FastAPI + 멀티프로세싱 구조에서 효율적인 GPU 활용을 방해하는 아키텍처 병목 지점 분석
문제
저희는 FastAPI와 vLLM을 사용하여 번역 마이크로서비스를 운영하고 있습니다. 높은 부하에서 서버 레이턴시 문제가 발생했지만, GPU 사용률 지표로는 설명이 되지 않았습니다.
GPU 사용률은 불안정한 패턴을 보였습니다. 93%까지 급등했다가 0%로 떨어지고, 다시 급등하는 반복이었습니다. 기대했던 안정적인 높은 사용률과는 거리가 멀었습니다.
핵심 질문: GPU에 유휴 시간이 있다면, 병목은 어디에 있는 것인가?
이 글에서는 FastAPI + 멀티프로세싱 구조에서 효율적인 GPU 활용을 방해하던 아키텍처 문제를 어떻게 찾아냈는지 설명합니다.
시스템 구성
번역 서비스는 로드 밸런서 뒤에서 여러 API 서버로 운영됩니다.
- 클라이언트: 웹, 모바일, 백엔드 서비스
- 프록시: 언어 쌍과 서버 상태에 따라 요청 라우팅
- API 서버: 각각 vLLM을 실행하는 다수의 FastAPI 인스턴스
이 글에서는 단일 API 서버의 내부 아키텍처와 병목에 초점을 맞춥니다.
API 서버 아키텍처
API 서버 1대의 내부 구조입니다.

구성 요소
1. FastAPI 메인 프로세스
| |
- async/await를 활용한 HTTP 요청 처리
- 단일 Python 프로세스, 하나의 이벤트 루프
- 논블로킹 I/O를 통한 동시 요청 처리
2. TranslationService
| |
- 번역 태스크 생성
- asyncio.Event를 가진 EventTask 객체 관리
- async/await와 멀티프로세싱 간의 브리지 역할
3. TranslationWorker (메인 프로세스)
| |
- 메인 프로세스에서 큐 생성 (워커와 공유)
- 태스크 분배를 위한 JoinableQueue
- 공유 태스크 상태를 위한 manager().dict()
- 결과 반환을 위한 Event queue
4. 워커 프로세스
| |
- 별도 프로세스로 스폰 (ctx.Process)
- 각 워커가 자체 vLLM 모델 인스턴스 로드
- 공유 translation_queue에서 풀
- 공유 event_queue를 통해 결과 반환
5. EventTask (비동기 동기화 메커니즘)
| |
- 멀티프로세싱과 async/await 간의 브리지
- 각 요청에 EventTask 할당
await event.wait()으로 워커 완료까지 코루틴 블로킹
요청 흐름
번역 요청 1건의 처리 과정입니다.

단계별 설명:
- 클라이언트 POST /translate → FastAPI가 비동기 코루틴 생성
- async translate() → TranslationService가 요청 처리
- create_task() → ID 생성, 공유 딕셔너리에 TranslationTask 생성
- queue.put(key) → 태스크 키 직렬화, 워커에 전송 (IPC 오버헤드)
- 워커: vllm.translate() → 워커가 번역 처리
- event_queue.put(result) → 결과 직렬화, 반환 (IPC 오버헤드)
- event.set() → EventTask 업데이트, 코루틴 깨우기
- await event.wait() 해제 → 결과 수신
- 응답 반환 → 클라이언트에 전송
오버헤드 포인트:
- 4단계: 직렬화 (태스크 키 pickle)
- 6단계: 직렬화 (결과 pickle)
- 8단계: 멀티프로세싱 결과에 대한 비동기 대기
- 전반적인 IPC 조율
베이스라인 성능
최적화 시도 전의 상태입니다.
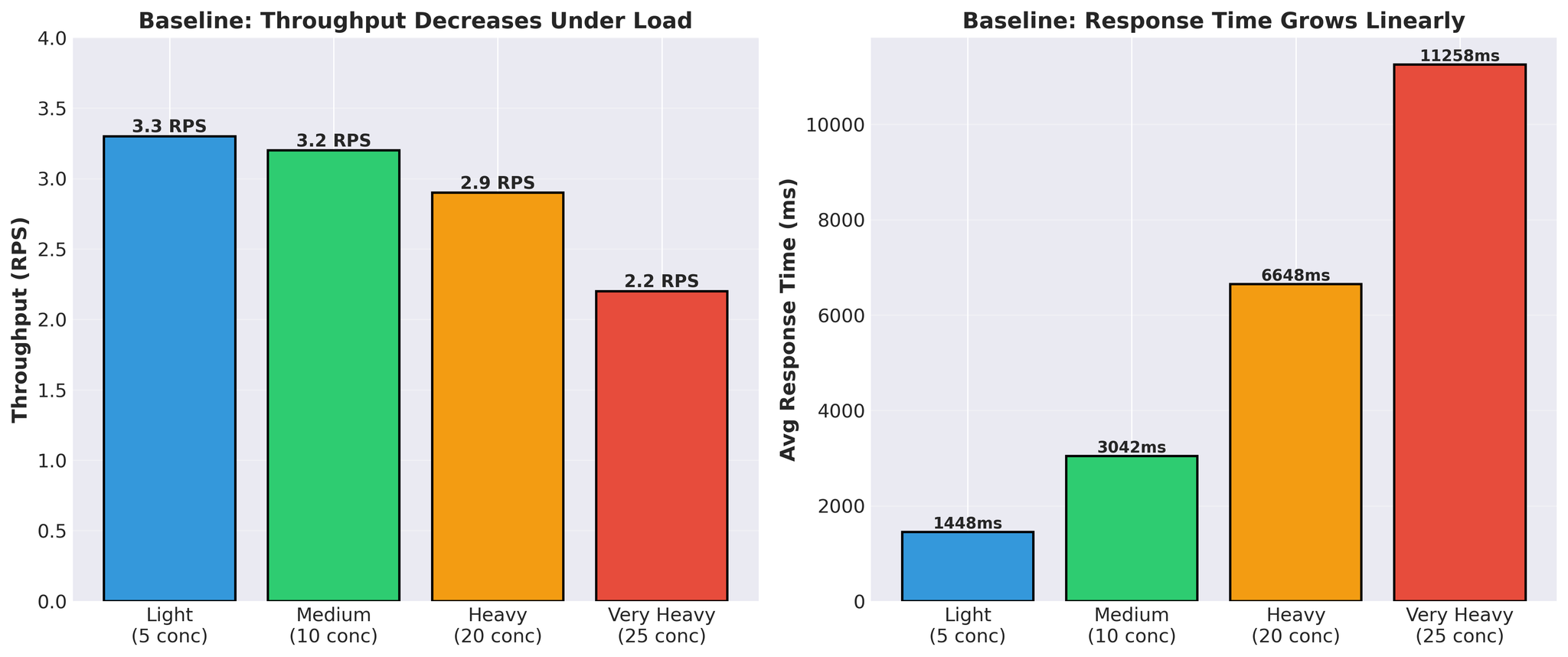
패턴:
- 응답 시간이 선형으로 증가 (1.4초 → 11.3초)
- 부하 증가 시 처리량 감소 (3.3 → 2.2 RPS)
- 실제 vLLM 번역 시간: 요청당 300~450ms
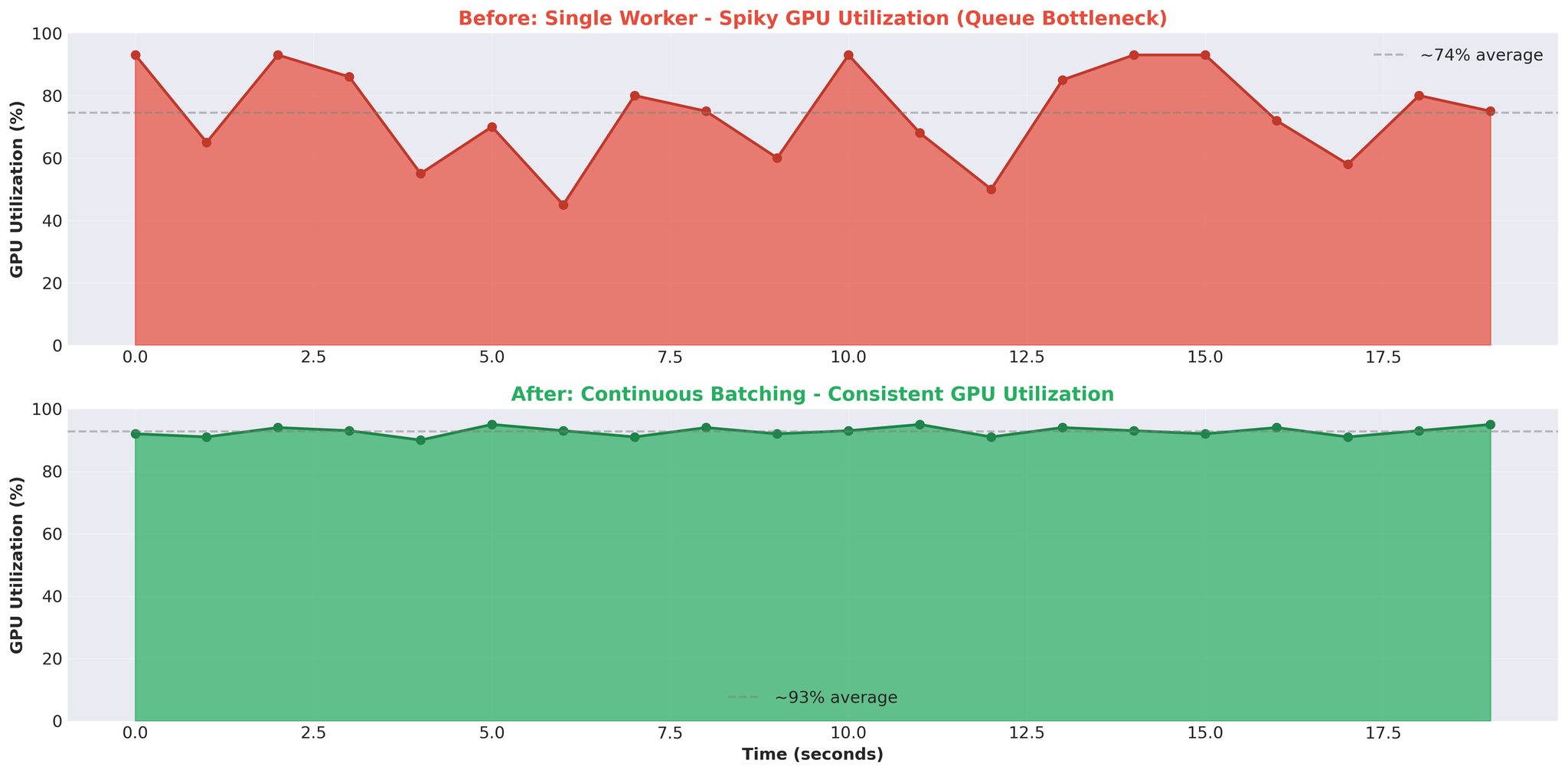
스파이크형 패턴: GPU가 사용 중과 유휴 상태를 번갈아 반복. 이는 GPU가 작업을 기다리고 있다는 의미이며, 연산 능력이 병목이 아님을 나타냅니다.
시도 1: 다중 워커
첫 번째 가설: 워커를 늘리면 병렬화가 개선될 것이다.
워커를 1개에서 2개로 늘렸습니다.
설정
| |
- 워커 1: 모델 A+B
- 워커 2: 모델 C
- 동일 GPU 공유
결과
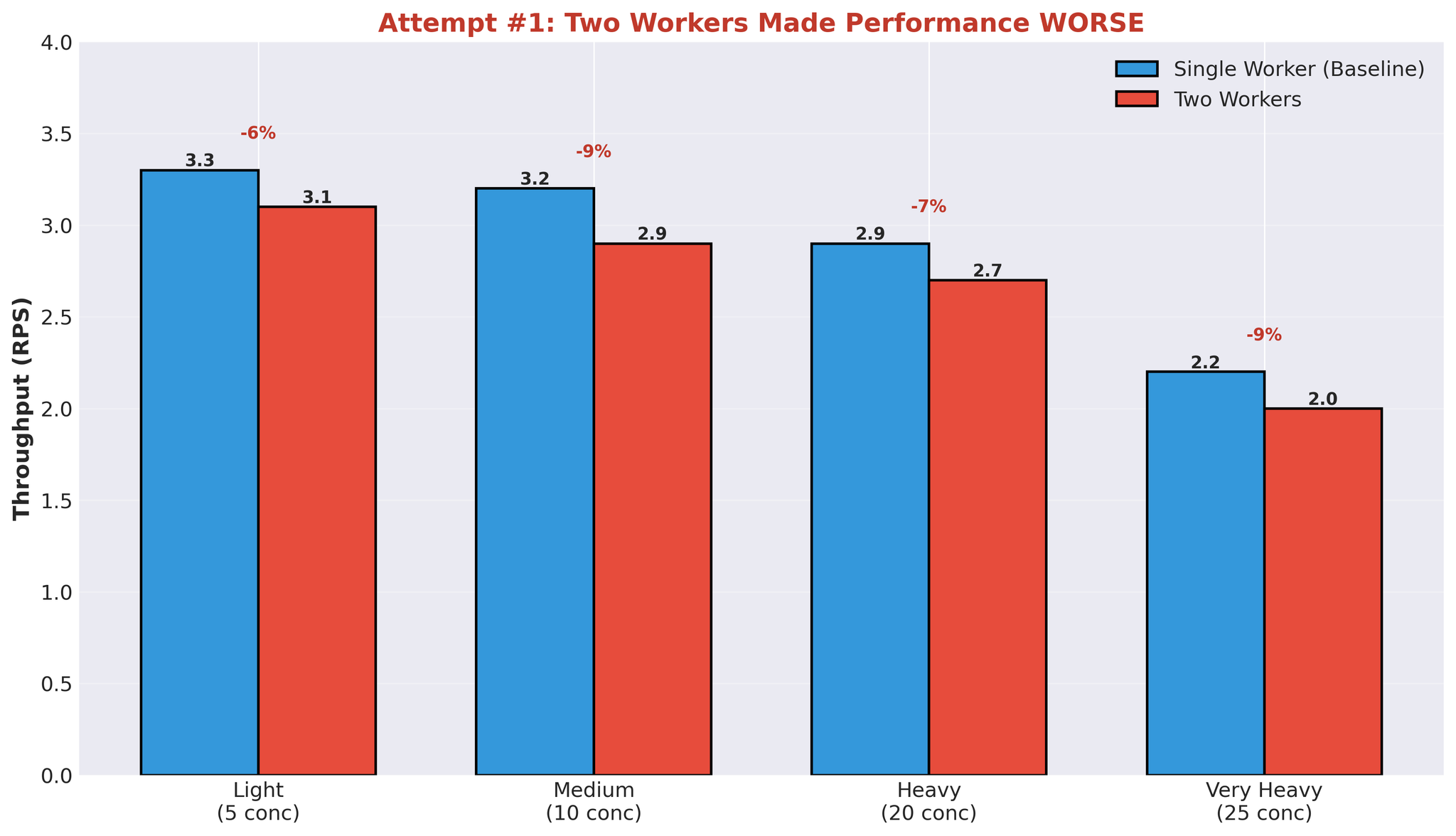
번역 시간 중앙값도 악화: 452ms → 2,239ms.
모든 부하 수준에서 성능이 떨어졌습니다.
다중 워커가 실패한 이유
GPU 동작 방식과 아키텍처를 이해하면 이 결과를 납득할 수 있습니다.

문제: 연산 리소스 경합
하나의 워커가 번역을 처리할 때:
- GPU 연산 능력의 약 90%를 사용
- 다른 워커는 나머지 용량을 효과적으로 병렬 사용 불가
- 워커가 GPU 가용성을 기다리게 됨
병렬화 이점이 없는 이유:
- 워커 1이 vLLM 생성 시작 → GPU 연산의 약 90% 사용
- 워커 2가 시작 시도 → GPU 연산의 약 10%만 사용 가능
- 워커 2는 느리게 실행되거나 대기
- 별도 프로세스임에도 실질적으로 순차 실행
추가 오버헤드:
- 프로세스 스폰 및 관리
- 워커 간 GPU 메모리 분할 (각각 모델 가중치 로드)
- IPC 큐 조율
- 프로세스 간 컨텍스트 스위칭
GPU는 기술적으로 여러 CUDA 커널을 동시에 실행할 수 있지만, 하나의 워커가 연산 능력의 약 90%를 사용하는 상태에서는 다른 워커가 효율적으로 병렬 실행할 수 있는 잔여 용량이 부족합니다.
기타 아키텍처 문제
다중 워커가 같은 리소스를 두고 경쟁하면:
- 컨텍스트 스위칭 오버헤드: OS가 워커 프로세스 간 전환
- 메모리 사용량 2배: 각 워커가 전체 모델 가중치를 로드
- 실효적 병렬성 없음: 병렬 아키텍처임에도 순차적 GPU 실행
모든 워커가 동일한 큐(translation_queue와 event_queue 공유)를 사용하므로 요청당 IPC 오버헤드는 일정합니다. 그러나 프로세스 관리, 컨텍스트 스위칭, 메모리 중복으로 인한 추가 오버헤드와 GPU 병렬화 이점의 부재가 결합되어 성능이 악화되었습니다.
식별된 병목
이 실험을 통해 핵심 문제를 파악했습니다.
1. IPC 직렬화 오버헤드
- 모든 요청에서: 태스크 직렬화 → 워커, 결과 직렬화 → 메인
- Python 멀티프로세싱 큐는 pickle 사용
- 요청마다 오버헤드 발생
2. 연산 리소스 경합
- 하나의 워커가 GPU 연산의 약 90% 사용
- 다른 워커의 효과적 병렬 실행 불가
- 멀티프로세싱에도 불구하고 순차 실행
3. Async/Await + 멀티프로세싱 브리지
- asyncio.Event가 멀티프로세싱 결과를 대기
- 스레드 기반 이벤트 큐 컨슈머
- 비동기 모델과 멀티프로세스 모델 간 조율 오버헤드
4. GPU 사이클 낭비
- 큐 작업 대기 중 GPU 유휴
- 스파이크형 사용률 (93% → 0% → 93%)
- 번역 시간 약 400ms, 전체 응답 시간은 11초 이상
- 대부분의 시간이 연산이 아닌 큐에서 소비
5. 아키텍처 복잡성
- FastAPI (async/await)
- TranslationService (브리지)
- TranslationWorker (조율)
- JoinableQueue (IPC)
- 워커 프로세스 (멀티프로세싱)
- Event queue (IPC)
- EventTask (비동기 동기화)
- vLLM (실제 처리)
각 레이어가 레이턴시를 추가했습니다.
핵심 인사이트
1. Async/Await + 멀티프로세싱 = 오버헤드
두 동시성 모델을 연결하려면 조율이 필요합니다:
- 비동기 대기를 위한 asyncio.Event
- 이벤트 큐 소비를 위한 스레드 풀
- 프로세스 경계에서의 직렬화
이 브리지에는 비용이 따릅니다.
2. 다중 프로세스 ≠ GPU 병렬화
워커 프로세스 추가가 GPU 활용도 향상으로 이어지지 않는 경우:
- 하나의 워커가 GPU 연산의 약 90% 사용
- 병렬 작업을 위한 잔여 용량 부족
- 멀티프로세싱 오버헤드에도 불구하고 순차 실행
3. 큐 오버헤드가 지배적
동시 요청 25건 기준:
- vLLM 번역 시간: 약 400ms
- 전체 응답 시간: 11,258ms
- 큐 오버헤드: 전체 시간의 약 97%
대부분의 시간이 연산이 아닌 큐와 조율에 사용되었습니다.
4. 스파이크형 GPU 사용률 = 아키텍처 문제
- 안정적인 GPU 사용률(예: 90~95%)은 연산 바운드 워크로드를 나타냄
- 스파이크형 패턴(93% → 0% → 93%)은 GPU가 작업을 기다리고 있음을 나타냄. 병목은 다른 곳에 있음(이 사례에서는 큐와 IPC)
결론
병목은 GPU 용량이 아니었습니다. 멀티프로세싱 아키텍처 자체가 원인이었습니다.
식별된 문제:
- 큐 직렬화로 인한 IPC 오버헤드
- 실효적 병렬성 없는 GPU 연산 경합
- Async/await + 멀티프로세싱 조율 오버헤드
- vLLM 처리가 아닌 큐 대기가 레이턴시의 대부분을 차지
증상:
- 스파이크형 GPU 사용률
- 큐 대기가 응답 시간의 대부분을 차지
- 워커 추가로 성능이 오히려 악화
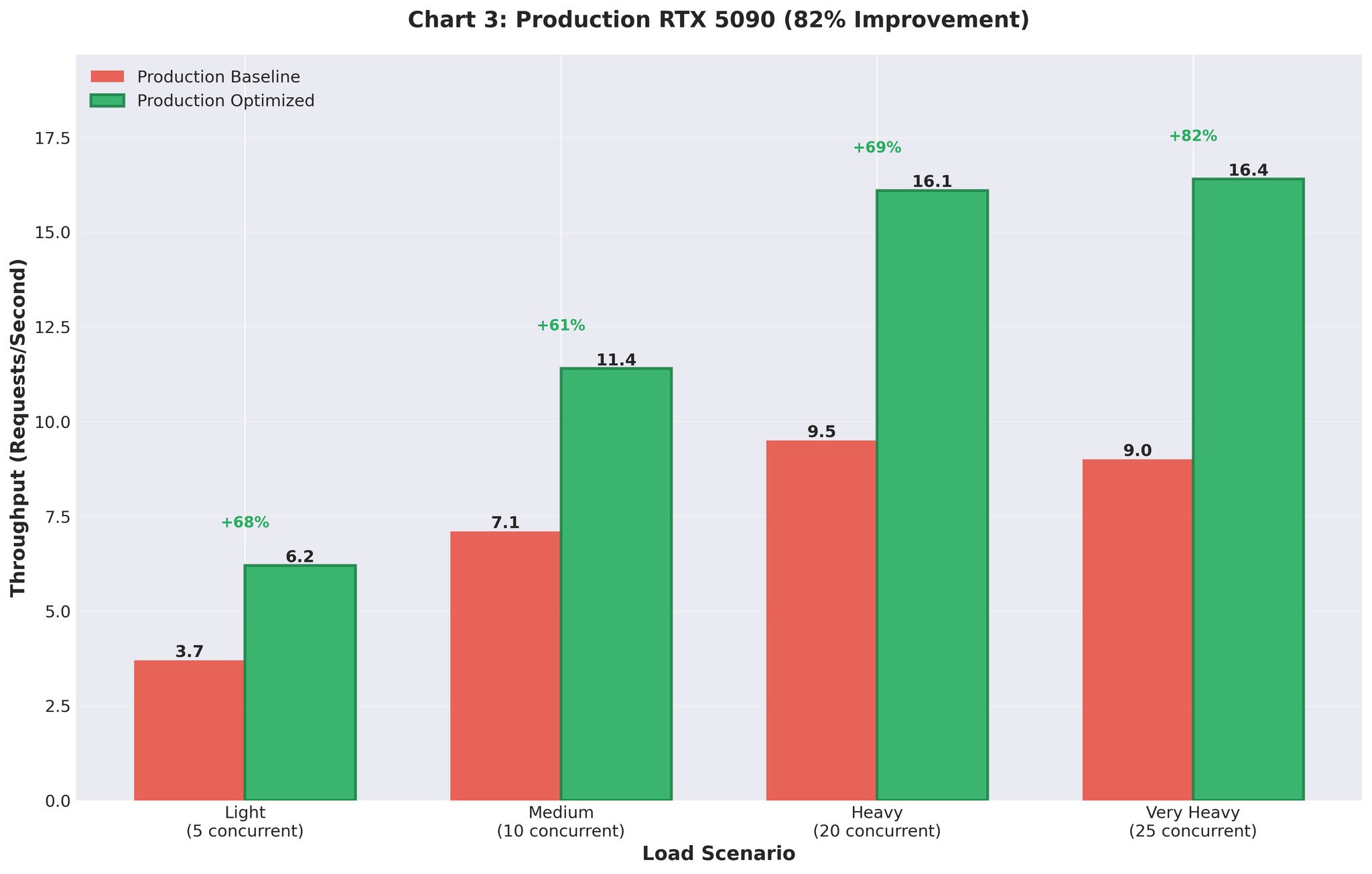
참고: Part 2에서는 멀티프로세싱을 제거하고 vLLM의 AsyncLLMEngine을 직접 사용하여 프로덕션에서 처리량 82% 향상을 달성한 해결책을 다룹니다.
다음 내용 미리보기:
- 멀티프로세싱 아키텍처 전면 제거
- vLLM의 AsyncLLMEngine을 FastAPI와 직접 통합
- Continuous Batching 구성 최적화
- 프로덕션 결과: 처리량 82% 향상