개요
본 연구에서는 기계번역 품질을 정확하게 평가하는 동시에, 사람 번역에 필적하는 수준으로 정확도를 높이는 방법을 탐구합니다. 5개의 서로 다른 벤치마크 번역 모델을 사용하여 3가지 평가 지표로 성능을 측정하고, 선행 연구에서 얻은 인사이트를 바탕으로 모델 정확도 향상에 힘쓰고 있습니다.
목차
- 서론
- 데이터셋
- 기계번역 정확도 평가 방법
- 3.1. BLEU 점수
- 3.2. BLEURT 점수
- 3.3. COMET 점수
- 5가지 기본 기계번역 모델과 정확도
- 4.1. Azure 기본 모델
- 4.2. Azure 커스텀 모델
- 4.3. DeepL 모델
- 4.4. Google 번역
- 4.5. GPT-4 모델
- 4.6. 비교 및 결론
- 기계번역 정확도 개선
- 5.1. GPT-4의 인컨텍스트 학습
- 5.2. 하이브리드 모델
- 5.3. 데이터 정제 도구로서의 GPT-4
- 결론
- 참고문헌
1. 서론
AI 기술의 발전, 특히 OpenAI의 ChatGPT 등장 이후 AI 산업에 대한 신뢰가 빠르게 높아지고 있습니다. 자연어 처리의 핵심 기술인 기계번역의 중요성은 갈수록 커지고 있습니다.
본 논문은 다양한 평가 지표를 사용하여 5개의 기본 번역 모델을 평가하고, 이들 모델의 정확도를 최대한 높이기 위한 방법을 탐구합니다.
2. 데이터셋
본 연구는 Hugging Face에서 제공하는 Opus100 (ZH-EN) 데이터셋을 중심으로 진행됩니다. 이 데이터셋은 다양한 분야에 걸친 100만 건의 중국어-영어 번역 쌍으로 구성되어 있어 번역 모델 학습에 적합합니다.

참고: 데이터셋 내에 번역 오류가 포함되어 있다는 점을 인지해야 합니다. 이러한 오류는 학습 정확도를 낮추는 것처럼 보일 수 있으나, 동시에 오버피팅 방지에도 기여합니다.
또한 Azure AI 플랫폼에 통합하기 전에 각 문장에 포함된 비정상적인 기호를 제거하는 전처리 단계가 필요합니다.
3. 기계번역 정확도 평가 방법
수많은 번역 모델 가운데 특정 목적에 가장 적합한 모델을 선택하는 것은 쉽지 않습니다. 번역 모델을 평가하는 기본 접근법은 크게 두 가지입니다.
- 전통적 방법: BLEU 점수
- 뉴럴 기반 지표: BLEURT 점수 및 COMET 점수
3.1 BLEU 점수
BLEU(Bilingual Evaluation Understudy)는 한 자연어에서 다른 자연어로 기계번역된 텍스트의 품질을 평가하는 알고리즘입니다(Papineni et al., 2002).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import nltk
bleu_scores = []
for reference, pre in zip(reference_translations, prediction):
reference_tokens = nltk.word_tokenize(reference.lower())
pre_tokens = nltk.word_tokenize(pre.lower())
if not reference_tokens or not pre_tokens:
continue
bleu_score = nltk.translate.bleu_score.sentence_bleu(
[reference_tokens], pre_tokens,
smoothing_function=nltk.translate.bleu_score.SmoothingFunction().method2)
bleu_scores.append(bleu_score)
average_bleu_score = sum(bleu_scores) / len(bleu_scores)
print("Average BLEU score:", average_bleu_score)
|
7가지 스무딩 함수
| 함수 | 설명 |
|---|
| Smoothing Function 1 | 가법(라플라스) 스무딩 - 제로 확률을 방지하기 위해 상수값 추가 |
| Smoothing Function 2 | NIST 스무딩 - 참조문 길이에 따른 페널티 도입 |
| Smoothing Function 3 | Chen and Cherry - 후보 번역 길이에 따라 적응 |
| Smoothing Function 4 | JenLin - 가법적 방법과 조정 방법의 균형 |
| Smoothing Function 5 | Gao and He - 짧은 번역에 대한 편향 보정 |
| Smoothing Function 6 | 베이지안 - 긴 문장에 대해 견고한 추정 제공 |
| Smoothing Function 7 | 기하평균 - n-gram 정밀도의 기하평균 산출 |
주의: BLEU에는 한계가 있습니다. 어순이나 구문을 고려하지 않으며, n-gram 일치에만 의존하기 때문에 유창성, 관용 표현, 문법, 전체적인 일관성을 포착하지 못합니다.
3.2 BLEURT 점수
BLEURT는 자연어 생성을 위한 평가 지표입니다. 참조문과 후보문 쌍을 입력으로 받아 유창성과 의미 보존 정도를 나타내는 점수를 반환합니다(Sellam, 2021).
1
2
3
4
5
6
7
8
| from bleurt import score
checkpoint = "/path/to/BLEURT-20"
scorer = score.BleurtScorer(checkpoint)
scores = scorer.score(references=reference_translations, candidates=prediction)
total_score = sum(scores) / len(scores)
print("Total Score:", total_score)
|
팁: BLEURT를 사용하려면 TensorFlow를 먼저 설치해야 합니다.
3.3 COMET 점수
COMET는 다국어 기계번역 평가 모델 학습을 위한 뉴럴 프레임워크로, 번역 품질에 대한 사람의 판단을 예측하도록 설계되었습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| from comet import download_model, load_from_checkpoint
model_path = download_model("Unbabel/wmt22-comet-da")
model = load_from_checkpoint(model_path)
data = []
for src, pre, reference in zip(source_sentences, preds, reference_translations):
data.append({
"src": src,
"mt": pre,
"ref": reference
})
model_output = model.predict(data, batch_size=8, gpus=0)
print(model_output)
|
4. 5가지 기본 기계번역 모델과 정확도
4.1 Azure 기본 모델
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| import requests, uuid, json
endpoint = ""
subscription_key = ""
location = ""
path = '/translate'
constructed_url = endpoint + path
params = {
'api-version': '3.0',
'from': 'zh',
'to': 'en'
}
headers = {
'Ocp-Apim-Subscription-Key': subscription_key,
'Ocp-Apim-Subscription-Region': location,
'Content-type': 'application/json',
'X-ClientTraceId': str(uuid.uuid4())
}
body = []
for i in source_sentences:
body.append({'text': i})
request = requests.post(constructed_url, params=params, headers=headers, json=body)
response = request.json()
|
4.2 Azure 커스텀 모델
Azure 커스텀 모델은 추가 데이터셋을 사용하여 Azure 기본 모델을 추가 학습시킨 개선 버전입니다. Azure 플랫폼에서의 커스텀 모델 BLEU 점수는 39.45입니다.
참고: 커스텀 모델을 사용할 때는 API 호출 시 사용할 수 있도록 Azure 플랫폼에 배포해야 합니다.
4.3 DeepL 모델
DeepL 번역기는 합성곱 신경망과 영어 피벗을 활용하는 뉴럴 기계번역 서비스입니다.
1
2
3
4
5
6
7
8
| import deepl
API_KEY = 'your-api-key'
source_lang = 'ZH'
target_lang = 'EN-US'
translator = deepl.Translator(API_KEY)
results = translator.translate_text(source_sentences, source_lang=source_lang, target_lang=target_lang)
|
4.4 Google 번역
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| import requests
def translate_texts(texts, target_language):
api_key = 'your-api-key'
url = 'https://translation.googleapis.com/language/translate/v2'
translations = []
for text in texts:
params = {
'key': api_key,
'q': text,
'target': target_language
}
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
translated_text = data['data']['translations'][0]['translatedText']
translations.append(translated_text)
return translations
|
4.5 GPT-4 모델
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| import openai
def translate_text(text_list):
openai.api_key = 'your-api-key'
translations = []
for text in text_list:
messages = [
{"role": "system", "content": "You are a translation assistant from Chinese to English. Some rules to remember:\n\n- Do not add extra blank lines.\n- It is important to maintain the accuracy of the contents, but we don't want the output to read like it's been translated. So instead of translating word by word, prioritize naturalness and ease of communication."},
{"role": "user", "content": text}
]
response = openai.ChatCompletion.create(
model='gpt-4',
messages=messages,
max_tokens=100,
temperature=0.7,
timeout=30
)
choices = response['choices']
if len(choices) > 0:
translation = choices[0]['message']['content']
translations.append(translation)
return translations
|
주의: GPT-4는 다른 4개 모델에 비해 응답 속도가 느린 편입니다. 또한 토큰 수가 과도할 경우 오버로드가 발생할 수 있습니다.
4.6 비교 및 결론
평가 결과를 기반으로:
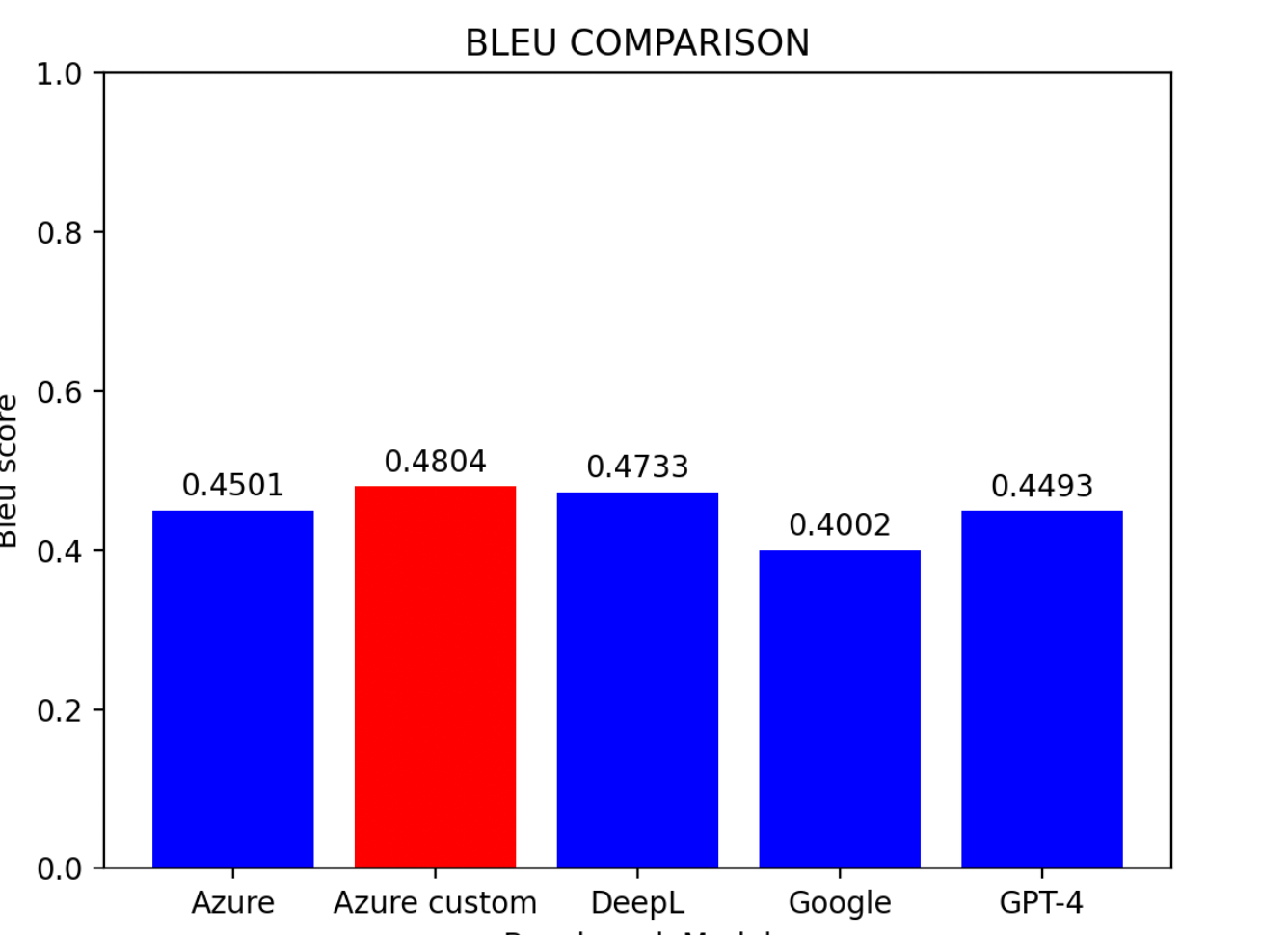
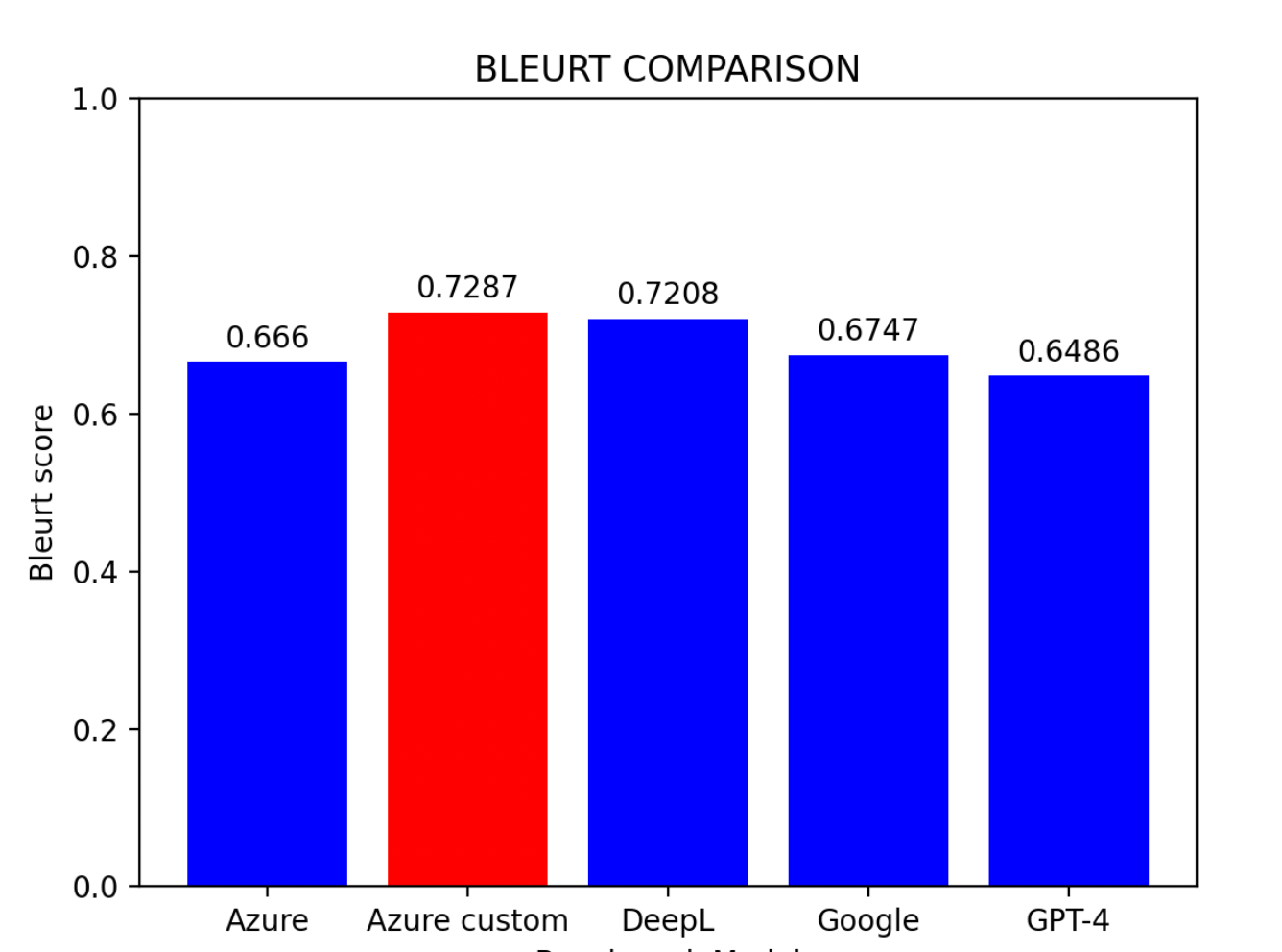
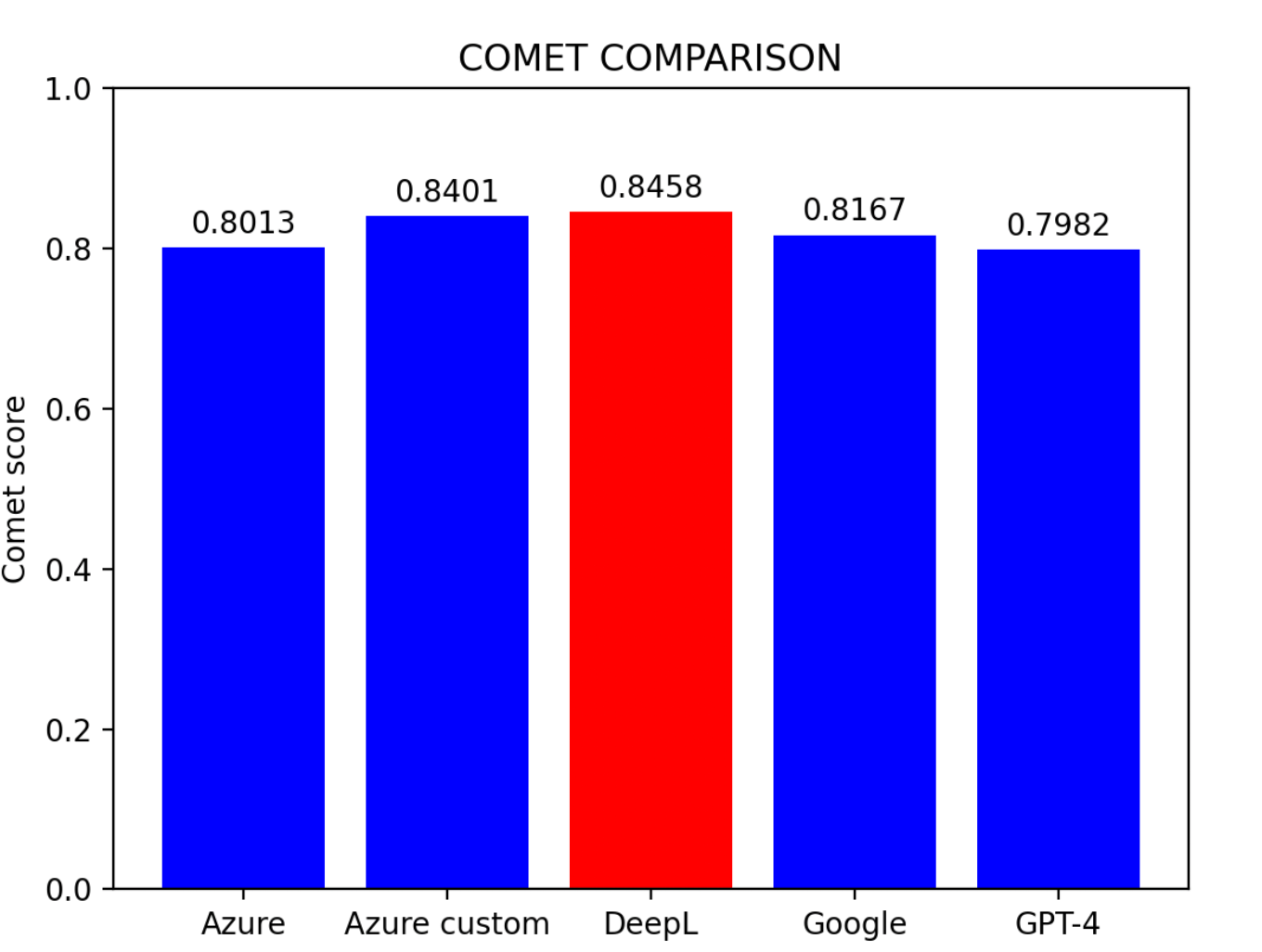
주요 발견사항:
- Azure 커스텀 모델이 가장 우수한 성능을 보임
- DeepL이 근소한 차이로 2위
- Azure 기본 모델이 3위
- Google 번역과 GPT-4는 비슷한 수준
팁: 사전 학습 환경이 없는 사용자에게 DeepL은 현재 중국어-영어 번역에서 가장 효과적인 모델입니다.
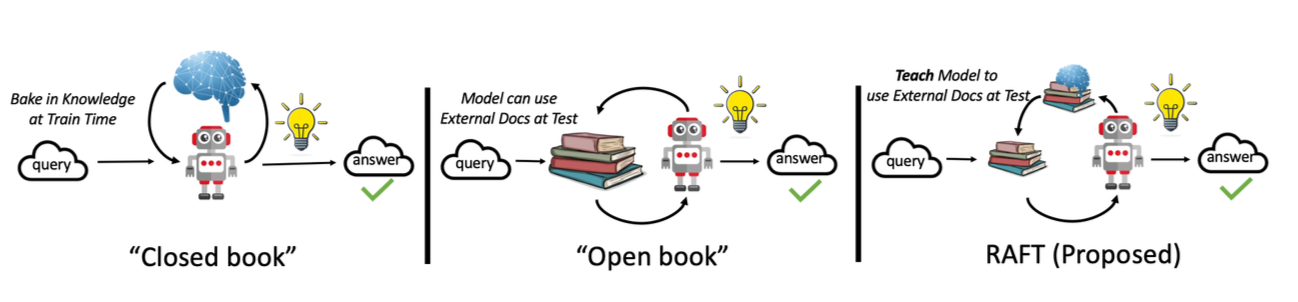
5. 기계번역 정확도 개선
번역 정확도를 개선하기 위한 3가지 접근법을 검토했습니다.
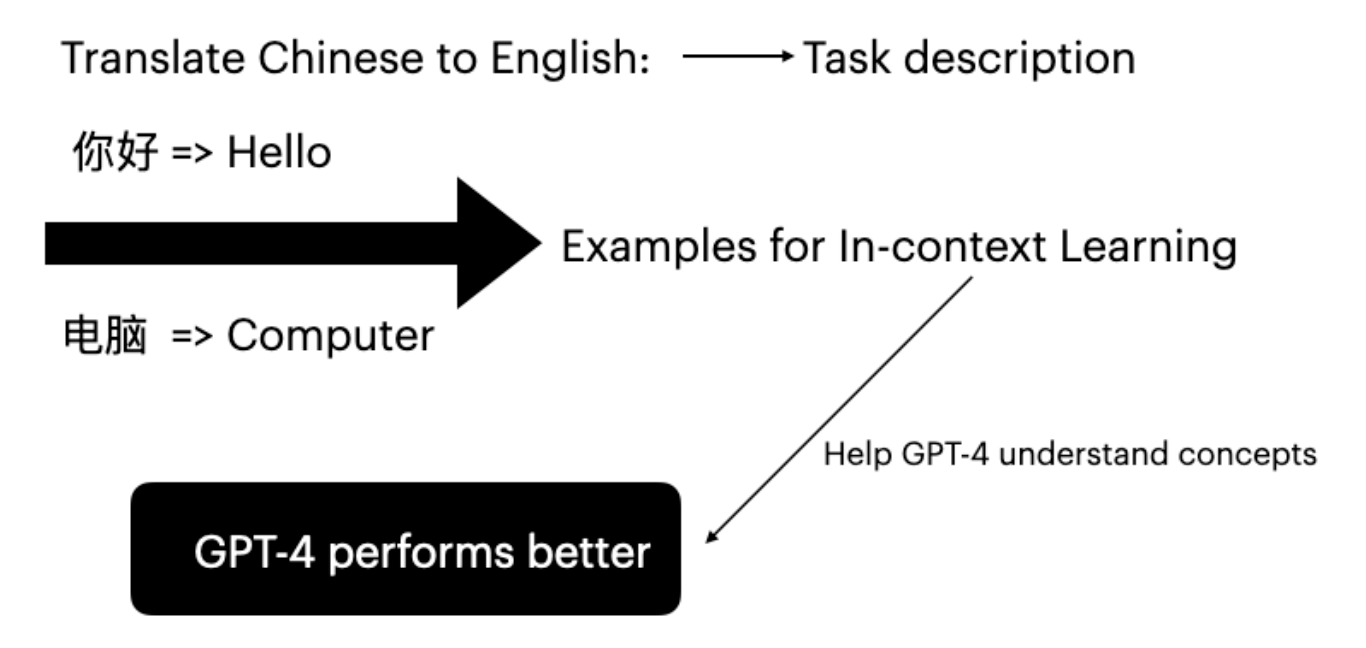
5.1 GPT-4의 인컨텍스트 학습
대규모 언어 모델은 프롬프트에 특정 과제 예시를 제공하는 인컨텍스트 학습을 통해 성능을 향상시킬 수 있습니다(Brown et al., 2020).
결과: BLEURT 점수가 0.6486에서 0.6755로 향상되어 인컨텍스트 학습의 효과가 입증되었습니다.
5.2 하이브리드 모델
하이브리드 임계값 모델은 특정 임계값을 설정하고, 특정 문장이 그 임계값에 미달할 경우 다른 모델로 재번역합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| import requests, uuid, json
import openai
from comet import download_model, load_from_checkpoint
def translate_with_fallback(text):
translation_from_Azure = Azure_translation(text)
model_path = download_model("Unbabel/wmt22-comet-da")
model = load_from_checkpoint(model_path)
refined_translation = []
indices_to_correct = []
for i in range(len(translation_from_Azure)):
data = [{
"src": source_sentences[i],
"mt": translation_from_Azure[i],
"ref": reference_translations[i]
}]
res = model.predict(data, batch_size=1, gpus=0)
if res.scores[0] < 0.81:
indices_to_correct.append(i)
sentences_to_correct = [source_sentences[i] for i in indices_to_correct]
corrected_sentences = gpt_translation(sentences_to_correct)
corrected_index = 0
for i in range(len(translation_from_Azure)):
if i in indices_to_correct:
refined_translation.append(corrected_sentences[corrected_index])
corrected_index += 1
else:
refined_translation.append(translation_from_Azure[i])
return refined_translation
|
하이브리드 모델의 결론
- 최적 임계값은 COMET 점수와 일치함
- Azure 커스텀 + DeepL 또는 DeepL + GPT-4 조합이 최고 성능
- 거의 모든 하이브리드 모델이 단일 모델을 능가함
- 임계값을 높인다고 반드시 점수가 향상되는 것은 아님
5.3 데이터 정제 도구로서의 GPT-4
GPT-4를 사용하여 데이터셋을 전처리하고 부정확한 번역을 수정할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| import openai
import json
pair = {}
for zh, en in zip(source_sentences, reference_translations):
pair[zh] = en
def translate_text(pair):
openai.api_key = 'your-api-key'
translations = []
for zh, en in pair.items():
messages = [
{"role": "system", "content": "You are a Chinese to English translation corrector. You need to modify the incorrect English translations below and correct it by given Chinese sentences, please remember not to use English abbreviations and not add extra blank lines. Fix weird punctuation. And the result should be English sentences only"},
{"role": "user", "content": json.dumps({"zh": zh, "en": en})}
]
response = openai.ChatCompletion.create(
model='gpt-4',
messages=messages,
max_tokens=100,
temperature=0.7,
timeout=30
)
choices = response['choices']
if len(choices) > 0:
model_response = choices[0]['message']['content']
translations.append(model_response)
return translations
|
팁: GPT-4를 활용하여 원문과 번역문 모두를 정제하는 것은 효과적입니다. 정제된 데이터셋으로 학습한 Azure 기본 모델은 정제되지 않은 데이터셋에서의 DeepL 성능에 필적하는 수준에 도달할 수 있습니다.
6. 결론
본 논문에서는 3가지 평가 지표와 5개 벤치마크 모델을 활용하여 기계번역 정확도와 개선 방법을 조사했습니다.
핵심 결론:
- DeepL이 중국어-영어 번역에서 가장 뛰어난 성능을 보임
- Azure 기본 모델은 충분한 데이터와 적절한 학습을 통해 높은 성능 달성 가능
- 서로 다른 번역 엔진을 결합한 하이브리드 모델이 정확도를 향상시킴
- GPT-4 데이터 정제가 데이터셋 품질을 개선하여 모델 성능 향상으로 이어짐
주의: 본 연구에는 한계가 있습니다. 수동 검수를 통해 높은 점수를 받았음에도 번역 품질이 기대에 미치지 못하는 사례가 확인되었으며, 일부 정확도 개선 방법이 오히려 점수를 하락시키는 경우도 있었습니다.
7. 참고문헌
Papineni, K., Roukos, S., Ward, T., & Zhu, W. J. (2002). BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics (ACL).
Thibault Sellam (2021). BLEURT
Tom Brown et al. (2020). Language models are few-shot learners.
Daniel Bashir (2023). In-Context Learning, in Context. The Gradient.
Amr Hendy et al. (2023). How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation. Microsoft.
Ricardo Rei (2022). COMET