요약
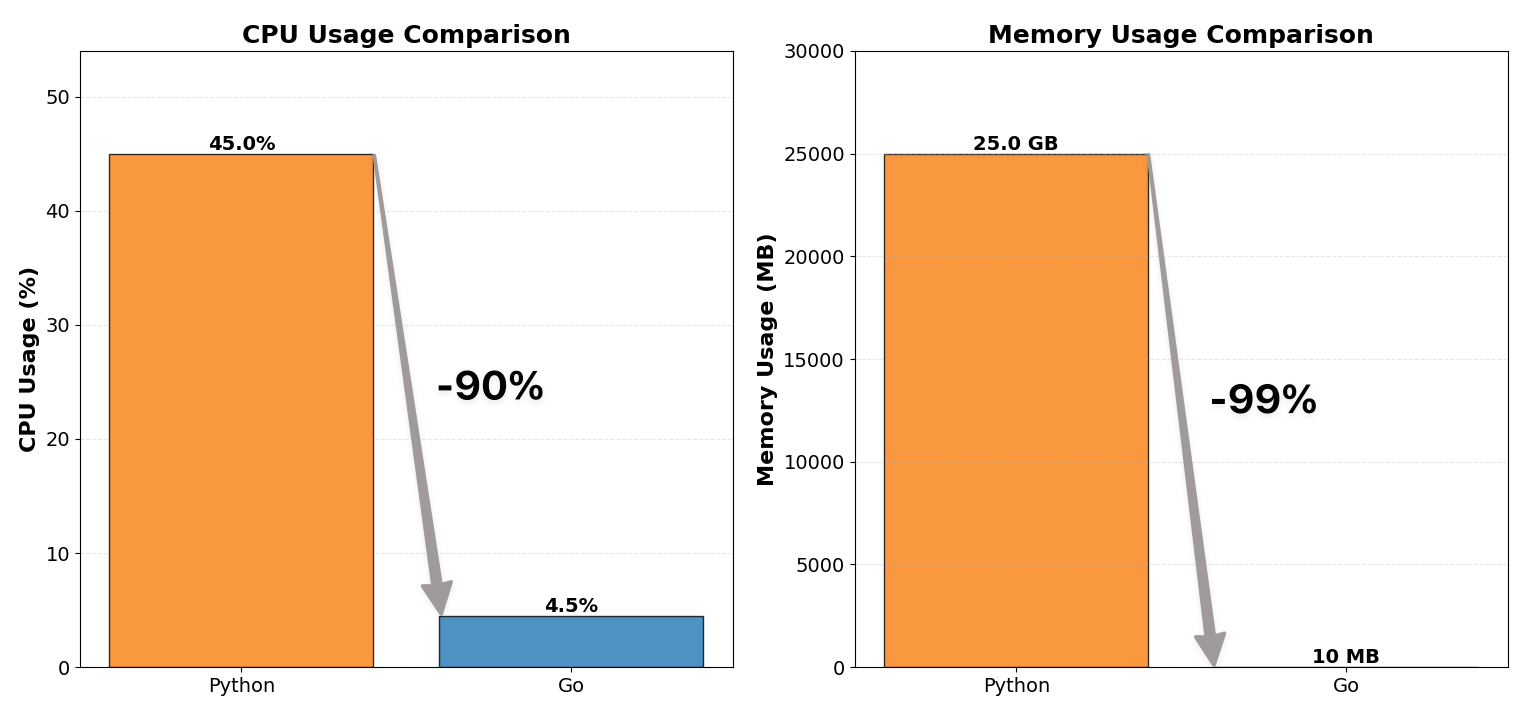
WebSocket 프록시 서버를 Python에서 Go로 재작성하여 CPU 사용량을 1/10, 메모리 소비를 1/100으로 줄였습니다.
이 프로젝트는 리소스 효율성 개선뿐만 아니라 동시성에 관한 중요한 교훈을 가져다 주었습니다.
락은 최대한 작게, 최대한 적게 유지하라.
배경
VoicePing의 시스템은 실시간 STT(음성 인식) 및 번역 파이프라인입니다. 각 클라이언트 기기는 백엔드에 오디오를 스트리밍하여 여러 언어로 음성 인식과 번역을 수행합니다.
WebSocket 프록시 서버는 이 파이프라인의 중간에 위치합니다.
- 각 클라이언트는 STT 프록시와 영구적인 WebSocket 세션을 유지
- 프록시는 오디오 패킷을 GPU 기반 추론 서버 중 하나로 중계
- 텍스트 변환 결과를 기다린 후 부분 트랜스크립트와 번역을 스트리밍으로 반환
이 아키텍처는 수천 개의 동시 실시간 오디오 세션을 서브초 단위의 지연 시간으로 처리해야 합니다.
그러나 기존의 Python 기반 프록시가 병목이 되었습니다.
개선 전: Python 프록시 (비효율적)
첫 번째 프록시 서버는 Python(FastAPI + asyncio + websockets)으로 구현되었으며, Gunicorn의 다중 워커 프로세스로 배포했습니다.
소규모에서는 잘 작동했지만, 프로덕션 트래픽에서는 금방 리소스 한계에 도달했습니다.
| 지표 | Before (Python) | After (Go) |
|---|
| CPU 사용량 | 약 12코어 × 40~50% | 약 12코어 × 4~5% |
| 메모리 사용량 | 약 25 GB | 약 10 MB |
Python이 어려움을 겪은 이유
비동기 방식임에도 불구하고, Python의 아키텍처에는 여러 구조적 병목이 있었습니다.
싱글 스레드 이벤트 루프:
asyncio 모델은 단일 스레드 위에서 수천 개의 코루틴을 다중화합니다. 한 번에 하나의 코루틴만 실행되며, 나머지는 루프가 제어를 넘길 때까지 대기합니다. I/O가 집중되는 환경에서 이 단일 루프가 중심적인 병목 지점이 되며, 특히 읽기/쓰기 이벤트가 끊임없는 WebSocket 워크로드에서 심각합니다.
Gunicorn 멀티프로세싱:
모든 CPU 코어를 활용하기 위해 다수의 워커 프로세스를 생성했습니다. 각 프로세스가 전체 Python 런타임과 앱 상태를 로드하므로 메모리 사용량이 선형적으로 증가합니다.
무거운 태스크 컨텍스트:
각 WebSocket 연결이 자체 스택 프레임, Future, 콜백을 유지하여 연결당 많은 메모리를 소비합니다.
인터프리터 오버헤드:
모든 코루틴이 CPython 인터프리터 내에서 실행되며, 동적 타입 검사와 바이트코드 디스패치 오버헤드가 추가됩니다.
결과적으로 시스템은 외견상 동시 처리를 수행하는 것처럼 보였지만, 본질적으로는 순차적이었습니다. 모든 코루틴이 같은 이벤트 루프에서 대기하면서 연결 수가 증가할수록 지연 시간과 CPU 부하가 증폭되었습니다.
불가피한 일이었습니다. Python의 모델은 이 규모의 장기 유지, 고처리량, 저지연 WebSocket 다중화에 적합하지 않았습니다.
그래서 Go로 재작성했습니다.
프록시 서버 전체 구조
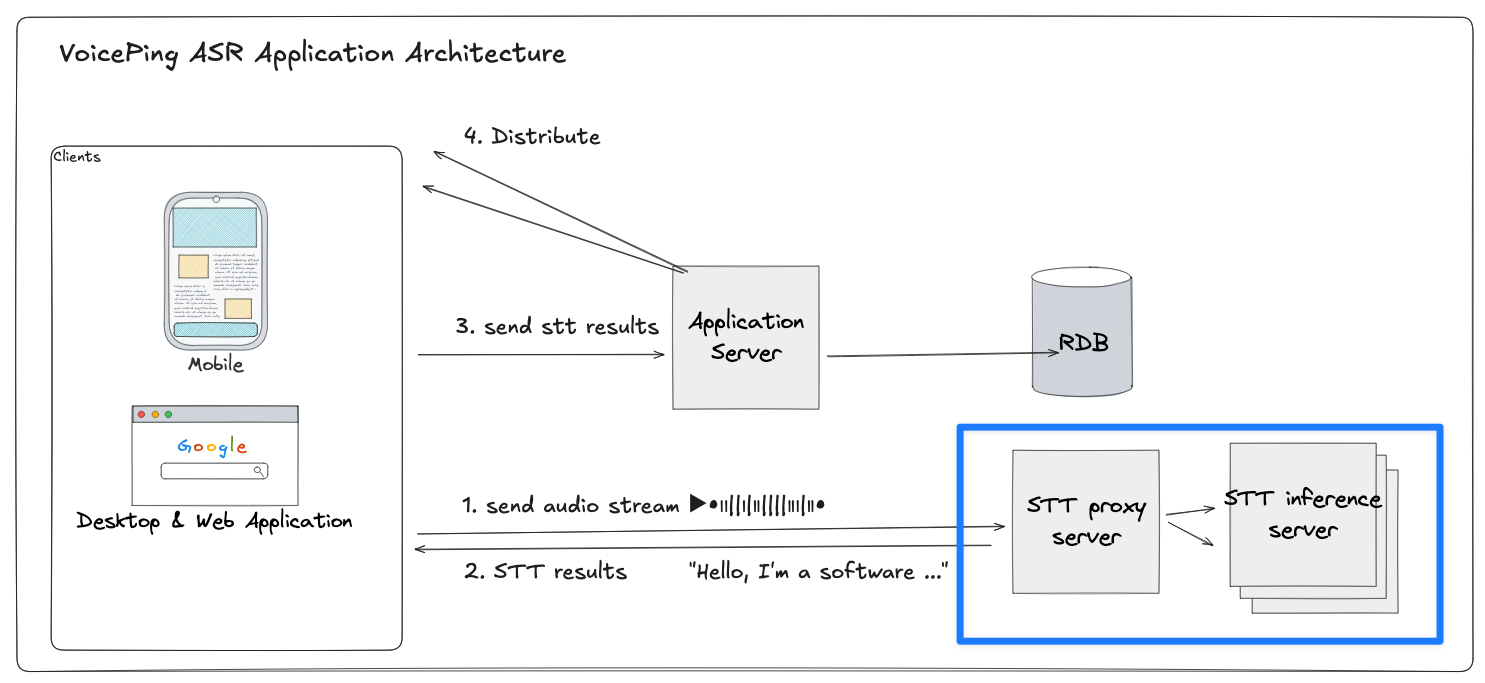
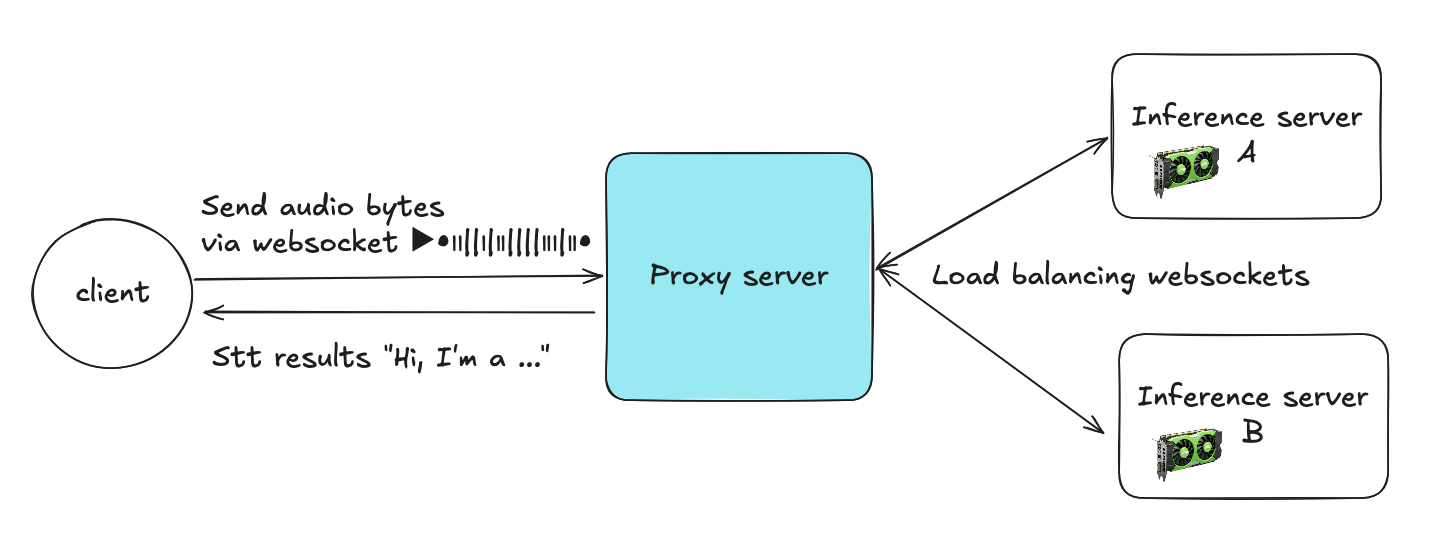
프록시 서버는 클라이언트와 여러 추론 서버 사이의 중간 계층 역할을 합니다. 클라이언트는 WebSocket을 통해 오디오 바이트를 전송하고, 프록시는 각 스트림을 여러 STT 추론 서버 중 하나로 라우팅합니다.
클라이언트 → 프록시:
각 클라이언트는 프록시에 WebSocket 연결을 열고 오디오 청크를 지속적으로 전송합니다.
프록시 → 추론 서버:
프록시는 WebSocket 커넥션 풀(서버 A에는 풀 A, 서버 B에는 풀 B 등, 사전 수립된 영구 백엔드 연결 풀)에서 활성 연결 하나를 선택합니다.
스트리밍 처리:
프록시는 전체 세션 동안 클라이언트와 선택된 백엔드 연결 간의 매핑을 유지하며, 오디오 패킷을 전달하고 STT 결과를 실시간으로 반환합니다.
연결 재사용:
세션 종료 시(클라이언트 연결 해제 시), 프록시는 백엔드 연결을 풀에 반환하여 다른 클라이언트가 사용할 수 있도록 합니다. 이 재사용 메커니즘으로 연결의 빈번한 생성/해제와 리소스 오버헤드가 크게 줄어듭니다.
프록시 서버는 두 가지 주요 부분을 관리합니다.
- 커넥션 매니저: 클라이언트 연결의 라우팅과 생명 주기 관리
- WebSocket 커넥션 풀: 각 추론 서버별 재사용 가능한 백엔드 연결 관리
각 풀은 하나의 추론 대상(예: A 또는 B)에 대응하며, 사전 수립된 WebSocket 연결을 일정 수 보유합니다.
이 아키텍처를 통해 프록시는 다음을 달성합니다.
- 추론 서버 간 효율적인 부하 분산
- 빈번한 연결 수립의 오버헤드 회피
커넥션 풀 관리의 기능 요구사항
커넥션 풀 관리 설계는 새로운 프록시 아키텍처에서 가장 중요한 부분이었습니다. 풀은 수천 개의 동시 WebSocket 세션을 효율적으로 처리하면서 시스템의 안정성과 경량성을 유지해야 했습니다.
| 요구사항 | 목적 |
|---|
| 사용 가능한 연결 획득 | 수신 요청이 다른 클라이언트를 블로킹하지 않고 즉시 사용 가능한 백엔드 연결을 확보해야 합니다. 저지연과 원활한 부하 분산을 보장합니다. |
| 연결을 풀로 반환 | 클라이언트 세션 종료 후 연결을 해제하여 재사용 가능하게 합니다. 연결의 반복적인 열기/닫기 오버헤드를 최소화합니다. |
| 건강한 연결만 유지 | 주기적 헬스 체크로 장애 연결을 제거하거나 재생성합니다. 비정상 연결의 누적으로 인한 사일런트 장애를 방지합니다. |
| 데이터베이스 설정 동기화 | 중앙 데이터베이스에서 백엔드 연결 설정을 주기적으로 동기화하여 재시작 없이 동적 스케일링을 지원합니다. |
초기 설계 (나이브)
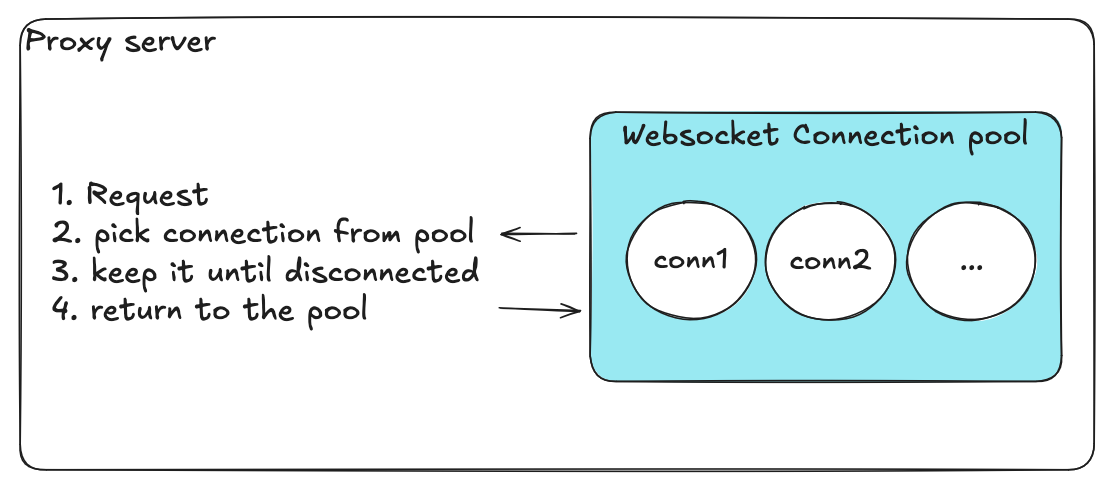
처음에는 단순하지만 나이브한 설계를 구현했습니다.
- 모든 연결을 담는 단일 배열
- “사용 중” / “사용 가능” 상태를 나타내는 부울 플래그
- 모든 작업에 대한 하나의 글로벌 락
연결 획득 절차:
- 락 획득
- 배열을 스캔하여 사용 가능한 연결 탐색
- “사용 중"으로 표시
- 락 해제
연결 반환도 마찬가지로, 락을 획득하고 플래그를 전환한 후 락을 해제합니다.
데이터베이스 설정을 주기적으로 확인하는 별도의 goroutine도 있었습니다. 이 goroutine은 데이터베이스에서 서버 목록이나 풀 크기 등의 백엔드 설정을 갱신하여, 재시작 없이 항상 최신 설정을 유지할 수 있게 했습니다.
별도의 헬스 체크 goroutine이 주기적으로 모든 연결을 스캔하여, 비정상 연결을 제거하고 필요 시 새 연결을 추가했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
| // ────────────────────────────
// FIRST DESIGN (naive, global mutex)
// Single slice + flags, one coarse-grained mutex.
// ────────────────────────────
type Conn struct {
id string
ws *websocket.Conn
inUse bool
healthy bool
}
type Pool struct {
mu sync.Mutex
conns []*Conn
maxSize int
dialURL string
}
// newConn dials a backend and returns a connected *Conn.
// NOTE: In this first design we (incorrectly) call this under the global lock.
func (p *Pool) newConn(ctx context.Context) (*Conn, error) {
d := websocket.Dialer{}
c, _, err := d.DialContext(ctx, p.dialURL, nil)
if err != nil {
return nil, err
}
return &Conn{
id: uuid.NewString(),
ws: c,
inUse: false,
healthy: true,
}, nil
}
// ────────────────────────────
// AdjustPool
// Check capacity vs current size; if not full, fill it.
// BAD PATTERN: holds the global mutex across slow I/O (dial).
// ────────────────────────────
func (p *Pool) AdjustPool(ctx context.Context) error {
p.mu.Lock()
defer p.mu.Unlock()
cur := len(p.conns)
if cur >= p.maxSize {
return nil
}
needed := p.maxSize - cur
for i := 0; i < needed; i++ {
conn, err := p.newConn(ctx)
if err != nil {
return fmt.Errorf("adjust: dial failed: %w", err)
}
p.conns = append(p.conns, conn)
}
return nil
}
// ────────────────────────────
// GetPoolStats
// Return total / in-use / available counts.
// BAD PATTERN: O(n) scan under global lock every call.
// ────────────────────────────
type PoolStats struct {
Total int
InUse int
Available int
Healthy int
Unhealthy int
}
func (p *Pool) GetPoolStats() PoolStats {
p.mu.Lock()
defer p.mu.Unlock()
var inUse, healthy int
for _, c := range p.conns {
if c.inUse {
inUse++
}
if c.healthy {
healthy++
}
}
total := len(p.conns)
return PoolStats{
Total: total,
InUse: inUse,
Available: total - inUse,
Healthy: healthy,
Unhealthy: total - healthy,
}
}
// ────────────────────────────
// HealthCheck
// Ping all connections and mark healthy=false on failures.
// BAD PATTERN: holds global lock during network I/O & mutates in place.
// ────────────────────────────
func (p *Pool) HealthCheck(ctx context.Context, timeout time.Duration) {
p.mu.Lock()
defer p.mu.Unlock()
deadline := time.Now().Add(timeout)
for _, c := range p.conns {
if c.ws == nil {
c.healthy = false
continue
}
if err := c.ws.WriteControl(websocket.PingMessage, []byte("ping"), deadline); err != nil {
c.healthy = false
_ = c.ws.Close()
c.ws = nil
continue
}
c.healthy = true
}
}
|
초기 설계의 문제점
소규모 테스트에서는 동작했지만, 부하가 걸리자 초기 풀링 모델은 무너졌습니다. 다음과 같은 문제를 관찰했습니다.
총 개수의 부정확성 (오버슈트/언더슈트):
동시적인 pick/return 연산이 하나의 조잡한 락 아래서 같은 슬라이스와 플래그를 수정하므로, 재시도와 타임아웃으로 연결이 이중 반환되거나 유실되어 최대값을 초과하거나 풀이 고갈되었습니다.
레이스 컨디션으로 인한 동시 접근 → 크래시 및 상태 손상:
헬스 체크와 메트릭스 goroutine이 요청 핸들러와 경합했고, 긴 헬스 체크가 글로벌 락을 점유하는 동안 리더가 반쯤 업데이트된 플래그를 읽어 패닉이나, 용량이 있음에도 “사용 가능한 연결 없음” 오류가 발생했습니다.
goroutine 누수:
실패한 다이얼과 타임아웃된 헬스 체크가 항상 취소되거나 회수되지 않았고, 재시도가 새 goroutine을 생성하면서 이전 goroutine에 대한 참조가 남았습니다.
취약한 관측 가능성:
슬라이스와 플래그에서 도출된 카운터가 실제 상태와 자주 불일치하여, 알림이 노이즈가 많아지고 실제 인시던트가 가려졌습니다.
락 경합 및 지연 시간 스파이크:
단일 락 하의 O(n) 스캔으로 동시성이 증가할수록 테일 레이턴시가 증폭되었습니다.
주의: 근본 원인을 한 마디로 말하면, 하나의 넓고 오래 유지되는 락으로 보호되는 과도한 공유 상태에, 독립적이어야 할 작업(헬스 체크/메트릭스)이 같은 락을 놓고 경쟁한 것입니다.
개선된 설계
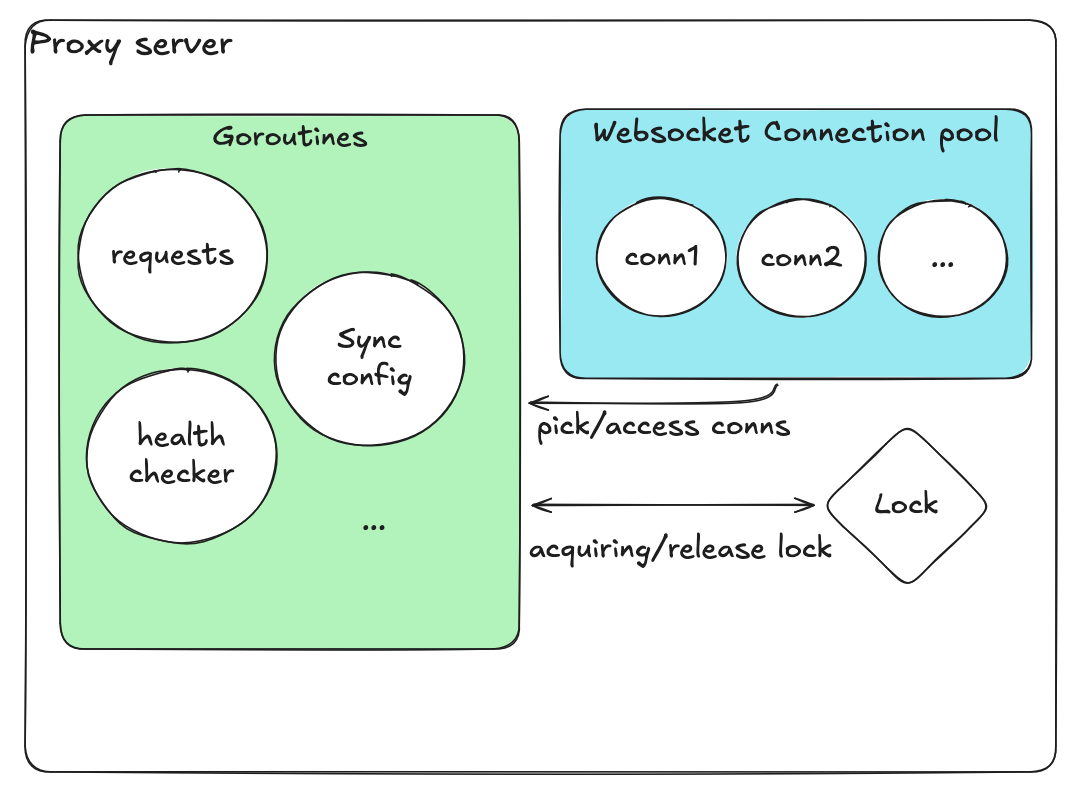
재설계는 공유 상태 최소화와 책임 분리에 초점을 맞추었습니다.
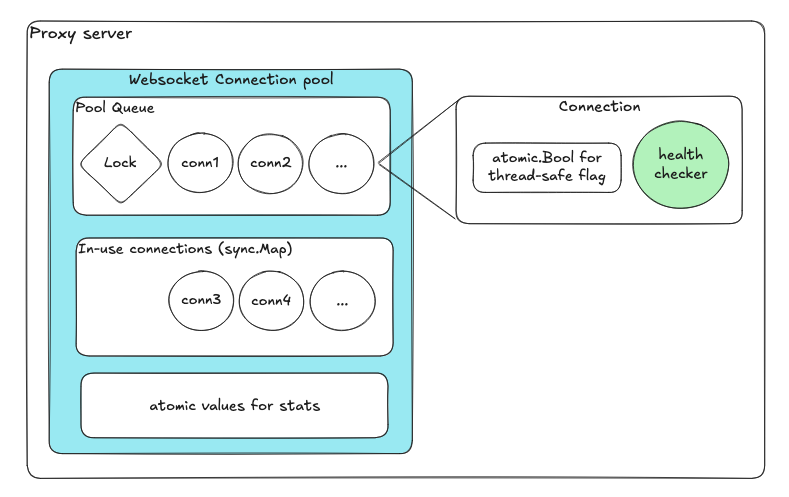
| 컴포넌트 | 목적 |
|---|
| 사용 가능 연결용 큐 | enqueue/dequeue가 내부 락을 자동으로 처리 |
| 사용 중 연결용 sync.Map | 락 프리 동시성 맵 |
| 원자적 변수 | 헬스 플래그와 카운터 |
| 연결별 전용 goroutine | 독립적인 헬스 체크 |
각 컴포넌트가 독립적으로 동작하며, 풀 전체의 락이 없습니다. 락의 수와 범위가 극적으로 줄었습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
| package pool
import (
"context"
"errors"
"net/http"
"sync"
"sync/atomic"
"time"
"github.com/google/uuid"
"github.com/gorilla/websocket"
)
// ────────────────────────────
// Conn (a single reusable backend WebSocket connection)
// ────────────────────────────
//
// ✅ GOOD PATTERN:
// - Keep each connection self-contained and concurrent-safe using atomics.
// - Encapsulate health logic inside the Conn itself (no shared state mutation).
// - Avoid external locks and let each conn manage its own goroutine lifecycle.
type Conn struct {
id string
ws *websocket.Conn
healthy atomic.Bool // ✅ lock-free health status flag
lastPing atomic.Int64 // ✅ atomic timestamp for last heartbeat
}
// ✅ GOOD PATTERN: Explicit small helper methods (no external mutation)
func (c *Conn) ID() string { return c.id }
func (c *Conn) IsAlive() bool {
return c.healthy.Load()
}
// ✅ GOOD PATTERN: Safe close, idempotent and isolated
func (c *Conn) Close() error {
if c.ws != nil {
return c.ws.Close()
}
return nil
}
// ✅ GOOD PATTERN: Health loop runs independently per connection
// - No shared/global lock.
// - Non-blocking heartbeat.
// - Fails fast and marks itself dead without blocking pool operations.
func (c *Conn) StartHealthLoop(ctx context.Context, interval time.Duration) {
t := time.NewTicker(interval)
defer t.Stop()
for {
select {
case <-ctx.Done():
return
case <-t.C:
deadline := time.Now().Add(interval / 2)
if err := c.ws.WriteControl(websocket.PingMessage, []byte("ping"), deadline); err != nil {
c.healthy.Store(false)
_ = c.Close()
return
}
c.lastPing.Store(time.Now().UnixNano())
c.healthy.Store(true)
}
}
}
// ────────────────────────────
// ConnPool (fast path only — no dialing, no blocking I/O)
// ────────────────────────────
//
// ✅ GOOD PATTERN:
// - Separate responsibilities: pool only manages available connections.
// - No dialing / blocking I/O under locks.
// - Use channel buffering and atomic counters for concurrency safety.
// - Eliminates coarse-grained global mutex.
type ConnPool struct {
available chan *Conn // ✅ buffered channel for ready conns (lock-free)
inUse sync.Map // ✅ concurrent map for tracking active conns
statsIn atomic.Int64 // ✅ atomic counters (no need for locks)
statsOut atomic.Int64
}
// ✅ GOOD PATTERN: Explicit, fixed-capacity pool construction
func NewConnPool(capacity int) *ConnPool {
return &ConnPool{
available: make(chan *Conn, capacity),
}
}
func (p *ConnPool) Capacity() int { return cap(p.available) }
// ✅ GOOD PATTERN: Non-blocking Acquire
// - Never holds locks while waiting for I/O.
// - Returns instantly if no conn available.
func (p *ConnPool) Acquire(ctx context.Context) (*Conn, error) {
select {
case c := <-p.available:
p.inUse.Store(c.id, c)
p.statsIn.Add(1)
return c, nil
case <-ctx.Done():
return nil, ctx.Err()
default:
return nil, errors.New("no connection available")
}
}
// ✅ GOOD PATTERN: Non-blocking Release
// - Never waits for space in the channel.
// - Drops unhealthy or excess conns immediately.
// - No global mutex.
func (p *ConnPool) Release(c *Conn) {
p.inUse.Delete(c.id)
p.statsOut.Add(1)
if c.IsAlive() {
select {
case p.available <- c:
// ✅ returned to pool safely
default:
// ✅ pool full → discard stale conn safely
_ = c.Close()
}
} else {
// ✅ unhealthy → close immediately
_ = c.Close()
}
}
// ✅ GOOD PATTERN: Offer is used by reconciler (external goroutine)
// - Keeps dialing/repair logic out of hot path.
// - Backpressure-safe with non-blocking insert.
func (p *ConnPool) Offer(c *Conn) bool {
select {
case p.available <- c:
return true
default:
return false
}
}
// ────────────────────────────
// Stats and Metrics
// ────────────────────────────
//
// ✅ GOOD PATTERN:
// - Lock-free snapshot using atomics.
// - Avoids holding locks during metrics collection.
type PoolStats struct {
Capacity int
Available int
InUse int
Acquired int64
Released int64
}
// ✅ GOOD PATTERN: Snapshot safely aggregates pool state without blocking
func (p *ConnPool) Snapshot() PoolStats {
inUseCount := 0
p.inUse.Range(func(_, _ any) bool {
inUseCount++
return true
})
return PoolStats{
Capacity: cap(p.available),
Available: len(p.available),
InUse: inUseCount,
Acquired: p.statsIn.Load(),
Released: p.statsOut.Load(),
}
}
|
핵심: 각 컴포넌트가 풀 전체의 락 없이 독립적으로 동작합니다. 락의 수와 범위가 극적으로 줄었습니다.
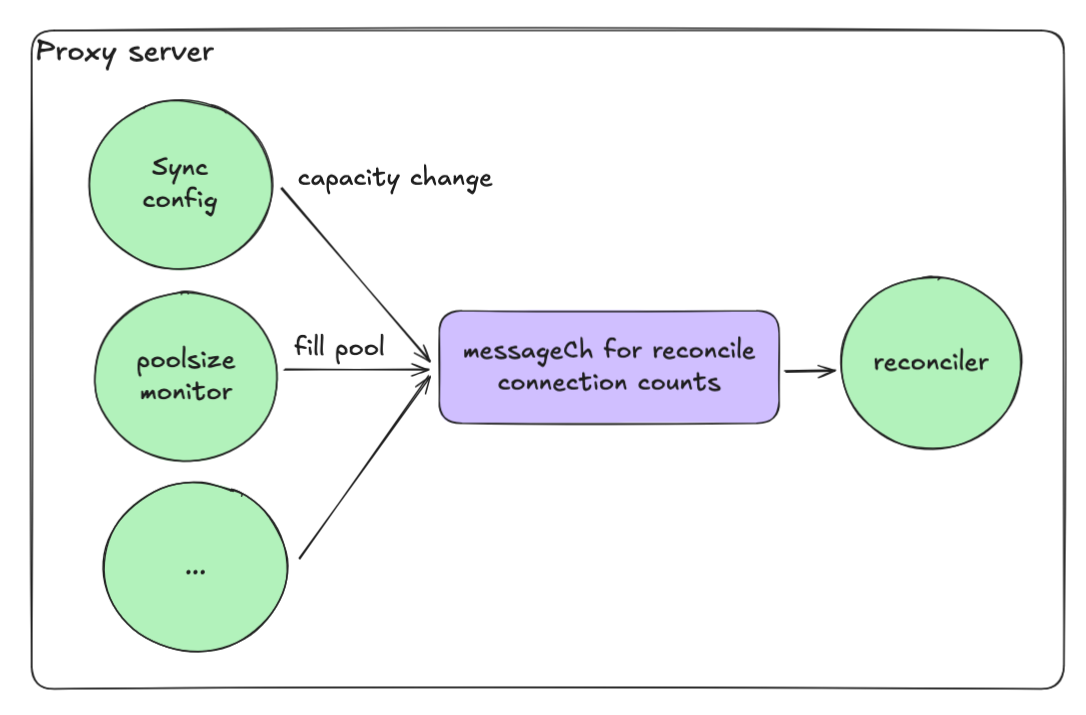
이벤트 기반 리컨실리에이션
적절한 풀 크기를 유지하는 것도 과제였습니다. 연결 실패나 반환 시 리컨실리에이션이 동시에 실행되면 최대 풀 크기를 쉽게 초과할 수 있습니다.
해결책은 이벤트 기반 리컨실리에이션 루프였습니다.
- 각 작업이 채널(messageCh)에 메시지를 전송
- 리컨실리에이션 goroutine이 메시지를 순차적으로 처리
- 이를 통해 레이스 컨디션을 제거
이 모델로 높은 동시성을 유지하면서 시스템을 결정적이고 안전하게 만들 수 있었습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
| type ServerConnectionPool struct {
ctx context.Context
cancel context.CancelFunc
reconcileCh chan struct{}
logger *zap.Logger
// ... other fields ...
}
// ✅ GOOD PATTERN: Constructor wires a buffered (size=1) signal channel to enable coalescing.
func NewServerConnectionPool(logger *zap.Logger /* ... */) *ServerConnectionPool {
ctx, cancel := context.WithCancel(context.Background())
return &ServerConnectionPool{
ctx: ctx,
cancel: cancel,
reconcileCh: make(chan struct{}, 1), // ✅ coalescing buffer
logger: logger,
// ... init other fields ...
}
}
// ✅ GOOD PATTERN: Non-blocking signal helper; bursts coalesce into a single pending signal.
func (bp *ServerConnectionPool) trySend(ch chan struct{}) {
select {
case ch <- struct{}{}:
default:
// already queued; coalesced
}
}
// triggerReconcile only *requests* reconciliation; never performs it inline.
// ✅ GOOD PATTERN: no work on the caller's goroutine, prevents stampedes.
func (bp *ServerConnectionPool) triggerReconcile() {
bp.trySend(bp.reconcileCh)
}
// ✅ GOOD PATTERN: Public starter that owns the worker lifecycle.
func (bp *ServerConnectionPool) Start() {
go bp.reconcileWorker()
}
// ✅ GOOD PATTERN: Graceful shutdown.
func (bp *ServerConnectionPool) Stop() {
bp.cancel()
}
// reconcileWorker serializes reconciliation and coalesces bursts.
// ✅ GOOD PATTERN:
// - Single-threaded worker → no concurrent ensureCapacity() runs
// - Periodic safety net with light jitter to avoid thundering herds
// - Drain queue before each run to collapse multiple signals into one
func (bp *ServerConnectionPool) reconcileWorker() {
jitter := func(base time.Duration) time.Duration {
// small ±10% jitter
n := time.Duration(float64(base) * (0.9 + 0.2*rand.Float64()))
return n
}
ticker := time.NewTicker(jitter(5 * time.Second))
defer ticker.Stop()
bp.logger.Debug("Reconciliation worker started", zap.String("pool", bp.GetName()))
defer bp.logger.Debug("Reconciliation worker stopped", zap.String("pool", bp.GetName()))
// Optional: run once immediately on startup
bp.ensureCapacity()
for {
select {
case <-bp.ctx.Done():
return
case <-ticker.C:
// ✅ Periodic reconciliation as a safety net
bp.ensureCapacity()
// reset ticker with jitter to spread load
ticker.Reset(jitter(5 * time.Second))
case <-bp.reconcileCh:
// ✅ Drain any queued signals: burst -> single reconciliation
for {
select {
case <-bp.reconcileCh:
// keep draining
default:
bp.ensureCapacity()
goto CONTINUE
}
}
}
CONTINUE:
}
}
// ensureCapacity is the single authoritative place that:
// 1) Cleans unhealthy queued conns
// 2) Computes current vs target
// 3) Grows or shrinks the pool
// 4) Emits metrics/logs
func (bp *ServerConnectionPool) ensureCapacity() {}
// ────────────────────────────
// Event sources that *request* reconciliation
// ────────────────────────────
// Health watcher: when a server flips health, request reconcile.
// ✅ GOOD PATTERN: do not call ensureCapacity() here; just signal.
func (bp *ServerConnectionPool) startHealthWatcher(healthCh <-chan HealthEvent) {
go func() {
for {
select {
case <-bp.ctx.Done():
return
case ev := <-healthCh:
if ev.Changed {
bp.logger.Debug("health change → reconcile",
zap.String("server", ev.ServerID))
bp.triggerReconcile()
}
}
}
}()
}
// Config watcher: when scale target changes, request reconcile.
// ✅ GOOD PATTERN: apply config change, then signal worker.
func (bp *ServerConnectionPool) startConfigWatcher(cfgCh <-chan ScaleTarget) {
go func() {
for {
select {
case <-bp.ctx.Done():
return
case target := <-cfgCh:
// update internal target state...
bp.logger.Debug("scale target changed → reconcile",
zap.Int("target", target.Connections))
bp.triggerReconcile()
}
}
}()
}
|
핵심 패턴:
- 싱글 스레드 워커가 리컨실리에이션을 직렬화
- 버퍼드 채널이 버스트를 단일 작업으로 통합
- 지터가 적용된 주기적 세이프티넷이 썬더링 허드를 방지
로컬 성능 테스트
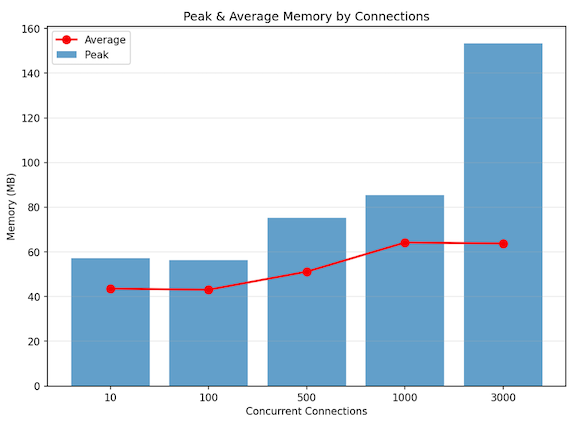
다음과 같은 구성으로 로컬 환경에서 성능을 검증했습니다.
테스트 구성
| 컴포넌트 | 설정 |
|---|
| 프록시 | Go 기반 WebSocket 프록시 |
| 백엔드 | Echo WebSocket 서버 3대 |
| 부하 | 동시 3,000 연결 (램프업 없음) |
| 트래픽 | 1 KB 텍스트 메시지 @ 연결당 100 메시지/초 |
결과
| 지표 | 값 |
|---|
| 동시 세션 | 약 3,000 (안정) |
| 처리량 | 약 30만 메시지/초 |
| 피크 메모리 | 약 150 MB |
| 평균 메모리 | 약 60 MB |
| CPU 사용량 | 12코어의 약 4~5% |
프록시가 완전한 동시 연결 버스트 환경에서도 평평한 메모리 풋프린트를 유지하는 것이 확인되어, 커넥션 풀 분리와 이벤트 기반 리컨실리에이션 모델의 효과가 입증되었습니다.
결론
새로운 Go 기반 프록시를 배포한 후, 성능, 확장성, 안정성 전반에서 크게 개선되었습니다.
| 카테고리 | Python (FastAPI + asyncio + Gunicorn) | Go (Goroutines + Channels + Atomics) | 개선 |
|---|
| CPU 사용량 | 약 12코어 × 40~50% | 약 12코어 × 4~5% | 약 90% 감소 |
| 메모리 사용량 | 약 25 GB | 약 60~150 MB | 약 99% 감소 |
| 확장성 | 수백 연결이 한계 | 수천 연결 유지 | 10배 스케일 |
Go 재작성은 단순한 언어 변경이 아니라 동시성 모델의 근본적인 전환이었습니다.
참고: 핵심 교훈: 동시성은 보호된 공유 가변 상태가 아니라, 독립적으로 통신하는 프로세스로 설계해야 합니다.
이러한 아키텍처 전환을 통해 프록시는 수백에서 수천의 동시 WebSocket 세션으로 거의 일정한 리소스 사용량으로 확장할 수 있게 되었으며, 코드와 운영의 명확성도 유지되었습니다.
참고 문헌
- Go Concurrency Patterns - golang.org/doc/effective_go
- gorilla/websocket - github.com/gorilla/websocket
- Python asyncio Event Loop - docs.python.org