얼굴 분석, 자세 추정, 감정 감지를 위한 영상 전처리 파이프라인 구축에 관한 연구 보고서입니다.
개요
본 프로젝트는 영상 및 음성 데이터의 전처리를 자동화하여 영상 생성 모델 학습에 필요한 핵심 정보를 추출하는 파이프라인을 구축했습니다. 이 파이프라인은 얼굴 감지, 감정 분류, 자세 추정, 음성 처리를 일괄적으로 처리합니다.
주요 기능:
- 고유한 얼굴의 자동 감지 및 분리
- 머리 자세 추정 (yaw, pitch, roll)
- 딥러닝 기반 감정 분류
- 음성 분류 및 음성 분리
- 클립 생성 (3~10초 세그먼트)
1. 서론
영상 기반 생성 모델의 부상으로 적절히 전처리된 영상 데이터셋에 대한 수요가 높아지고 있습니다. 본 프로젝트는 다음 작업을 자동화합니다.
- 고유한 얼굴의 자동 분류 및 인식
- 시간 축에 따른 얼굴 감정 및 머리 자세 감지
- 배경 음악의 음성 분류 및 음성 분리
- 생성 모델 활용을 위한 영상 트리밍 및 정제
2. 방법론
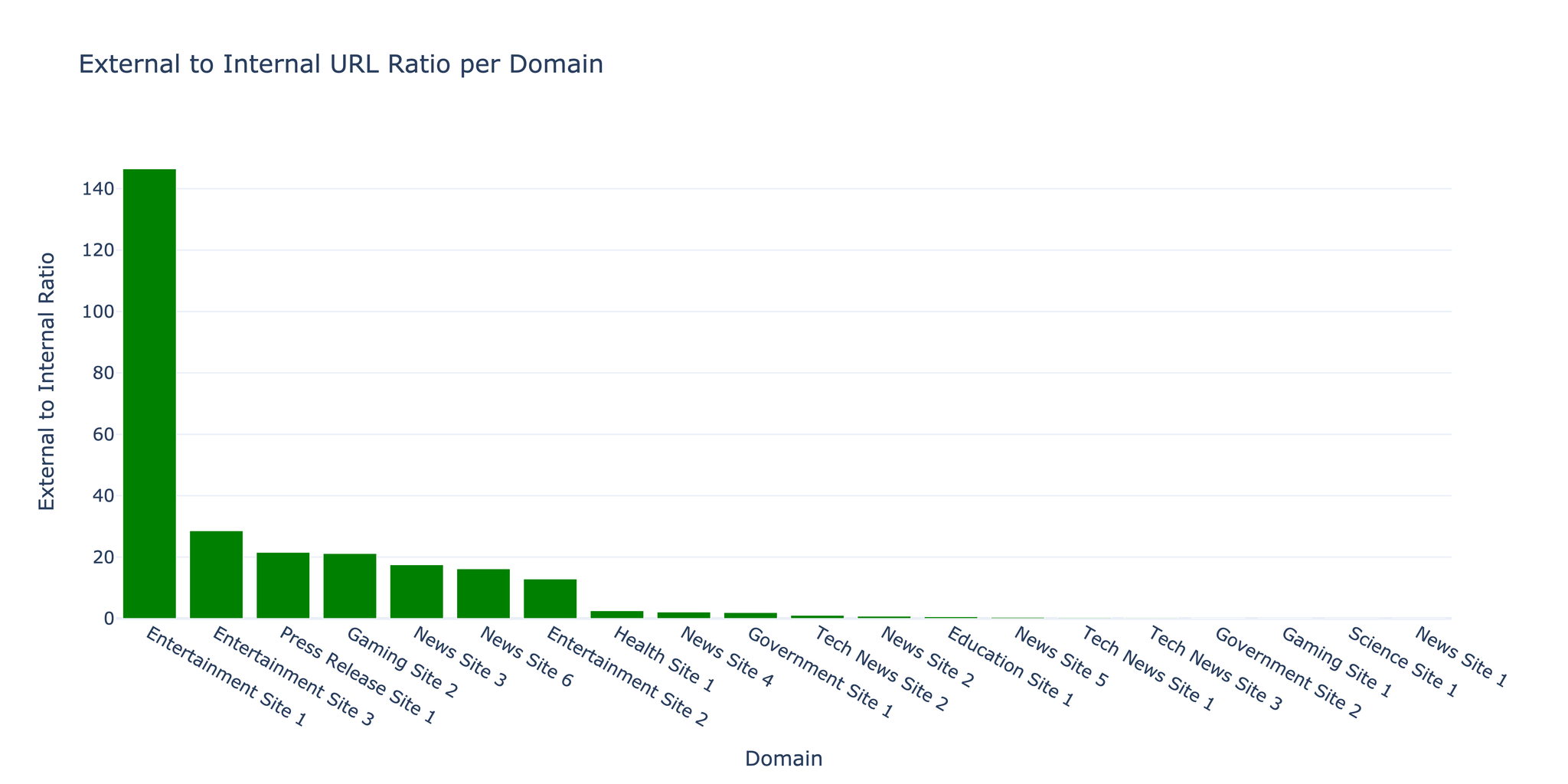
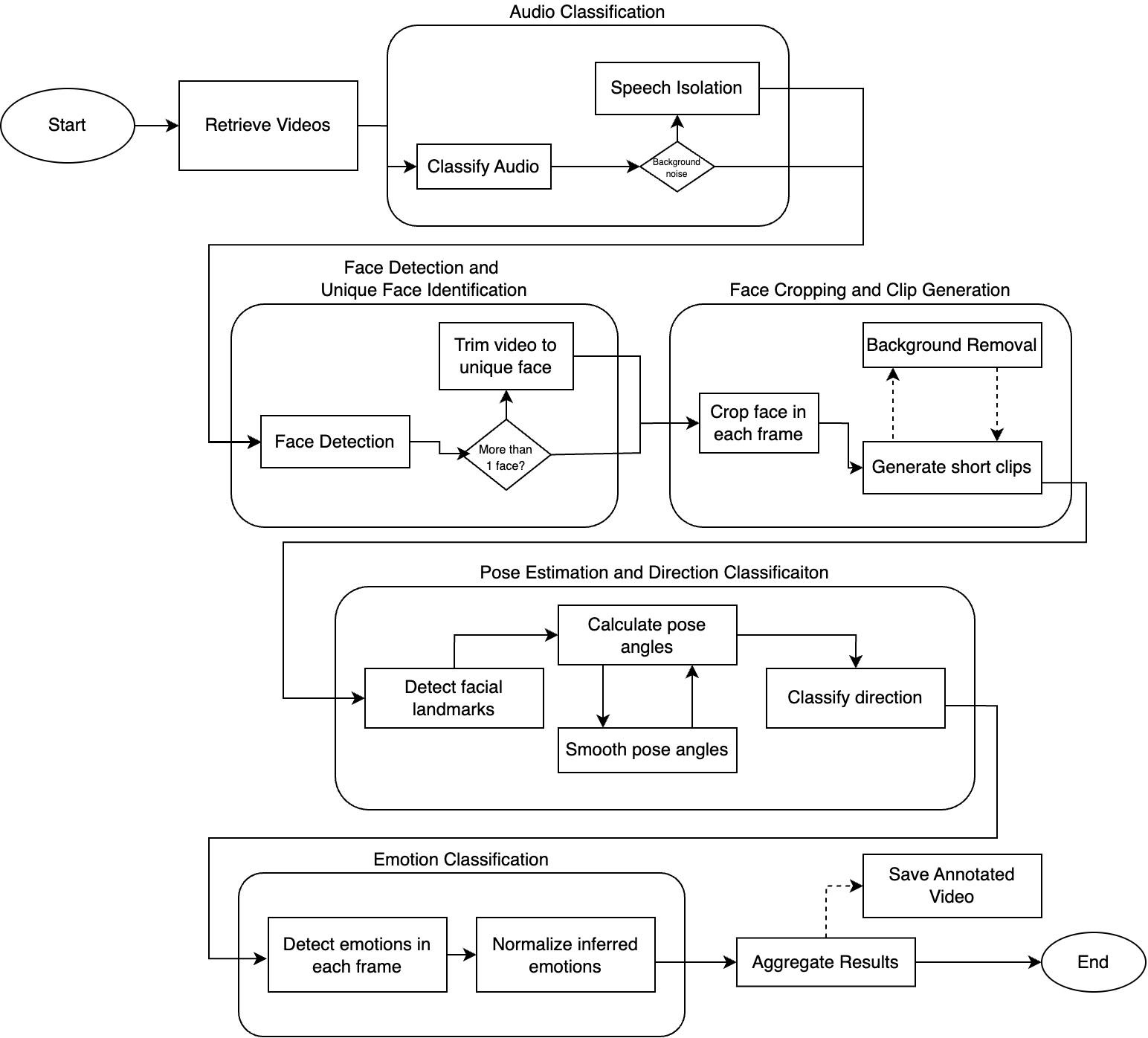
파이프라인 개요
전처리 파이프라인은 5개의 주요 단계로 구성됩니다.
| 단계 | 기능 |
|---|---|
| 음성 분류 | 음성 식별 및 배경 노이즈에서 분리 |
| 얼굴 감지 | 영상 내 고유한 얼굴 감지 및 식별 |
| 얼굴 크로핑 | 얼굴 중심 클립 생성 (3~10초) |
| 자세 추정 | 머리 방향 추정 (yaw, pitch, roll) |
| 감정 분류 | 각 프레임에서 감정 감지 |
2.1 영상 처리
yt-dlp를 사용하여 영상을 다운로드하고 프레임 단위로 처리합니다.
| |
2.2 음성 분류
Audio Spectrogram Transformer 모델을 사용하여 음성을 분류합니다.
- 음성을 스펙트로그램으로 변환
- Vision Transformer로 분류 수행
- 배경 노이즈 감지 임계값 약 20%
결과 예시:
| 영상 유형 | 음성 % | 음악 % |
|---|---|---|
| 음악이 포함된 해설 | 50.28% | 37.20% |
| 라이브 공연 | 1.50% | 46.54% |
| 뉴스 인터뷰 | 82.64% | 0% |
2.3 얼굴 감지 및 크로핑
YuNet 얼굴 감지 모델을 사용합니다.
- 각 프레임에서 모든 얼굴 감지
- 가장 큰 얼굴을 대상으로 선택
- 일정한 크기로 크롭 및 리사이즈
- 3~10초 클립 생성
참고: rembg를 이용한 선택적 배경 제거를 통해 대상을 더욱 분리할 수 있습니다.
2.4 자세 추정
68개의 얼굴 랜드마크를 사용하여 머리 자세를 추정합니다.
- Yaw: 좌우 회전 (10도 이상이면 오른쪽/왼쪽 방향)
- Pitch: 상하 회전 (10도 이상이면 위/아래 방향)
- Roll: 머리 기울기
자세 값은 연속 프레임의 버퍼를 사용하여 평활화됩니다.
2.5 감정 분류
Hugging Face의 facial_emotions_image_detection을 사용합니다.
- 감지 가능한 감정: 기쁨, 슬픔, 분노, 중립, 공포, 혐오, 놀람
- 점수는 합계 100%로 정규화
- 전체 영상의 요약으로 평균화
3. 결과
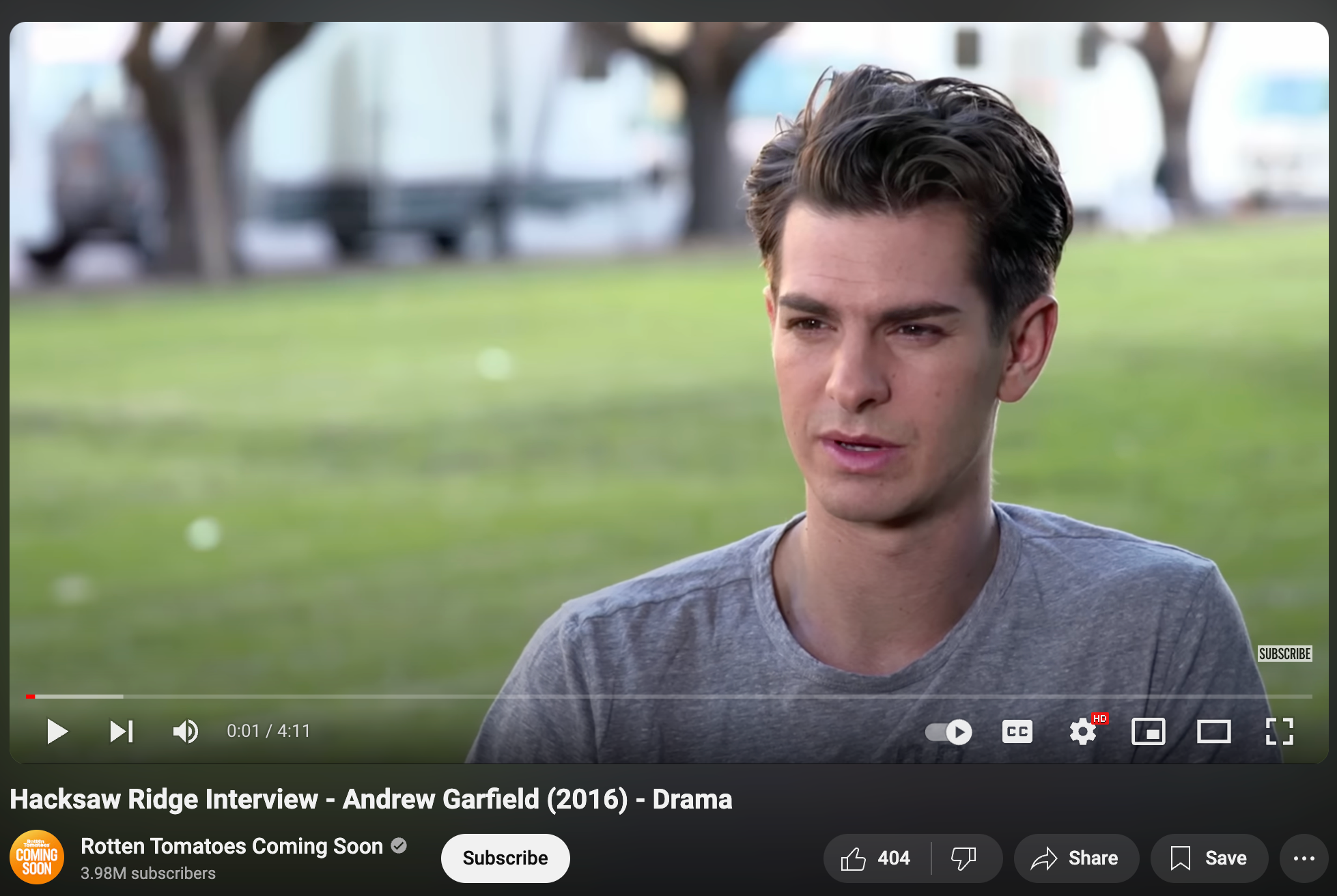
영상 분석 예시
테스트 영상: “Hacksaw Ridge Interview - Andrew Garfield” (4분 11초)
| 지표 | 값 |
|---|---|
| 총 프레임 수 | 6,024 |
| FPS | 23.97 |
| 얼굴 감지율 | 98.26% |
| 프레임당 평균 얼굴 수 | 1.0 |
| 생성된 클립 수 | 26 |
음성 분류
Speech: 88.89%
Rustling leaves: 1.12%
Rustle: 0.74%
음성 신뢰도가 높아 음성 분리가 불필요합니다.
자세 추정 예시
정면 클립:
- Yaw: 0.65°, Pitch: 4.07°
- 방향: “Forward”

오른쪽 방향 클립:
- Yaw: 10.36°, Pitch: -1.22°
- 방향: “Right”

감정 분류
모델은 감정 간에 불확실성을 보였으며, 최고 확률이 약 25%였습니다. 이는 정지 이미지에서의 감정 감지가 얼마나 복잡한지를 보여줍니다.
4. 향후 계획
- 추가 분류 기능: 독순술, 제스처 감지
- GPU 가속: 리소스 제한으로 현재는 CPU만 사용
- 파인튜닝된 모델: 특정 태스크를 위한 커스텀 모델
- 고급 감정 감지: 정지 이미지를 넘어선 멀티모달 접근
참고 문헌
- 1adrianb/face-alignment - 2D 및 3D 얼굴 정렬 라이브러리
- ageitgey/face_recognition - Python용 얼굴 인식 API
- CelebV-HQ - 대규모 영상 얼굴 속성 데이터셋
- danielgatis/rembg - 배경 제거 도구
- dima806/facial_emotions_image_detection - Hugging Face
- facebookresearch/demucs - 음악 소스 분리
- MIT/ast-finetuned-audioset - Audio Spectrogram Transformer