Llama 3.1의 중영 번역 파인튜닝과 환각 완화 전략에 관한 연구
개요
대규모 언어 모델(LLM)은 자연어 처리 과제에서 뛰어난 성능을 보이고 있습니다. 본 연구에서는 Llama 3.1을 중국어-영어 기계번역용으로 파인튜닝하고, 학습 및 디코딩 전략을 통해 환각(hallucination) 문제를 해결합니다.
주요 결과:
- 파인튜닝 모델이 문서 수준 데이터에서 BLEU 40.8 달성 (베이스라인 19.6)
- COMET 0.891 (베이스라인 0.820)
- 긴 문맥의 번역에서 환각 현상 완화에 성공
- 문서 수준 성능을 향상시키면서 문장 수준 품질 유지
1. 배경
대규모 언어 모델
Llama와 같은 LLM은 자연어 처리를 혁신하며, 인간과 유사한 텍스트 이해 및 생성에서 놀라운 능력을 보여주고 있습니다. 특정 과제에 맞게 파인튜닝할 수 있어 기계번역 고도화에 적합합니다.
파라미터 효율적 파인튜닝 (LoRA)
LoRA(Low-Rank Adaptation)는 전체 모델 파라미터를 업데이트하지 않고도 파인튜닝을 가능하게 합니다.
- 사전 학습된 모델 파라미터를 고정
- 학습 가능한 저랭크 행렬을 삽입
- 학습 비용과 시간을 크게 절감
신경 기계번역과 환각
NMT에서의 환각이란 원문에 충실하지 않거나 조작된, 또는 의미 없는 콘텐츠를 말합니다.
| 유형 | 설명 |
|---|---|
| 내재적 환각 | 원문 대비 잘못된 정보를 포함하는 출력 |
| 외재적 환각 | 모델이 관련 없는 추가 콘텐츠를 생성 |
| 섭동 환각 | 입력의 미세한 변화에 대해 크게 다른 출력을 생성 |
| 자연 환각 | 학습 데이터의 노이즈에 기인 |
디코딩 전략
| 방법 | 설명 |
|---|---|
| 그리디 탐색 | 각 단계에서 확률이 가장 높은 토큰을 선택 |
| 빔 서치 | 확률이 높은 N개의 시퀀스를 고려 |
| 온도 샘플링 | 확률 분포의 날카로움을 조절 |
| Top-p 샘플링 | 누적 확률 임계값을 초과하는 토큰에서 선택 |
| Top-k 샘플링 | 확률이 높은 k개의 토큰에서 선택 |
2. 실험
데이터셋
| 데이터셋 | 문서 수 | 문장 수 | 단어 수 (원문/번역문) |
|---|---|---|---|
| NewsCommentary-v18.1 | 11,147 | 443,677 | 1,640만/970만 |
| Ted Talks | 22 | 1,949 | 5.1만/3.2만 |
평가 지표
- BLEU: Bilingual Evaluation Understudy - 참조 번역과 n-gram을 비교
- COMET: 인간 판단과 최고 수준의 상관관계를 가진 뉴럴 프레임워크
실험 환경
- 모델: Llama 3.1 8B Instruct
- GPU: NVIDIA A100 (80GB)
- 프레임워크: Unsloth (가속 학습)
파인튜닝 설정
| |
3. 결과
분포 내 성능 (문서 수준)
| 학습 샘플 수 | BLEU | COMET |
|---|---|---|
| 10 | 35.8 | 0.885 |
| 100 | 36.9 | 0.889 |
| 1,000 | 39.7 | 0.890 |
| 10,000 | 40.8 | 0.891 |
| 베이스라인 | 19.6 | 0.820 |
핵심: 파인튜닝을 통해 문서 수준 번역에서 베이스라인 대비 BLEU가 100% 이상 향상되었습니다.
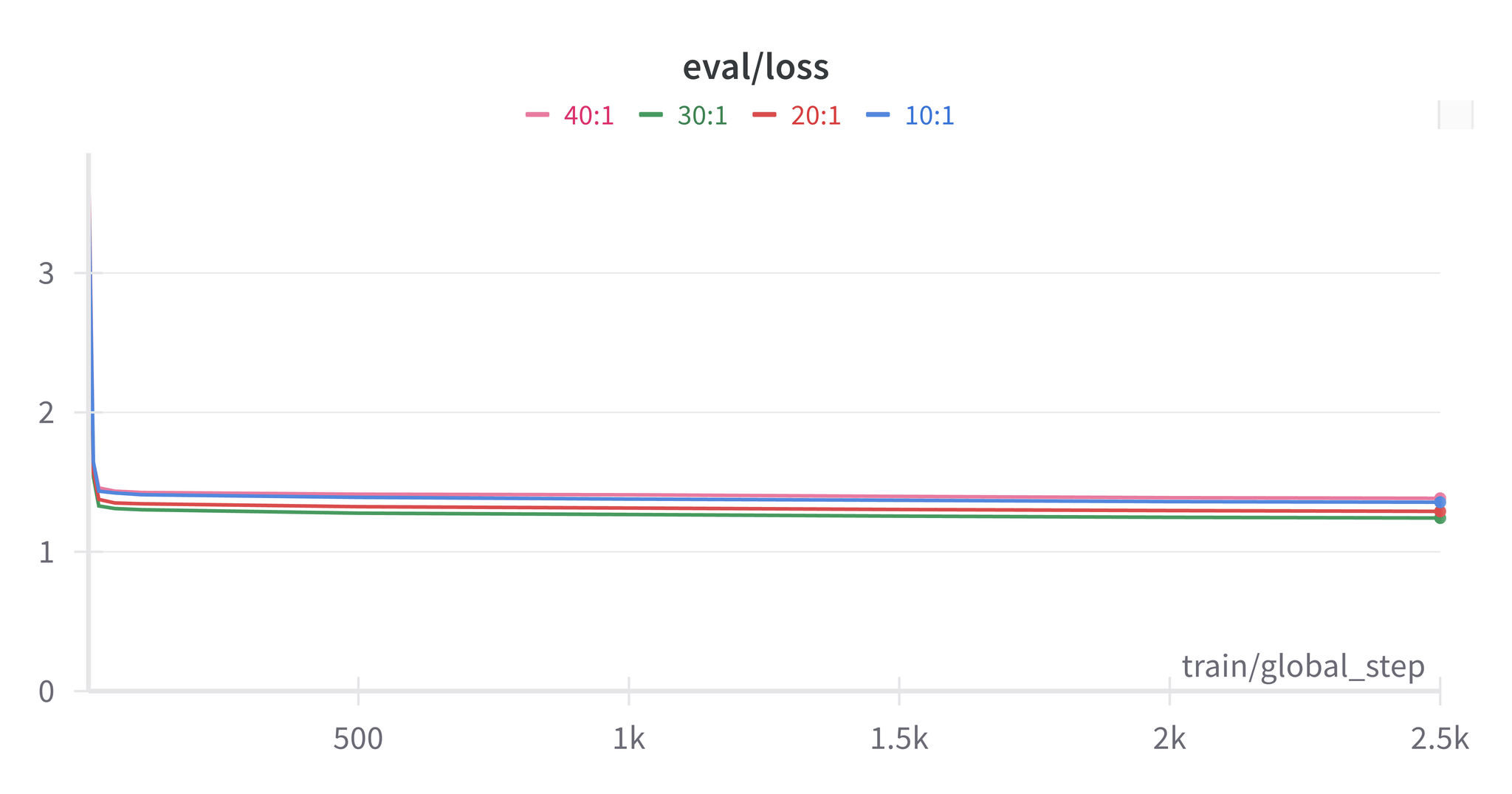
혼합 학습 최종 결과
문장 대 문서 비율 30:1 적용:
| 평가 수준 | 파인튜닝 BLEU | 파인튜닝 COMET | 베이스라인 BLEU | 베이스라인 COMET |
|---|---|---|---|---|
| 문서 수준 | 37.7 | 0.890 | 19.6 | 0.820 |
| 문장 수준 | 30.7 | 0.862 | 30.9 | 0.864 |
환각 분석
확인된 유형:
- 조기 중단: 번역 완료 전에 모델이 EOS 토큰을 생성
- 중복 콘텐츠: 문서 수준 모델이 번역 이외의 장황한 설명을 생성
완화 전략:
- EOS 토큰 확률 임계값 설정
- 문서/문장 수준 혼합 학습
- 데이터셋의 신중한 준비
주의: 문서 수준으로 파인튜닝된 모델은 암묵적 사전 지식을 포함한 장황한 출력을 생성하는 경향이 있으며, 사실에 기반하지만 주제에서 벗어난 콘텐츠를 생성하는 경우가 있습니다.
4. 결론
적절한 데이터셋 준비와 파인튜닝 기법을 통해 다음이 가능합니다.
- 번역 품질의 대폭 향상 (BLEU 2배 개선)
- 환각 문제 완화
- 문서 수준 성능 향상과 문장 수준 품질 유지의 양립
- 보다 신뢰성 있고 일관된 번역 생성
5. 향후 과제
- 다양한 입력 시나리오(문체, 문화적 배경, 대화 주제)를 다루는 데이터셋 준비
- 편향을 방지하기 위한 학습 데이터 콘텐츠 유형의 균형 조정
- 후처리 방법을 통한 고유명사 오류 해결
- 추가적인 환각 완화 기법 탐구
참고문헌
- Kocmi, T., et al. (2022). “Findings of the 2022 conference on machine translation (WMT22).”
- Hu, E., et al. (2021). “LoRA: Low-Rank Adaptation of Large Language Models.”
- Meta AI. (2024). “Llama 3.1 Model Documentation.”
- Ji, Z., et al. (2023). “Survey of Hallucination in Natural Language Generation.”