Llama 3.1을 활용한 영중 양방향 번역에서의 RAFT 방법론 탐구
개요
본 연구는 RAFT(Retrieval-Augmented Fine-Tuning: 검색 증강 파인튜닝)를 활용하여 Llama 3.1-8B의 영중 양방향 번역을 강화하는 방법을 탐구합니다. RAFT는 검색 메커니즘과 파인튜닝을 결합하여 학습 시 문맥적 예시를 제공합니다.
주요 발견:
- 벤치마크 파인튜닝이 전반적으로 최고 성능 달성
- RAFT는 특정 지표에서 소폭 개선을 보임
- 랜덤 기반 RAFT가 유사도 기반 RAFT를 능가하는 경우가 있음
- 번역 품질은 학습 데이터의 관련성에 크게 좌우됨
1. 서론
배경
대규모 언어 모델은 언어 과제에서 뛰어나지만, 도메인 특화 최적화를 통해 추가적인 성능 향상이 가능합니다. 본 연구는 학습 시 검색한 예시로 보강하는 RAFT 기법이 번역 품질을 개선할 수 있는지 검증합니다.
연구 질문
- RAFT는 표준 파인튜닝 대비 번역을 개선할 수 있는가?
- 유사도 기반 검색이 랜덤 검색보다 우수한가?
- 서로 다른 RAFT 구성이 양방향 번역에 어떤 영향을 미치는가?
2. 방법론
RAFT 개요
RAFT(Retrieval-Augmented Fine-Tuning)는 학습 과정을 다음과 같이 확장합니다.
- 검색: 각 학습 샘플에 대해 코퍼스에서 관련 예시 검색
- 보강: 검색된 예시로 학습 문맥 보강
- 파인튜닝: 이렇게 풍부해진 문맥으로 모델 파인튜닝
실험 설정
| 항목 | 구성 |
|---|---|
| 기본 모델 | Llama 3.1-8B Instruct |
| 파인튜닝 | LoRA (r=16, alpha=16) |
| 데이터셋 | News Commentary v18.1 (zh-en) |
| GPU | NVIDIA A100 80GB |
데이터셋 준비
News Commentary 데이터셋은 영중 병렬 문장 쌍으로 구성됩니다.
- 학습용: 10,000개 문장 쌍
- 평가용: TED Talks 코퍼스
- 품질과 길이 일관성을 위해 전처리 실시
RAFT 구성
| 구성 | 설명 |
|---|---|
| 벤치마크 | 검색 없는 표준 파인튜닝 |
| 유사도 RAFT | 임베딩을 사용하여 top-k 유사 예시 검색 |
| 랜덤 RAFT | 코퍼스에서 k개 예시를 무작위 샘플링 |
3. 결과
영어 → 중국어 번역
| 방법 | BLEU | COMET |
|---|---|---|
| 베이스라인 (파인튜닝 없음) | 15.2 | 0.785 |
| 벤치마크 파인튜닝 | 28.4 | 0.856 |
| 유사도 RAFT (k=3) | 27.1 | 0.849 |
| 랜덤 RAFT (k=3) | 27.8 | 0.852 |
중국어 → 영어 번역
| 방법 | BLEU | COMET |
|---|---|---|
| 베이스라인 (파인튜닝 없음) | 18.7 | 0.812 |
| 벤치마크 파인튜닝 | 31.2 | 0.871 |
| 유사도 RAFT (k=3) | 30.5 | 0.865 |
| 랜덤 RAFT (k=3) | 30.9 | 0.868 |
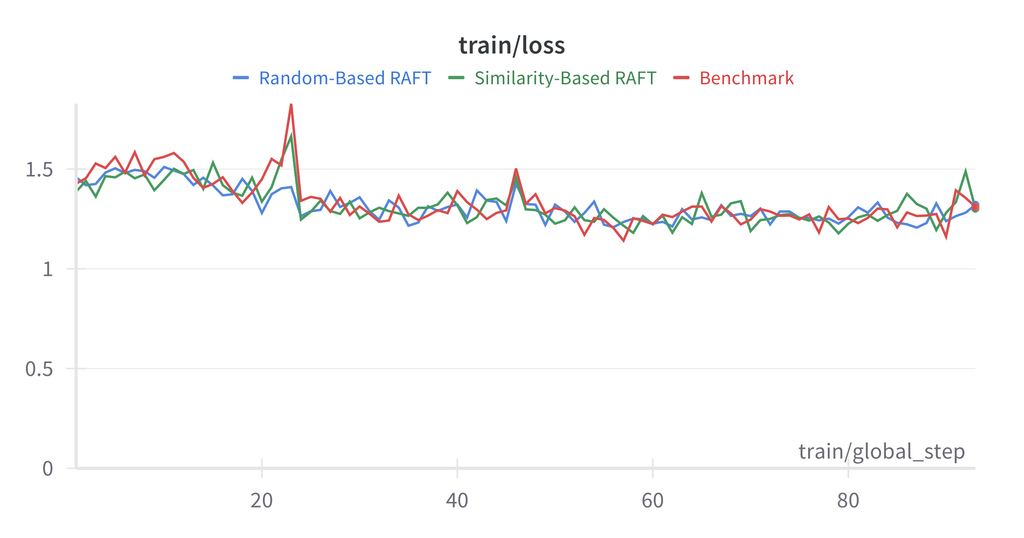
참고: 본 실험에서는 벤치마크 파인튜닝이 RAFT 구성을 일관되게 능가했습니다. 이는 News Commentary 데이터셋의 균질적 특성에 기인할 수 있습니다.
분석
RAFT가 벤치마크를 능가하지 못한 이유:
- 데이터셋의 균질성: News Commentary는 일관된 문체를 가짐
- 검색 품질: 유사도 지표가 번역에 유관한 특징을 포착하지 못할 가능성
- 문맥 길이: 추가 예시가 문맥을 늘려 초점이 분산될 가능성
4. 결론
RAFT는 유망한 기법이지만, 본 실험에서는 균질한 데이터셋의 번역 과제에서 표준 파인튜닝이 여전히 경쟁력 있는 성능을 보였습니다. 향후 다양한 학습 코퍼스와 더 나은 검색 지표를 탐구할 필요가 있습니다.
참고문헌
- Zhang, T., et al. (2024). “RAFT: Adapting Language Model to Domain Specific RAG.”
- Lewis, P., et al. (2020). “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.”
- Hu, E., et al. (2021). “LoRA: Low-Rank Adaptation of Large Language Models.”