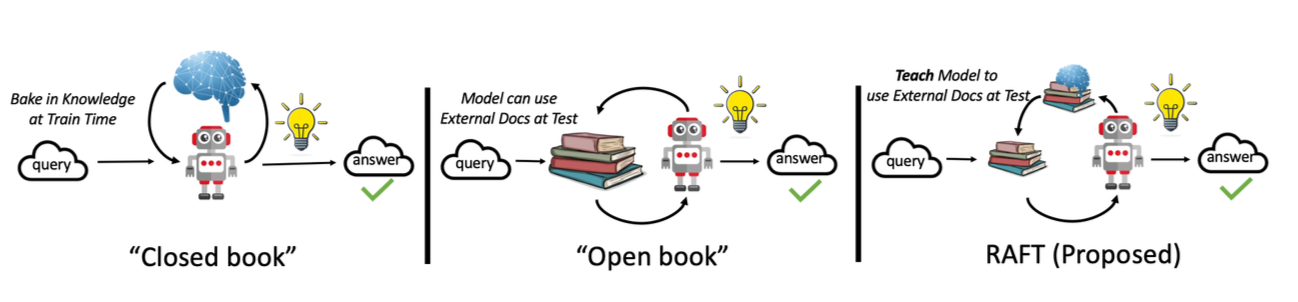
TF-IDF 검색을 활용하여 GPT-4 번역의 In-Context Learning 성능을 향상시키는 방법에 관한 연구 보고서입니다.
1. 서론
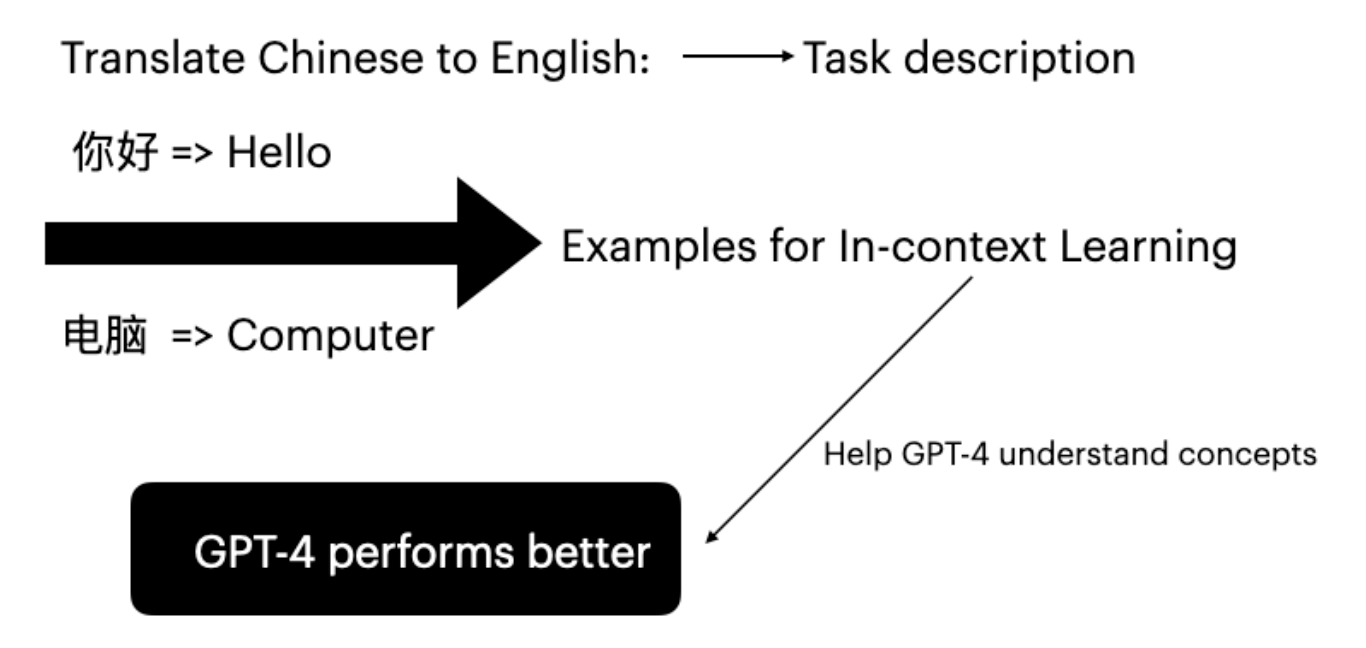
대규모 언어 모델(LLM)은 입력-레이블 쌍을 조건으로 제공하면 다운스트림 태스크에서 뛰어난 능력을 보여주고 있습니다. 이러한 추론 방식을 In-Context Learning이라고 합니다(Brown et al. 2020). GPT-4는 파인튜닝 없이도 특정 태스크 예시를 제공하는 것만으로 번역 능력을 향상시킬 수 있습니다.
In-Context Learning의 효과는 암시적 베이즈 추론에서 비롯됩니다(Xie et al. 2022). 예시를 무작위로 선택하면 GPT-4가 프롬프트의 개념을 효과적으로 이해하기 어렵습니다. 본 연구의 주요 목표는 사용자 입력에 기반하여 적합한 예시를 전략적으로 선택하는 것입니다.
2. 제안 방법
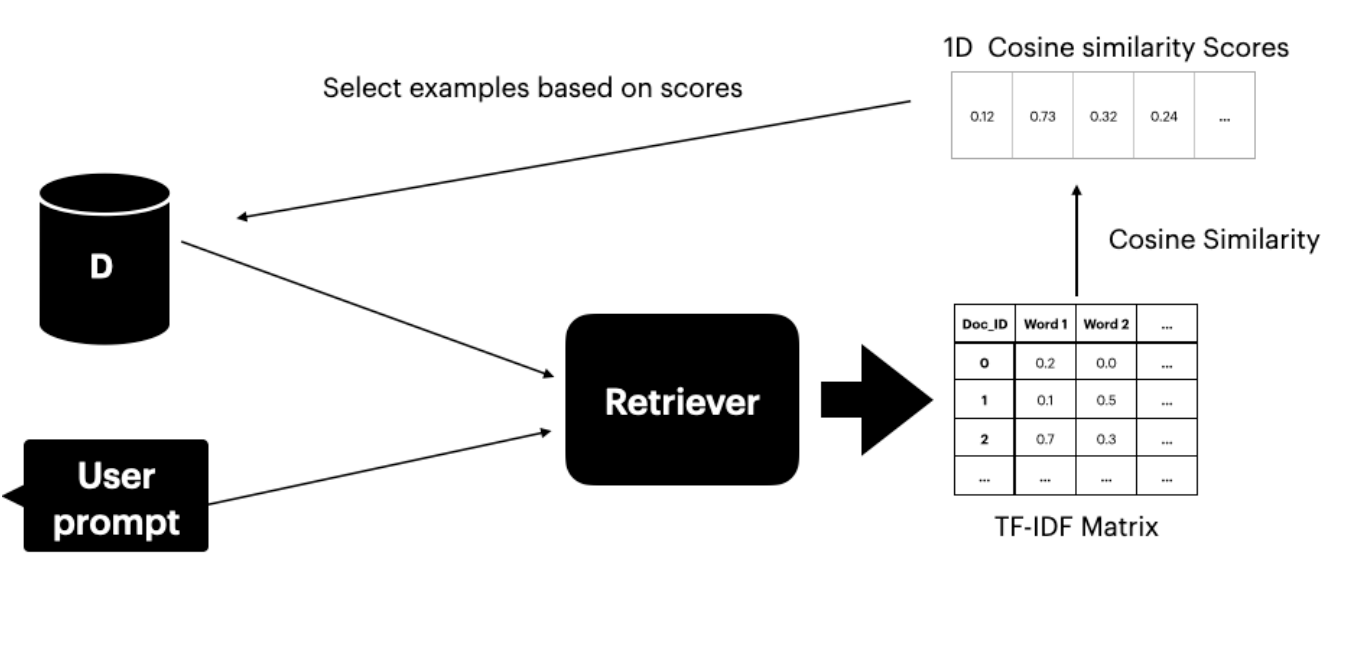
본 방법론은 번역 쌍이 포함된 데이터셋 Ds에 접근할 수 있음을 전제로 합니다. 텍스트 리트리버(Gao 2023)를 사용하여 사용자 프롬프트와 의미적으로 유사한 상위 K개의 문장을 검색하고 선택합니다.
리트리버는 두 가지 구성 요소로 이루어져 있습니다.
- TF-IDF 행렬 - 단어 빈도와 역문서 빈도를 측정
- 코사인 유사도 - TF-IDF 벡터 간 유사도를 계산
TF-IDF 점수
TF-IDF 점수는 문서 내 단어의 중요도를 측정합니다.
- TF (단어 빈도): 문서 내에서 단어가 나타나는 빈도
- IDF (역문서 빈도): 전체 코퍼스에서 단어의 중요성
코사인 유사도
코사인 유사도는 두 벡터 표현 사이의 각도를 고려하여 유사성을 평가합니다. 점수가 높을수록 사용자 프롬프트와 데이터셋 문서 간의 유사도가 높음을 나타냅니다.
3. 실험 설정
3.1 실험 절차
실험은 세 가지 시나리오를 다룹니다.
- ICL 없음: In-Context Learning 예시 없이 GPT-4로 번역
- 랜덤 ICL: 번역 예시를 무작위로 선택
- 제안 방법: TF-IDF 리트리버가 유사도 점수 기반으로 상위 4개 예시를 선택
평가 지표
- BLEU 점수: 번역 결과를 참조 번역과 비교 (Papineni et al. 2002)
- COMET 점수: 인간 판단과 최고 수준의 상관관계를 달성하는 다국어 기계번역 평가 프레임워크 (Rei et al. 2020)
3.2 데이터셋
OPUS-100 (Zhang et al. 2020)을 선택한 이유:
- 다양한 번역 언어 쌍을 포함 (ZH-EN, JA-EN, VI-EN)
- 효과적인 예시 선택을 위한 다양한 도메인을 포함
설정:
- Ds로 언어 쌍당 10,000개의 학습 인스턴스
- 평가용으로 테스트셋의 처음 100개 문장
3.3 구현
scikit-learn의 TfidfVectorizer와 cosine_similarity 함수를 사용합니다.
- 사용자 프롬프트와 Ds를 결합
- 프롬프트와 모든 문장 사이의 코사인 유사도 점수를 계산
- 유사도 기준으로 상위 4개 예시를 선택
- 예시를 GPT-4 프롬프트에 삽입

4. 결과 및 논의
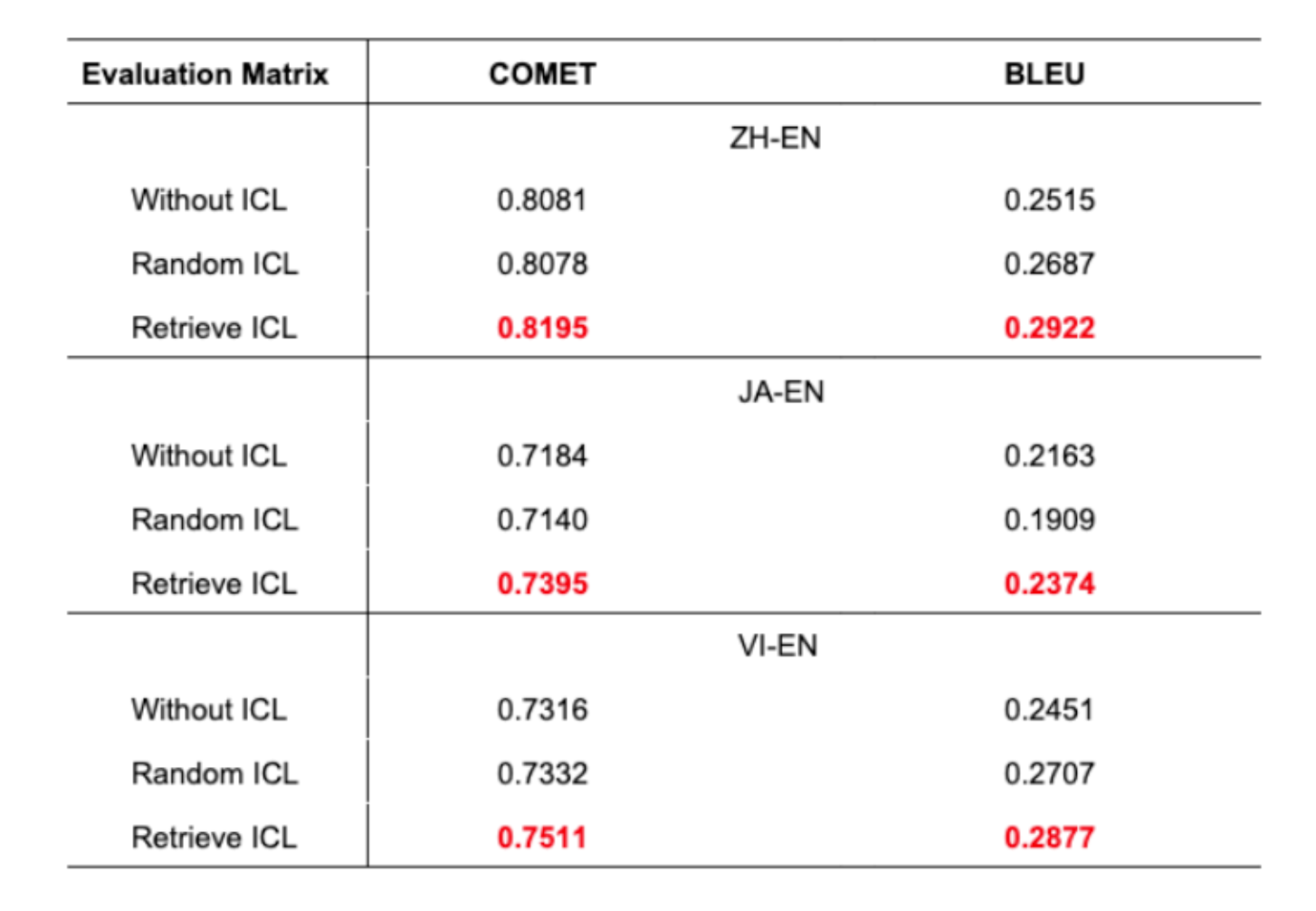
주요 발견:
- 제안 방법이 모든 언어 쌍에서 우수한 번역 정확도를 달성
- BLEU 점수의 1% 향상은 기계번역에서 유의미한 개선
- 랜덤 ICL은 때때로 ICL 없음보다 나쁜 결과를 보임
- 이는 적절한 예시 선택의 중요성을 입증
데이터셋 크기의 영향

100만 문장으로 테스트한 결과, Ds 데이터셋이 클수록 GPT-4의 태스크 학습 효과가 향상됨을 확인했습니다.
5. 결론 및 향후 과제
본 논문은 TF-IDF 검색 기반의 In-Context Learning을 통해 GPT-4의 번역 성능을 향상시키는 방법을 제안했습니다. 본 방법은 다음을 달성합니다.
- TF-IDF 행렬과 코사인 유사도를 이용한 리트리버 구축
- 사용자 프롬프트와 밀접하게 일치하는 문장 선택
- BLEU 및 COMET 점수 모두에서 개선
향후 연구 방향:
- 데이터셋 구축: 다양한 도메인에 걸친 포괄적이고 고품질인 번역 데이터셋 구축
- 예시 수: 4개 대신 5개 또는 10개의 예시를 사용했을 때의 영향 조사
6. 참고 문헌
- Brown, T., et al. (2020). “Language models are few-shot learners.”
- Xie, S. M., et al. (2022). “An Explanation of In-context Learning as Implicit Bayesian Inference.”
- Bashir, D. (2023). “In-Context Learning, in Context.” The Gradient.
- Das, R., et al. (2021). “Case-based reasoning for natural language queries over knowledge bases.”
- Liu, J., et al. (2022). “What makes good in-context examples for GPT-3?”
- Margatina, K., et al. (2023). “Active learning principles for in-context learning with large language models.”
- Gao, L., et al. (2023). “Ambiguity-Aware In-Context Learning with Large Language Models.”
- Papineni, K., et al. (2002). “BLEU: A method for automatic evaluation of machine translation.”
- Rei, R., et al. (2020). “COMET: A Neural Framework for MT Evaluation.”
- Zhang, B., et al. (2020). “Improving Massively Multilingual Neural Machine Translation and Zero-Shot Translation.”