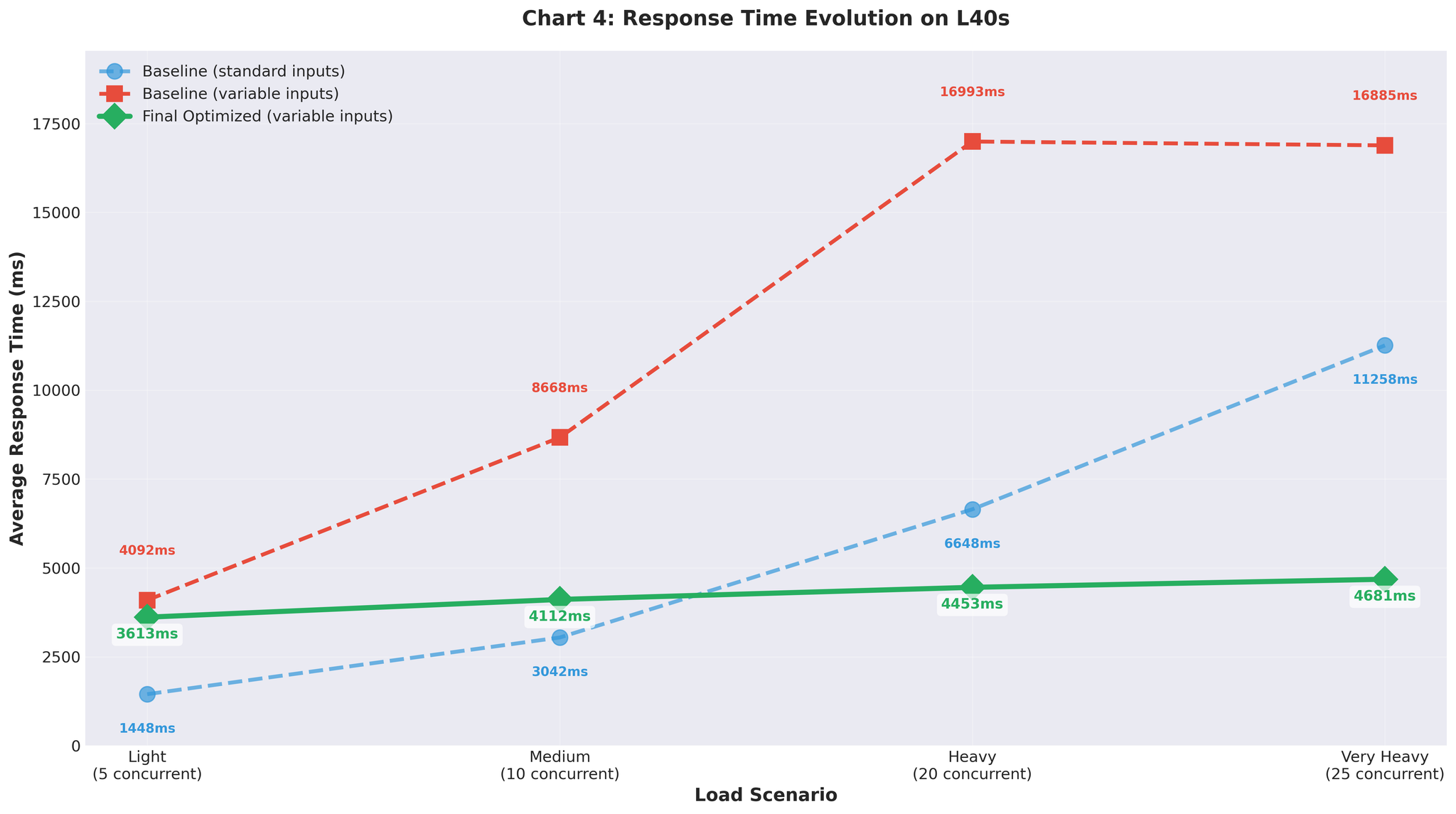
테스트 결과의 현실
초기 결과 (균일 입력)
표준적인 균일 길이 입력(유사한 길이)으로 테스트:
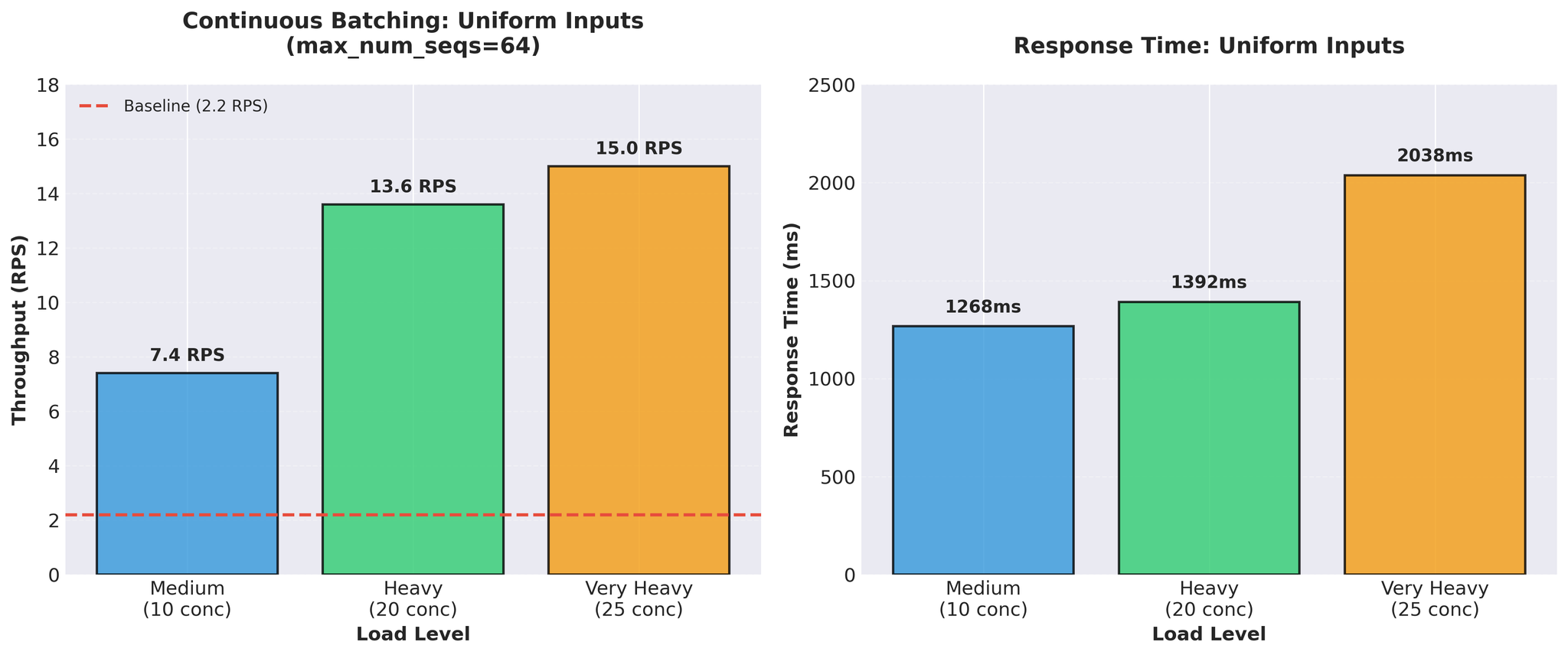
15 RPS vs 베이스라인 2.2 — 약 7배 개선. 매우 좋아 보였습니다.
가변 길이 입력 (현실 데이터)
현실적인 가변 길이 입력(10~200 토큰, 짧은 것과 긴 것 혼합)으로 테스트:
가변 입력에서의 베이스라인 재실행:
- 매우 높은 부하: 1.1 RPS (균일 입력의 2.2 RPS 대비)
- 베이스라인조차 현실 데이터에서는 성능 저하
가변 입력에서의 Continuous Batching (max_num_seqs=64):
- 매우 높은 부하: 3.5 RPS (max_num_seqs=16 튜닝 후)
- 균일 입력에서 15 RPS를 달성한 동일 설정
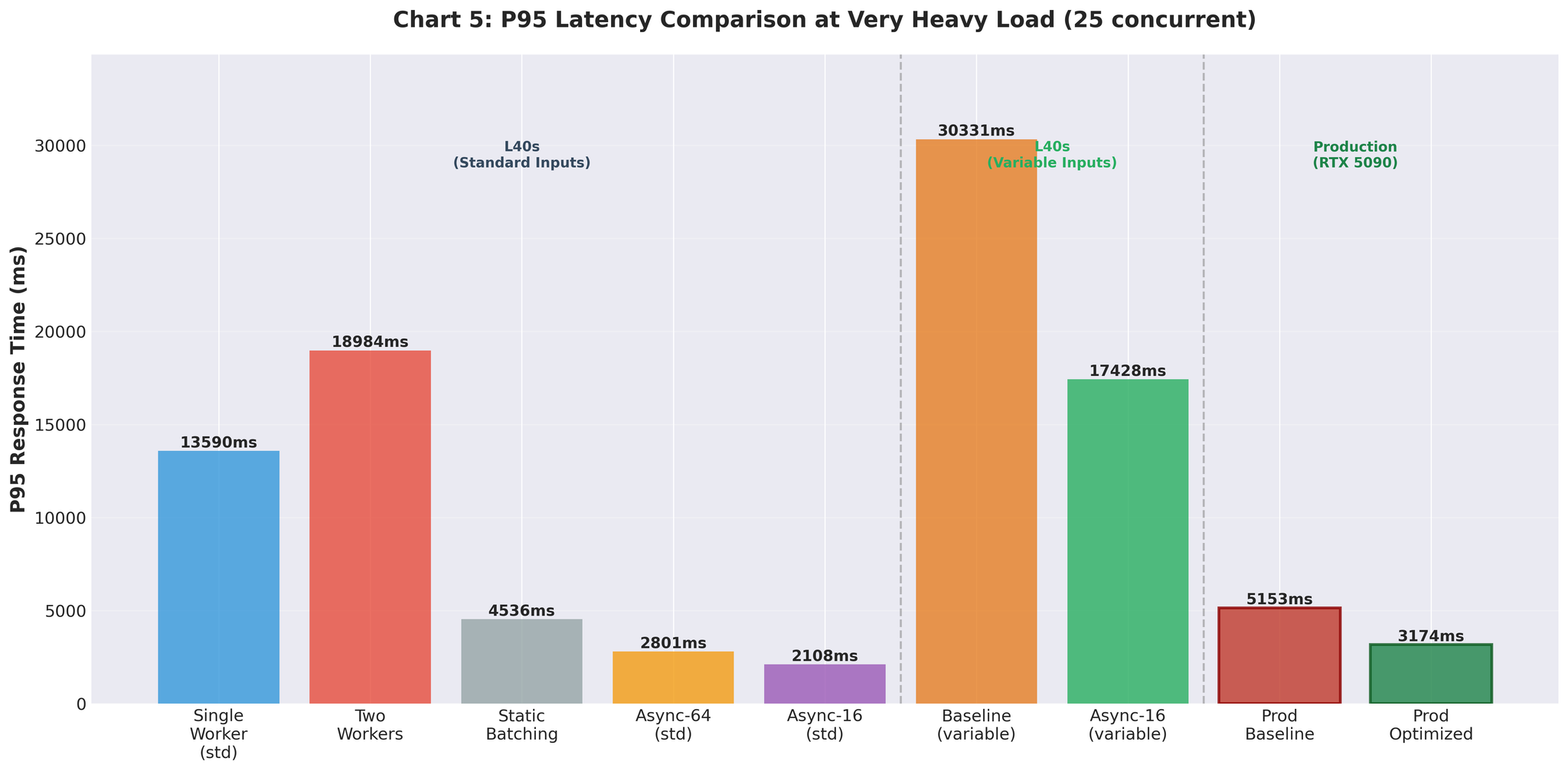
설정 튜닝
max_num_seqs=64에서의 저조한 성능으로 인해 vLLM 내부 메트릭을 분석했습니다.
발견한 사항
| |
문제점:
- 실제 워크로드: 서버당 2~20개 동시 요청 (프로덕션 피크 시 서버당 약 20개)
- 설정: max_num_seqs=64
- 결과: 60개 이상의 빈 슬롯이 오버헤드 생성
과대한 설정의 영향:
- 64개 시퀀스용 KV 캐시 사전 할당
- vLLM 스케줄러가 64개 슬롯을 관리하지만 실제 사용은 5~10개
- 토큰당 디코드 시간 증가
- 미사용 시퀀스 슬롯에 의한 메모리 낭비
- 빈 슬롯에 대한 스케줄러 오버헤드
튜닝 방법
vLLM Continuous Batching 튜닝 가이드에 따라:
- 프로덕션에서 실제 동시 요청 분포 측정
- max_num_seqs=1부터 시작, 점진적 증가: 2 → 4 → 8 → 16 → 32
- 각 단계에서 디코드 시간과 꼬리 레이턴시 모니터링
- 성능이 저하되면 중단
| max_num_seqs | 결과 |
|---|---|
| 8 | 레이턴시는 양호하나 처리량 제한 |
| 16 | 최적의 균형 |
| 32 | 디코드 시간 증가, 꼬리 레이턴시 악화 |
최종 설정
| |
설정 근거
max_num_seqs=16:
- 프로덕션 피크: 서버당 약 20개 동시 요청
- 테스트: 25개 동시 요청까지 검증
- 리소스 낭비 없이 여유 확보
- 스케줄러 오버헤드가 실제 부하에 적합
max_num_batched_tokens=8192:
- 기본값 16384에서 축소
- 평균 시퀀스 길이에 적합
- 메모리 부담 감소
gpu_memory_utilization=0.3:
- RTX 5090(32GB)에서 모델 + KV 캐시에 약 10GB VRAM 할당
- vllm:gpu_cache_usage_perc로 추적
- 구성에 맞는 균형
참고: 원칙: 이론적 한계가 아닌 실제 워크로드에 맞게 설정하기.
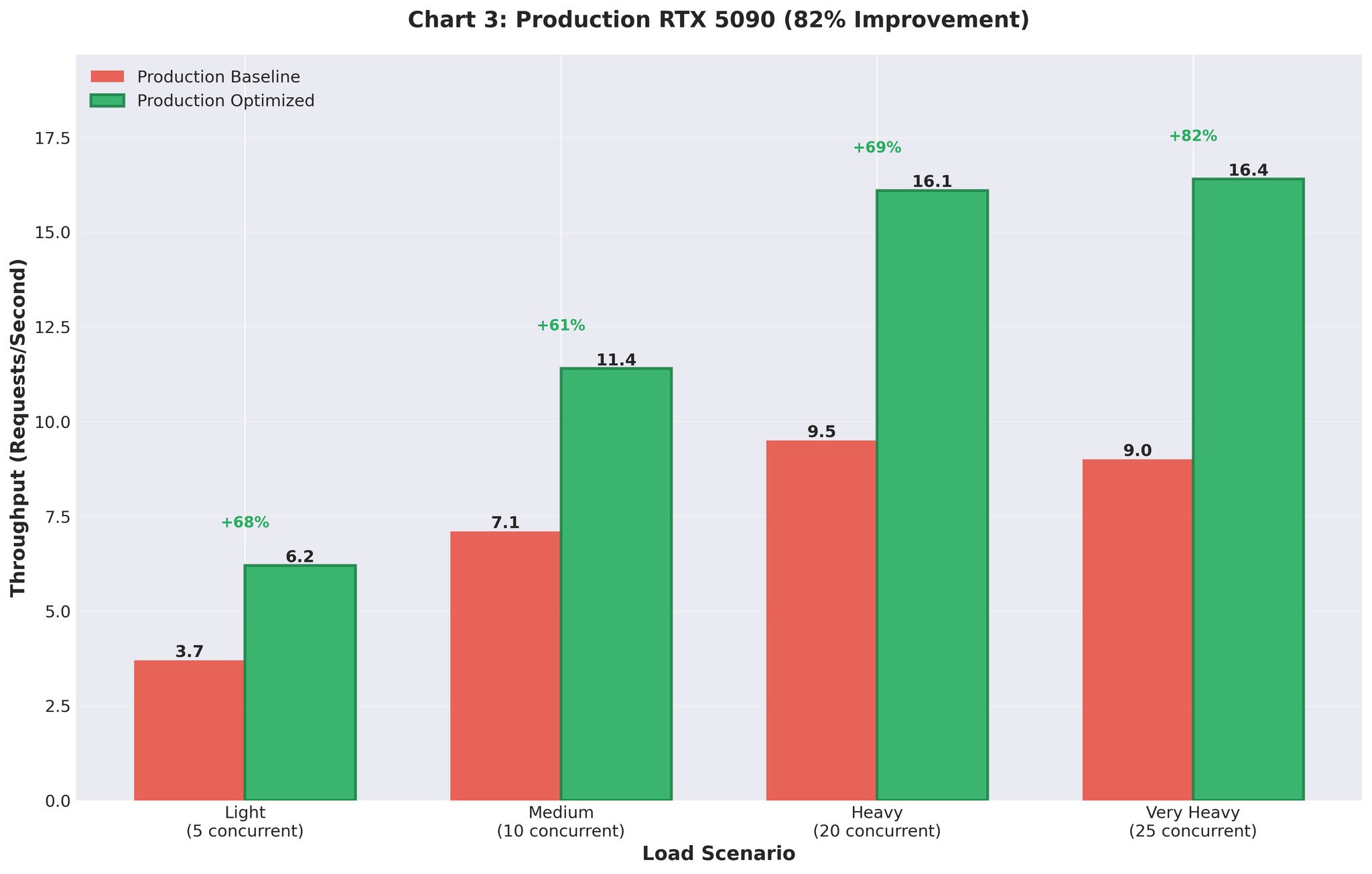
프로덕션 결과
최적화된 설정을 RTX 5090 GPU 프로덕션 환경에 배포했습니다.
개선 전 vs 개선 후
| 지표 | 개선 전 (멀티프로세싱) | 개선 후 (최적화된 AsyncLLM) | 변화 |
|---|---|---|---|
| 처리량 | 9.0 RPS | 16.4 RPS | +82% |
| GPU 사용률 | 스파이크형 (93% → 0% → 93%) | 안정적 90~95% | 안정화 |
프로덕션에서도 개선 효과가 유지되었습니다. 실제 트래픽 하에서 9 RPS에서 16.4 RPS로.
요약
효과가 있었던 방법
vLLM의 Continuous Batching
- AsyncLLMEngine이 배치 처리를 자동 관리
- 수동 배치 수집 오버헤드 없음
- FastAPI와 직접적인 async/await 통합
적절한 설정 선정
- max_num_seqs=16 (서버당 실제 워크로드에 맞춤)
- 64 (오버헤드를 유발하는 이론적 최대값)가 아님
- gpu_memory_utilization=0.3으로 10GB 할당
현실 데이터로 테스트
- 가변 길이 입력이 설정 문제를 드러냄
- 균일 테스트 데이터는 오해를 부르는 15 RPS 결과를 제공
vLLM 메트릭 모니터링
- KV 캐시 사용률
- 토큰당 디코드 시간
- 큐 깊이
- 설정 결정의 근거로 활용
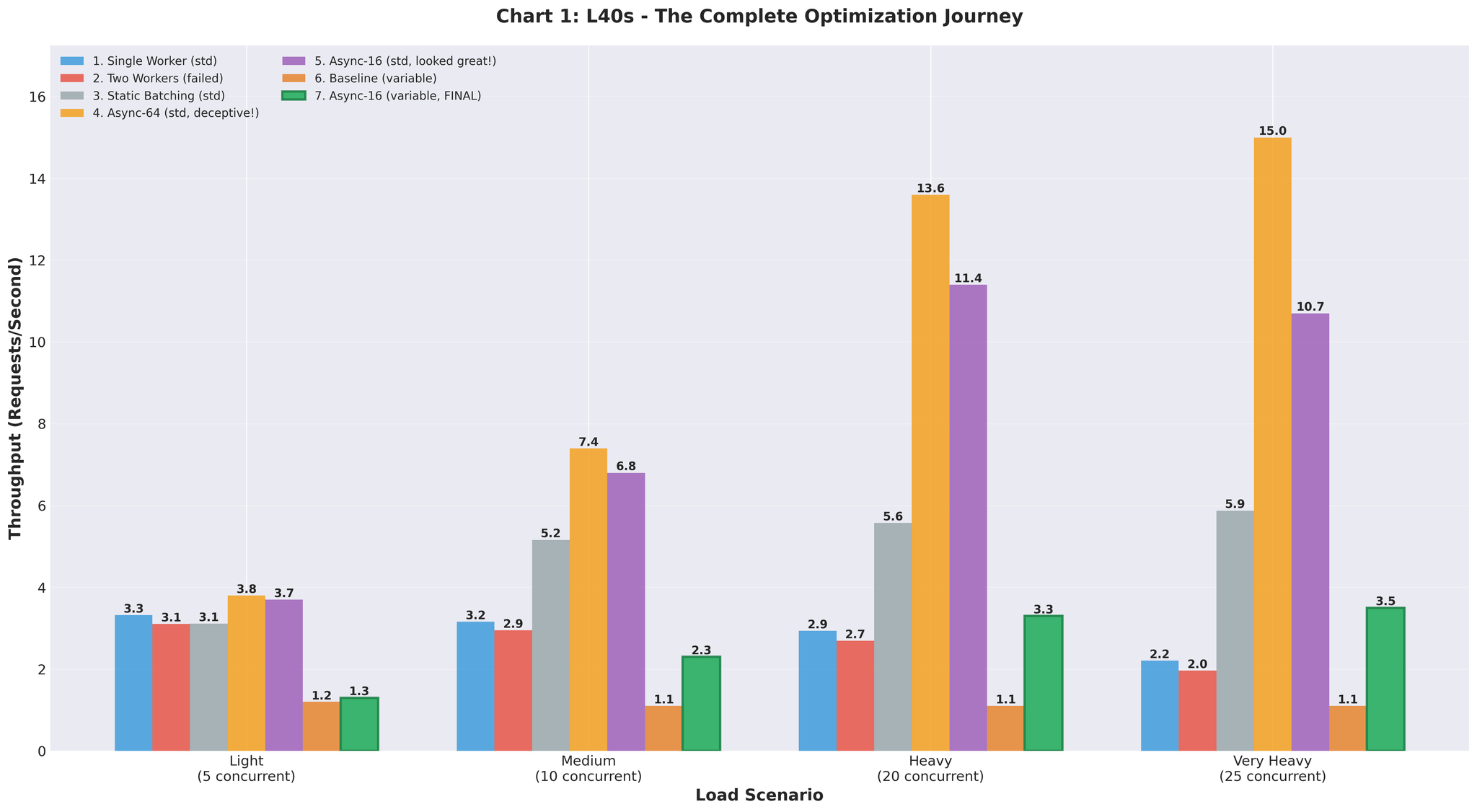
전체 개선 과정
| 접근 방식 | 처리량 | 베이스라인 대비 | 비고 |
|---|---|---|---|
| 베이스라인 (멀티프로세싱) | 2.2 RPS | - | IPC 오버헤드, GPU 경합 |
| 2개 워커 | 2.0 RPS | -9% | 오히려 악화 |
| 정적 배치 | 5.9 RPS | +168% | Head-of-Line 블로킹 |
| Async (64, 균일) | 15.0 RPS | +582% | 오해를 부르는 테스트 데이터 |
| Async (16, 가변) | 3.5 RPS | +59% | 현실적이나 튜닝 필요 |
| 최종 최적화 | 10.7 RPS | +386% | 스테이징 검증 |
| 프로덕션 | 16.4 RPS | +82% | 실제 트래픽, RTX 5090 |