DER 분석과 실시간 애플리케이션 개발을 통한 화자 분리 프레임워크 비교 평가. Pyannote.audio와 Nvidia NeMo의 성능 차이를 검증합니다.
개요
본 논문에서는 최신 오픈소스 화자 분리 프레임워크인 Pyannote.audio와 Nvidia NeMo를 평가하고 비교합니다. 다양한 오디오 시나리오에서 Diarization Error Rate(DER), 실행 시간, GPU 리소스 사용량을 중심으로 평가를 진행합니다. 또한 OpenAI GPT-4-Turbo를 활용한 후처리 방식으로 분리 정확도를 향상시키는 방법도 살펴봅니다.
주요 결과:
- Nvidia NeMo는 2명 화자 시나리오에서 DER이 약 9% 낮음
- Pyannote.audio는 다수 화자(9명 이상) 시나리오에서 더 우수한 성능
- GPT-4-Turbo 후처리는 가능성을 보이나 오디오 컨텍스트 통합이 필요
- 실시간 화자 분리 웹 애플리케이션 시연
1. 서론
화자 분리란?
화자 분리(Speaker Diarization)는 오디오를 서로 다른 화자에 따라 분할하고 라벨을 붙이는 과정입니다. 주어진 오디오에서 “누가 언제 말했는가?“라는 질문에 답하는 기술로, 자동 음성 인식(ASR)과 결합하여 대화 분석의 핵심 도구로 활용됩니다.
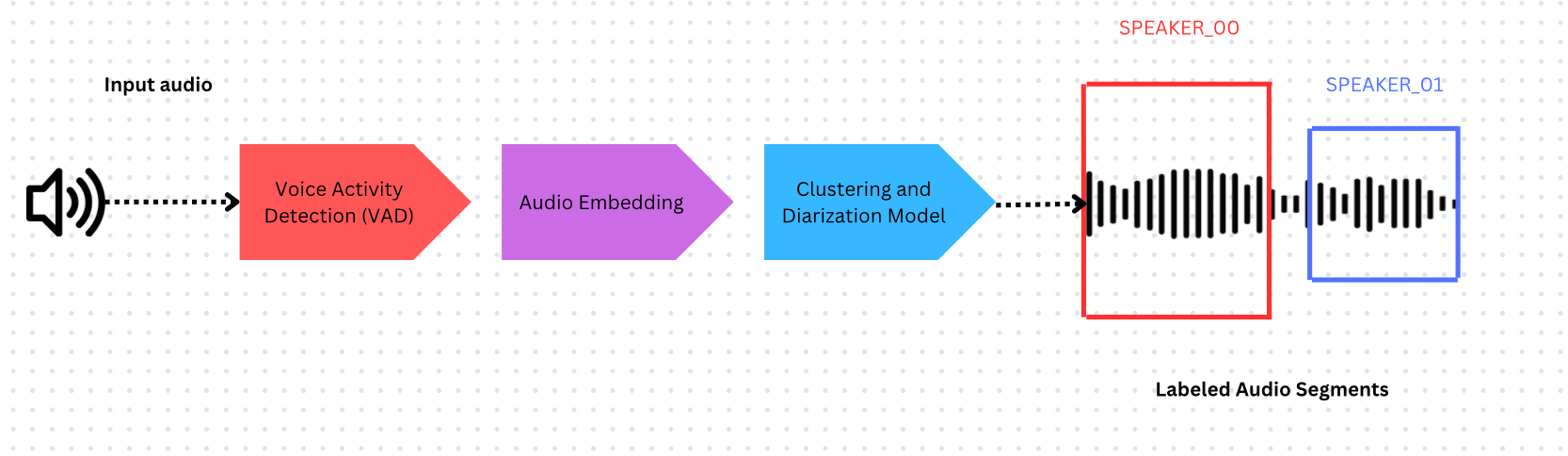
화자 분리 시스템의 구성 요소:
- 음성 활동 감지(VAD) - 발화가 발생하는 시점의 타임스탬프 식별
- 오디오 임베딩 모델 - 타임스탬프가 지정된 구간에서 임베딩 추출
- 클러스터링 - 임베딩을 그룹화하여 화자 수 추정
Pyannote.audio
Pyannote.audio는 PyTorch 기반의 화자 분리 및 화자 임베딩을 위한 오픈소스 Python 툴킷입니다.
Nvidia NeMo
Nvidia NeMo는 멀티스케일 세그멘테이션과 Neural Diarizer(MSDD 모델)를 사용하는 다른 접근 방식을 채택하여 화자 간 겹침 발화를 처리합니다.
멀티스케일 세그멘테이션
NeMo는 화자 식별 품질과 시간 해상도 간의 트레이드오프를 해결합니다:
- 긴 세그먼트 → 화자 표현 품질이 높지만 시간 해상도가 낮음
- 짧은 세그먼트 → 화자 표현 품질이 낮지만 시간 해상도가 높음
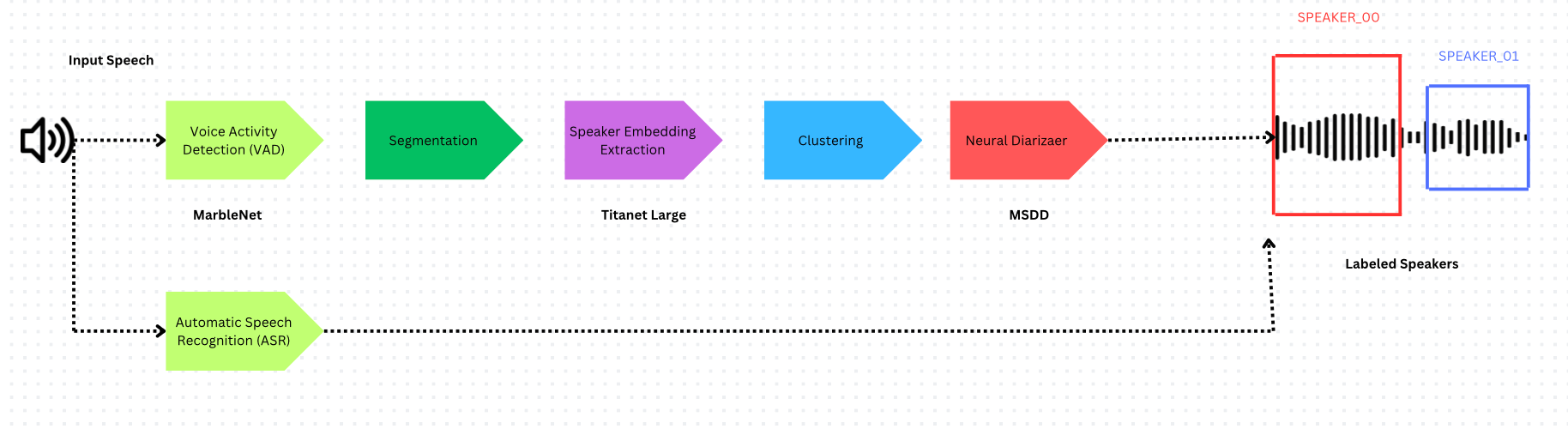
프레임워크 비교
| 구성 요소 | Pyannote.audio | Nvidia NeMo |
|---|---|---|
| VAD | Pyannote from SyncNet | Multilingual MarbleNet |
| 화자 임베딩 | ECAPA-TDNN | Titanet Large |
| 클러스터링 | Hidden Markov Model | Multi-scale Clustering (MSDD) |
2. 평가 방법
Diarization Error Rate(DER)
화자 분리의 표준 평가 지표로, 2000년 NIST에서 도입했습니다:
DER = (False Alarm + Missed Detection + Confusion) / Total
각 항목의 의미:
- False Alarm: 화자가 없는데 발화가 감지된 경우
- Missed Detection: 화자가 있는데 발화가 감지되지 않은 경우
- Confusion: 발화가 잘못된 화자에게 할당된 경우
참고: DER은 0에 가까울수록 오류가 적음을 의미합니다.
RTTM 파일 형식
Rich Transcription Time Marked(RTTM)는 화자 분리 출력의 표준 형식입니다:
SPEAKER obama_zach(5min).wav 1 66.32 0.27 <NA> <NA> SPEAKER_01 <NA> <NA>
주요 필드: 세그먼트 시작 시간(66.32), 지속 시간(0.27), 화자 라벨(SPEAKER_01)
3. 실험 환경
데이터셋
- 5분 오디오 - 2명의 화자(Obama-Zach 인터뷰), Audacity를 이용한 수동 어노테이션
- 9분 오디오 - VoxConverse 데이터셋의 9명 화자, 전문가가 작성한 정답 데이터 포함
하드웨어
- GPU: Nvidia GeForce RTX 3090
- Python의
time모듈을 사용하여 시간 측정
Pyannote.audio 코드
| |
Nvidia NeMo 코드
| |
4. 결과 및 분석
DER 결과 - 2명 화자(5분)
| 프레임워크 | DER |
|---|---|
| Pyannote.audio | 0.252 |
| Pyannote.audio(화자 사전 식별) | 0.214 |
| Nvidia NeMo | 0.161 |
| Nvidia NeMo(화자 사전 식별) | 0.161 |
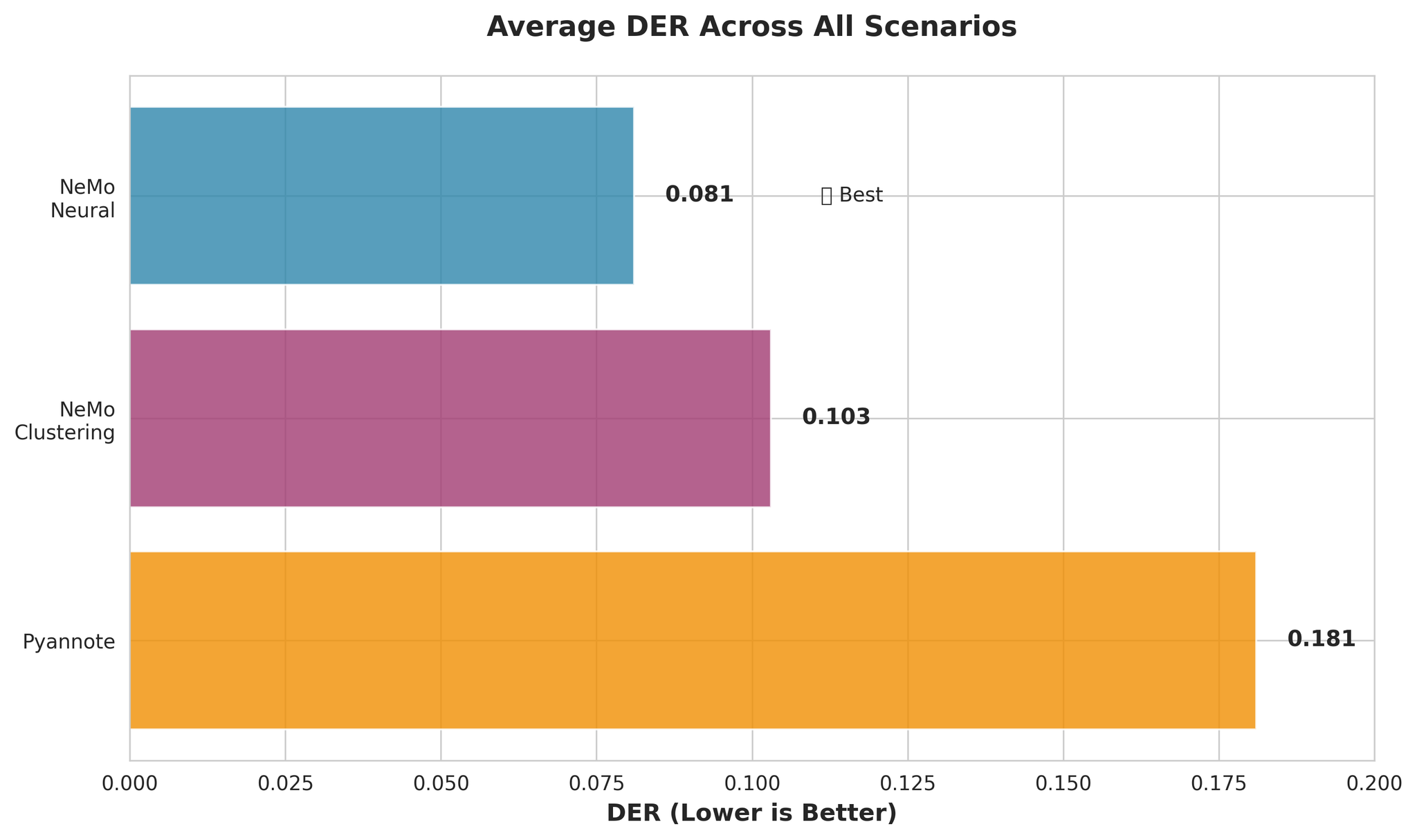
핵심: Nvidia NeMo는 2명 화자 시나리오에서 Pyannote.audio보다 약 9% 낮은 DER을 달성합니다.
DER 결과 - 9명 화자(9분)
| 프레임워크 | DER |
|---|---|
| Pyannote.audio | 0.083 |
| Pyannote.audio(화자 사전 식별) | 0.098 |
| Nvidia NeMo(화자 사전 식별) | 0.097 |
다수 화자 시나리오에서 Pyannote.audio는 Nvidia NeMo보다 약 1.4% 낮은 DER을 달성합니다.
GPT-4 후처리 결과
| 프레임워크 | GPT-4-Turbo DER | GPT-3.5 DER |
|---|---|---|
| Pyannote(5분, 2명 화자) | 0.427 | 0.494 |
| Nemo(5분, 2명 화자) | 0.179 | 0.544 |
| Pyannote(9분, 9명 화자) | 0.103 | 0.214 |
| Nemo(9분, 9명 화자) | 0.128 | 0.179 |
주의: GPT-4 후처리에서 DER이 더 높게 나타나는 이유는 오디오 데이터에 직접 접근할 수 없기 때문입니다. 화자 타이밍 정보와 오디오 컨텍스트를 제공하면 결과가 개선될 수 있습니다.
실행 시간 비교
| 프레임워크 | 5분 오디오 | 9분 오디오 |
|---|---|---|
| Pyannote.audio | 31.3초 | 44.5초 |
| Pyannote(화자 사전 식별) | 29.8초 | 41.5초 |
| Nvidia NeMo | 63.9초 | - |
| Nemo(화자 사전 식별) | 49.9초 | 108.2초 |
Nvidia NeMo는 Pyannote.audio에 비해 약 2배의 실행 시간이 소요됩니다.
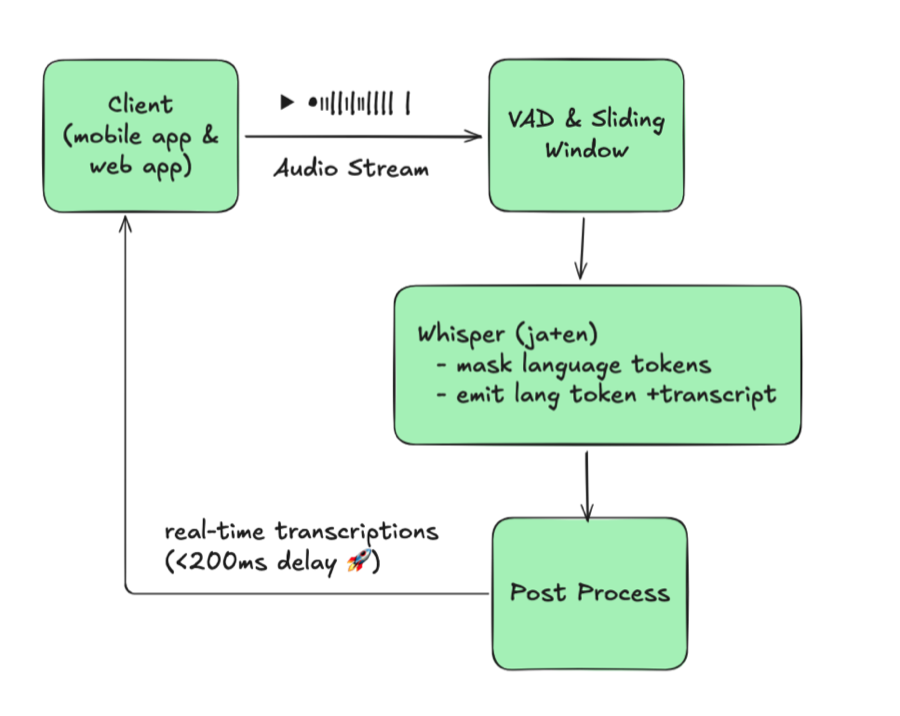
5. 실시간 애플리케이션
다음 기술을 활용하여 실시간 화자 분리 웹 애플리케이션을 개발했습니다:
- WebSockets를 통한 오디오 스트리밍
- FastAPI 기반 백엔드
- Pyannote.audio를 이용한 화자 분리
주요 구현 사항
더 나은 실시간 성능을 위해 30초 청크 대신 3초 청크를 사용합니다:
| |
결과 비교


변경된 청크 로직을 통해 타이밍 오류가 크게 줄어들고 화자 전환이 더 부드러워졌습니다.
6. 결론
주요 발견
- Nvidia NeMo는 짧은 오디오에서 화자 수가 적을 때 우수함(DER: 0.161 vs 0.252)
- Pyannote.audio는 화자 수가 많거나 사전 식별이 이루어진 경우 더 우수한 성능
- GPT-4 후처리는 가능성을 보이나 오디오 컨텍스트 통합이 필요
- 실행 시간: Pyannote.audio가 약 2배 빠름
- 실시간 애플리케이션: 청크 로직 개선으로 정확도 향상
향후 과제
- 비통화 시나리오에 맞춘 Nvidia NeMo 모델 조정
- GPT 후처리에 오디오 컨텍스트 통합
- 실시간 애플리케이션을 위한 화자 식별 임계값 최적화
- 화자 분리에 특화된 도메인 특화 LLM 탐색
7. 참고 문헌
- NIST Rich Transcription Evaluation (2022)
- Nvidia NeMo Documentation - Speaker Diarization
- Pyannote.audio GitHub Repository
- OpenAI GPT-4 Turbo Documentation
- VoxConverse Speaker Diarization Dataset
감사의 말
- Akinori Nakajima - VoicePing Corporation 대표이사
- Melnikov Ivan - VoicePing Corporation AI 개발자