NeMo MSDD와 Pyannote 3.1을 6개의 실제 운영 시나리오에서 비교 평가한 기술 보고서입니다.
테스트 구성: 6개 시나리오, 5개 언어(EN, JA, KO, VI, ZH), 3개 모델 하드웨어: NVIDIA GeForce RTX 4090 날짜: 2025년 12월
요약
3개의 화자 분리 모델을 6개 시나리오에서 평가했습니다.
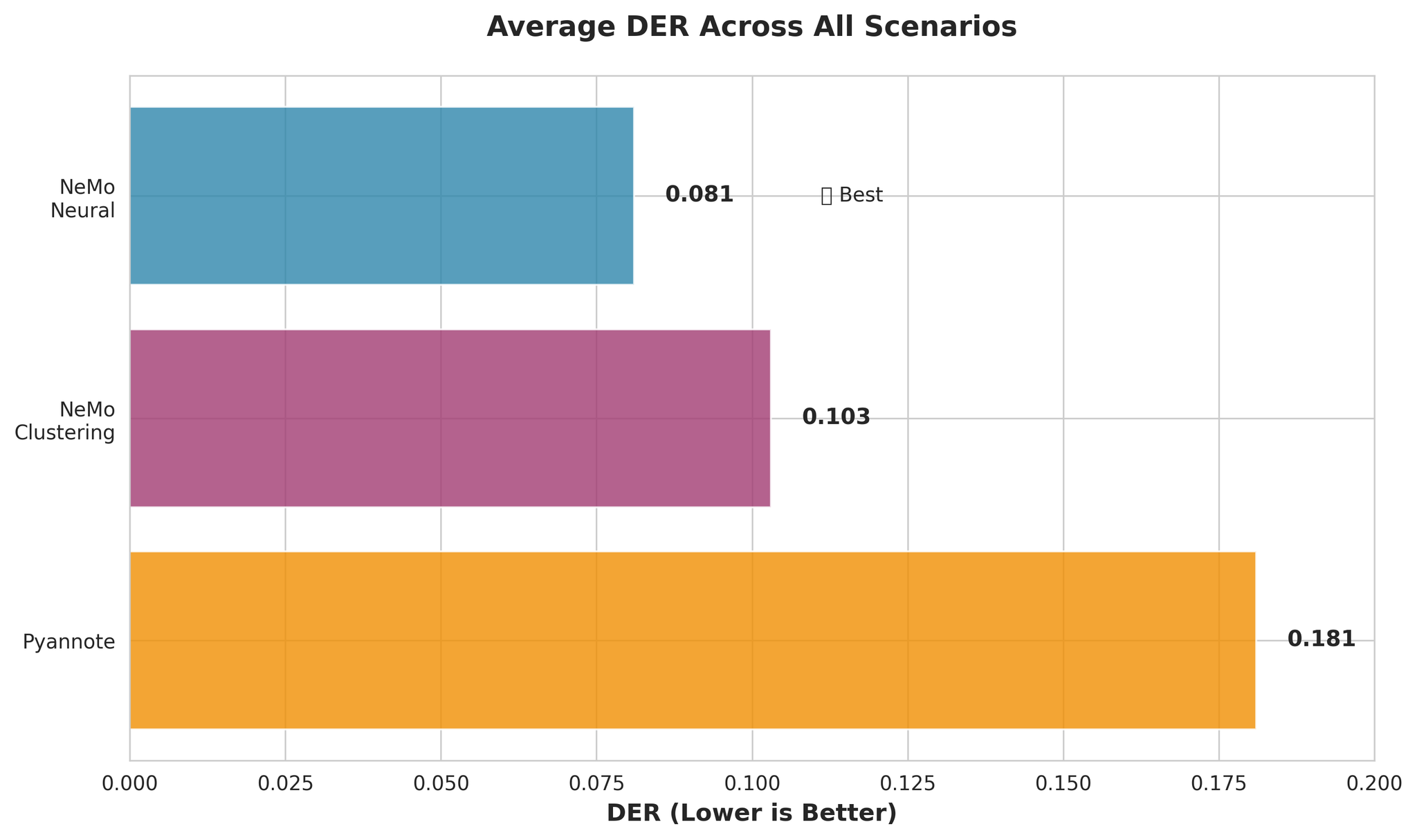
| 모델 | 설명 | 평균 DER | 평균 RTF |
|---|---|---|---|
| NeMo Neural (MSDD) | 신경망 정제를 포함한 Multi-Scale Diarization Decoder | 0.081 | 0.020 |
| NeMo Clustering | MSDD 없이 클러스터링만 사용 | 0.103 | 0.010 |
| Pyannote 3.1 | 엔드투엔드 화자 분리 파이프라인 | 0.181 | 0.027 |
핵심 발견:
- NeMo Neural이 최고 정확도와 빠른 처리 속도를 동시에 달성
- 일본어는 긴 컨텍스트에서 개선: 30분 이상 오디오에서 성능 향상
- 일본어를 제외한 다국어 처리에서 우수한 결과 (DER: 0.050)
1. 서론
프로덕션 환경에 적용할 화자 분리 모델을 선정하기 위해 실제 운영 조건을 반영한 6가지 시나리오에서 평가를 수행했습니다.
- 다양한 오디오 길이 (10분~1시간)
- 다양한 화자 수 (4~14명)
- 다양한 중첩 비율 (0%~40%)
- 다국어 오디오 혼합
2. 테스트 대상 모델
NeMo Neural (MSDD)
- TitaNet-large 기반 192차원 화자 임베딩
- 5개의 시간 스케일(1.0초~3.0초 윈도우)로 오디오 처리
- MSDD 신경망이 초기 클러스터링 결과를 정제
- 평균 RTF: 약 0.015~0.032
NeMo Clustering (순수 클러스터링)
- 동일한 임베딩 모델 (TitaNet-large)
- MSDD 정제 없이 스펙트럼 클러스터링만 사용
- 신경망 정제를 건너뛰어 상당히 빠름
- 평균 RTF: 약 0.014~0.028
Pyannote 3.1
- VAD, 세그멘테이션, 클러스터링을 포함한 엔드투엔드 파이프라인
- pyannote/segmentation-3.0 및 wespeaker 모델 사용
- 평균 RTF: 약 0.018~0.043
3. 평가 설정
3.1 테스트 시나리오
| 시나리오 | 길이 | 화자 수 | 중첩 | 목적 |
|---|---|---|---|---|
| 장시간 오디오 | 10분 | 4~5 | 15% | 표준 프로덕션 |
| 초장시간 | 30분 | 10~12 | 15% | 스트레스 테스트 |
| 1시간 오디오 | 60분 | 12~14 | 15% | 극한 길이 테스트 |
| 높은 중첩 | 15분 | 8~10 | 40% | 최악 케이스 중첩 |
| 다국어 (5개 언어) | 15분 | 8 | 20% | EN+JA+KO+VI+ZH |
| 다국어 (4개 언어) | 15분 | 8 | 20% | EN+KO+VI+ZH (JP 제외) |
3.2 평가 지표
정확도 지표:
- DER Full (collar=0.0초): 가장 엄격한 지표, 경계 허용 없음
- DER Fair (collar=0.25초): 주요 지표, 250ms 허용
- DER Forgiving (collar=0.25초, 중첩 무시): 가장 관대함
DER 구성 요소:
- Miss Rate: 시스템이 놓친 음성
- False Alarm Rate: 비음성을 음성으로 오판
- Confusion Rate: 잘못된 화자에 할당된 음성
4. 전체 성능
4.1 정확도 비교
주요 관찰:
- NeMo Neural이 Pyannote보다 약 55% 더 정확 (DER: 0.081 vs 0.181)
- NeMo Clustering도 Neural에 근접한 성능 (단 27% 차이)
- Pyannote의 Confusion Rate이 3.4배 더 높음
4.2 처리 속도 비교
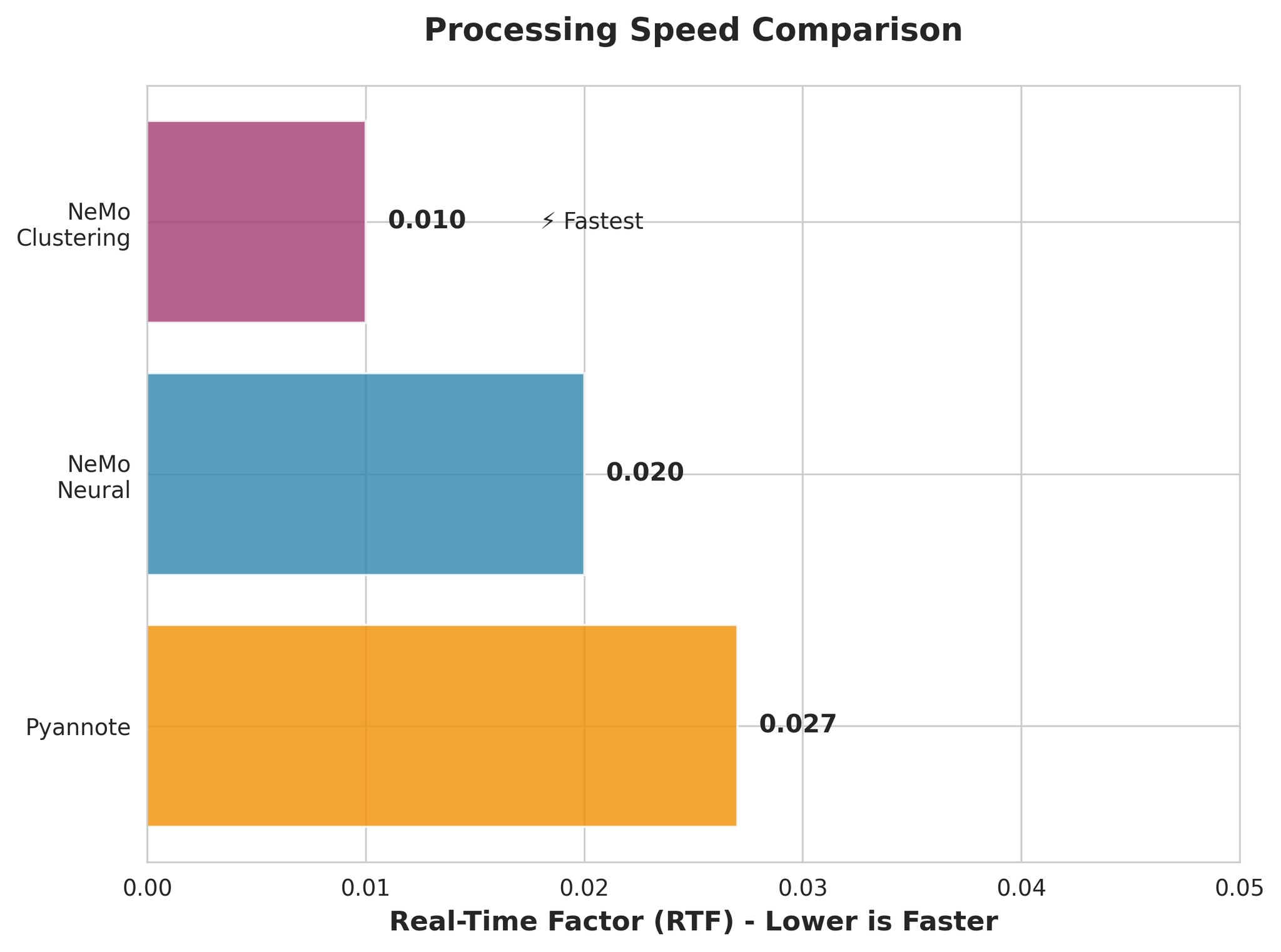
- NeMo Clustering이 가장 빠름 (RTF 0.010)
- NeMo Neural도 매우 빠름 (RTF 0.020)
- 모든 모델이 실시간보다 훨씬 빠름
4.3 정확도 vs 속도 트레이드오프
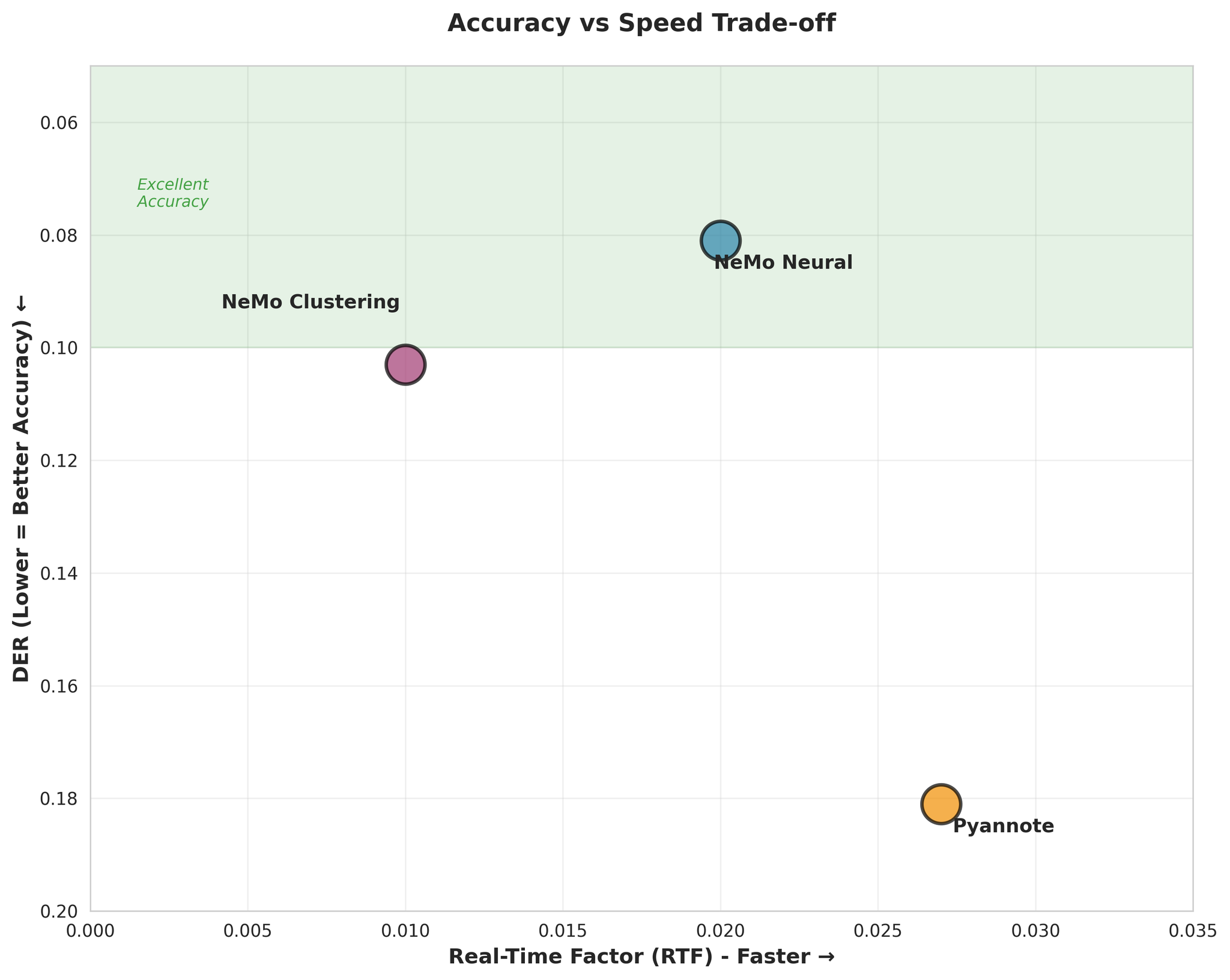
핵심 발견: NeMo Neural이 최고 정확도와 빠른 속도를 동시에 달성하여, 대부분의 사용 사례에서 최적의 선택입니다.
5. 시나리오별 결과
5.1 장시간 오디오 (10분)
NeMo Neural 언어별 결과:
- EN: 0.019 (우수)
- JA: 0.157 (영어 대비 8.3배 어려움)
- KO: 0.046
- VI: 0.037
- ZH: 0.053
- 평균: 0.062
5.2 초장시간 오디오 (30분)
핵심 발견 - 일본어는 긴 컨텍스트에서 개선:
- 10분 오디오: DER 0.157 (영어 대비 8.3배 어려움)
- 30분 오디오: DER 0.067 (영어 대비 2.9배 어려움)
긴 오디오는 피치 악센트 언어 모델링에 효과적인 음향 컨텍스트를 제공합니다.
5.3 높은 중첩 (40%)
- NeMo Neural과 Clustering이 거의 동일한 성능 (DER: 0.114 vs 0.115)
- Pyannote가 더 어려워함 (DER: 0.202, NeMo 대비 약 77% 나쁨)
- 일본어가 가장 어려운 언어 (DER: 0.232)
6. 언어별 분석
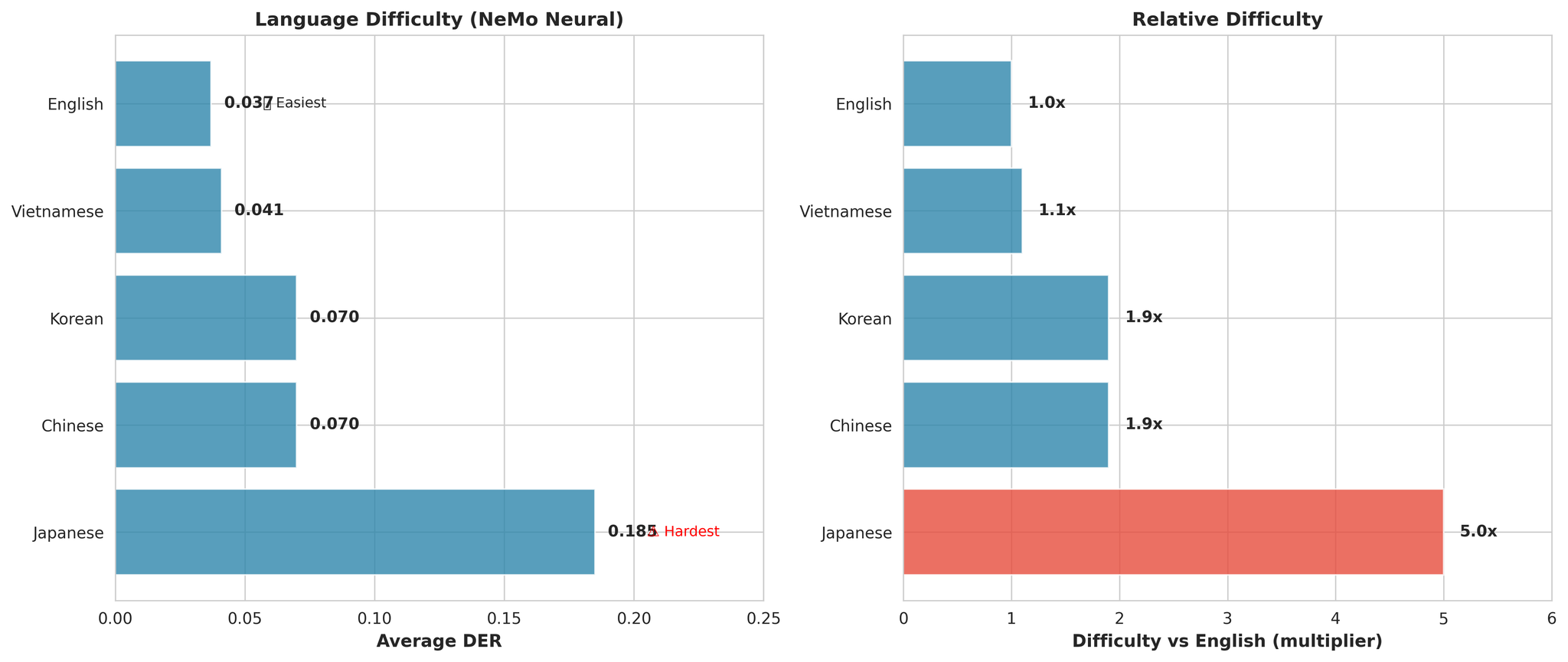
주요 관찰:
- 일본어가 전반적으로 가장 어려움 (영어 대비 평균 5.0배)
- 영어가 가장 쉬움 (DER: 0.037)
- 베트남어가 근소한 차이로 2위 (영어 대비 1.1배만 어려움)
일본어가 어려운 이유
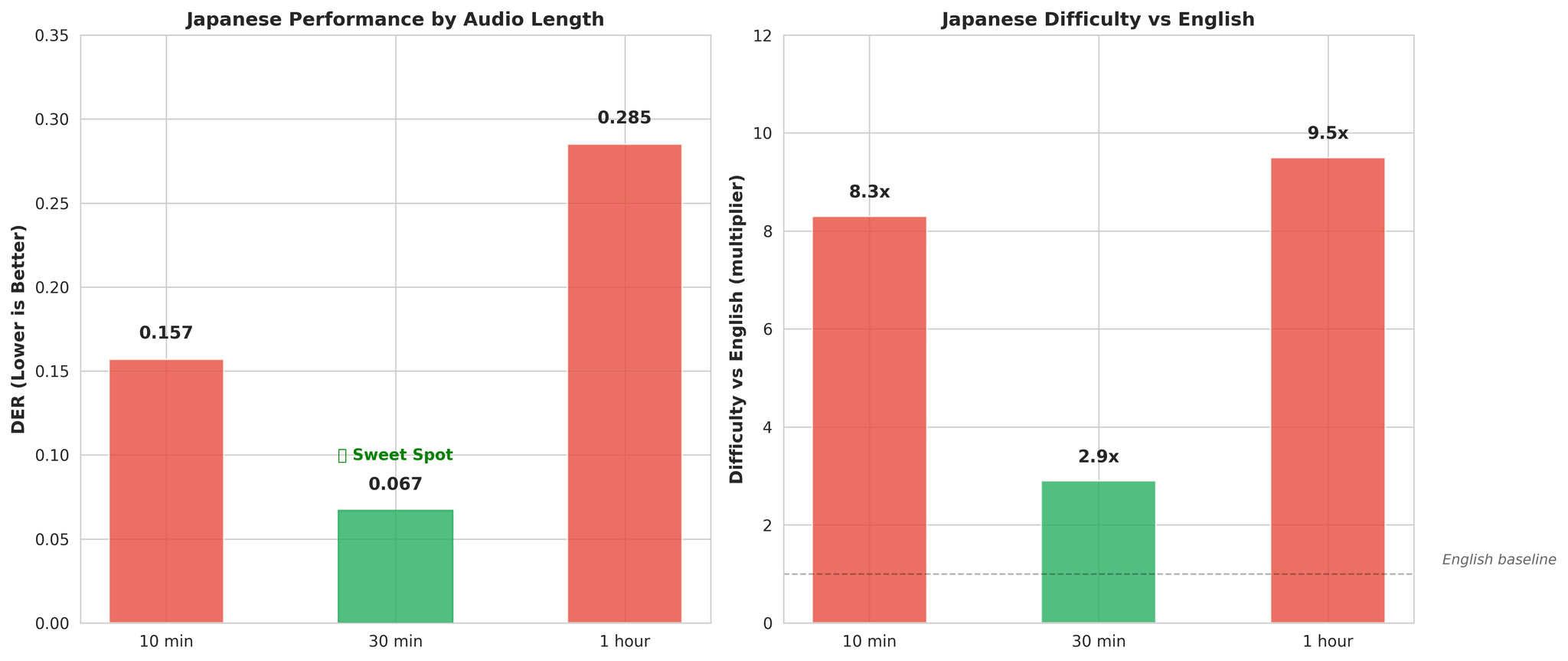
가설:
- 피치 악센트 언어: 피치가 언어적 의미를 담아 화자 임베딩에 혼란
- 좁은 음운 체계: 약 100개 모라 vs 영어의 수천 개 음소
- 짧은 음절 지속 시간: 발화 턴당 시간적 컨텍스트 부족
7. Neural 방식 vs Clustering 방식
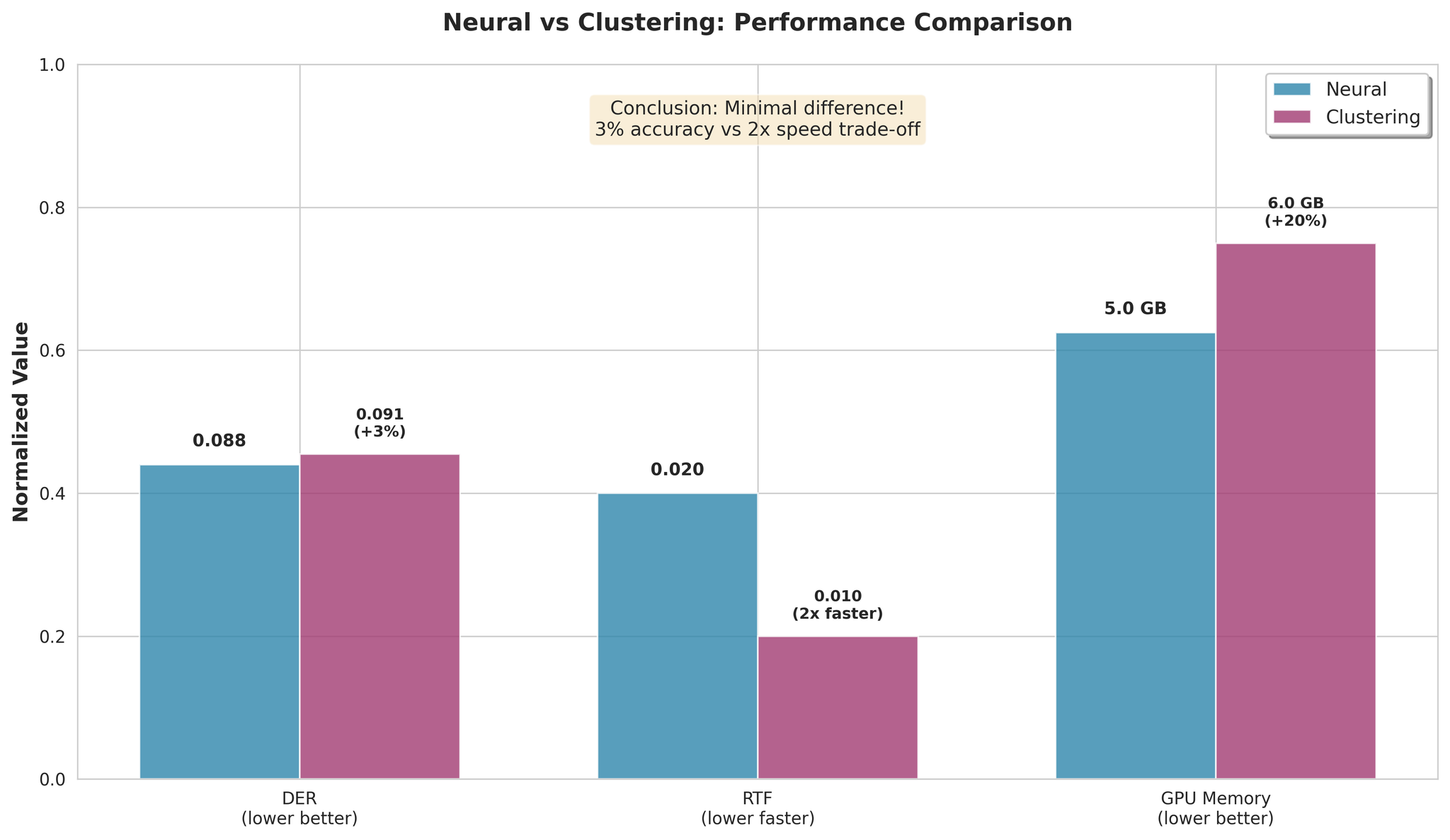
주요 발견:
- Clustering이 평균 3%만 열등
- Clustering이 2배 빠른 처리
- 속도/정확도 트레이드오프가 미미
권장 사항:
- 최고 정확도: NeMo Neural
- 최고 속도: NeMo Clustering (2배 빠름, 3% 성능 차이)
8. 다국어 성능
8.1 일본어의 영향
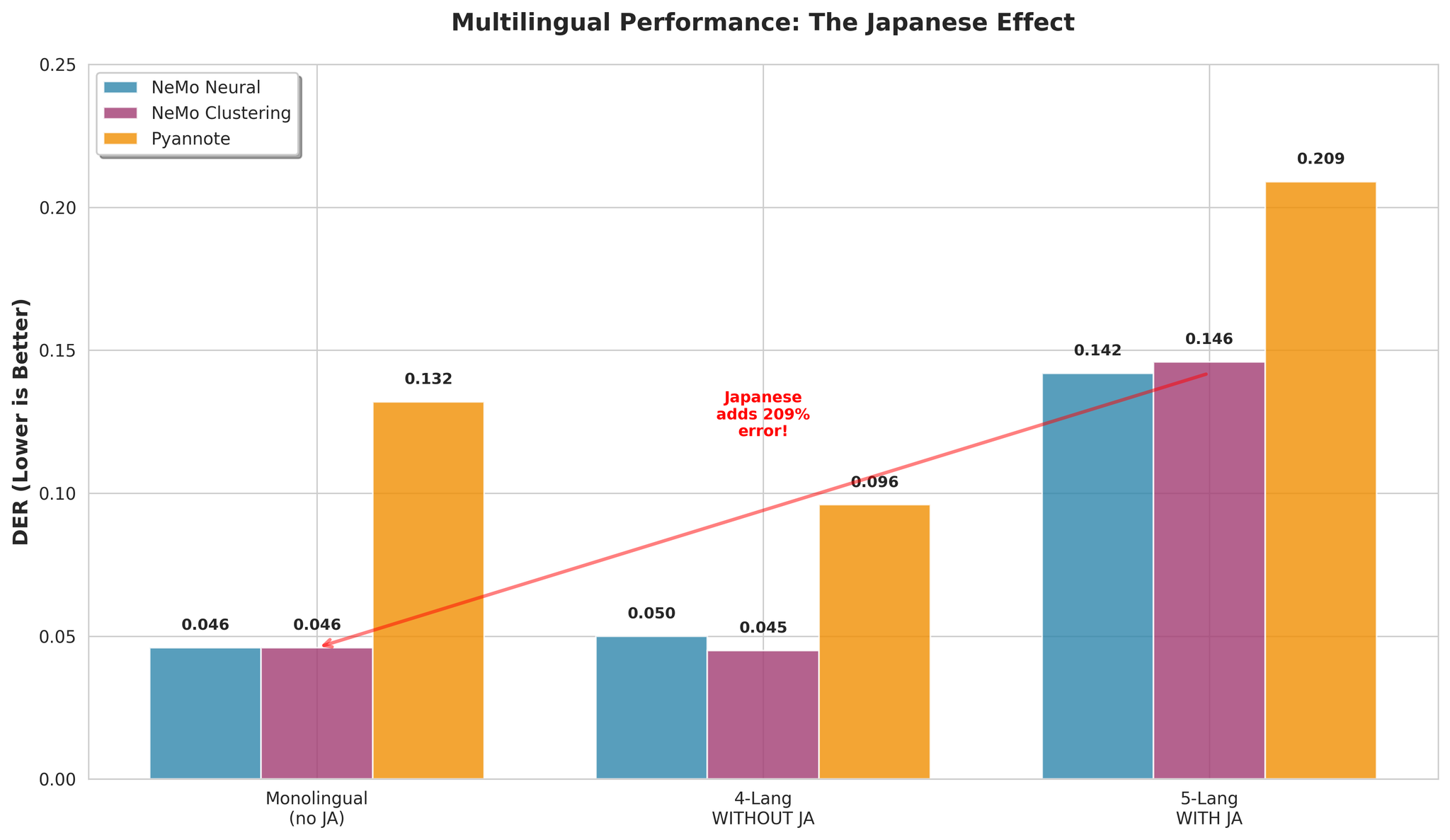
핵심 통찰: 일본어가 다국어 화자 분리를 어렵게 만드는 주요 요인입니다.
| 구성 | NeMo Neural DER |
|---|---|
| 일본어 포함 (5개 언어) | 0.142 |
| 일본어 제외 (4개 언어) | 0.050 |
8.2 오류 분석
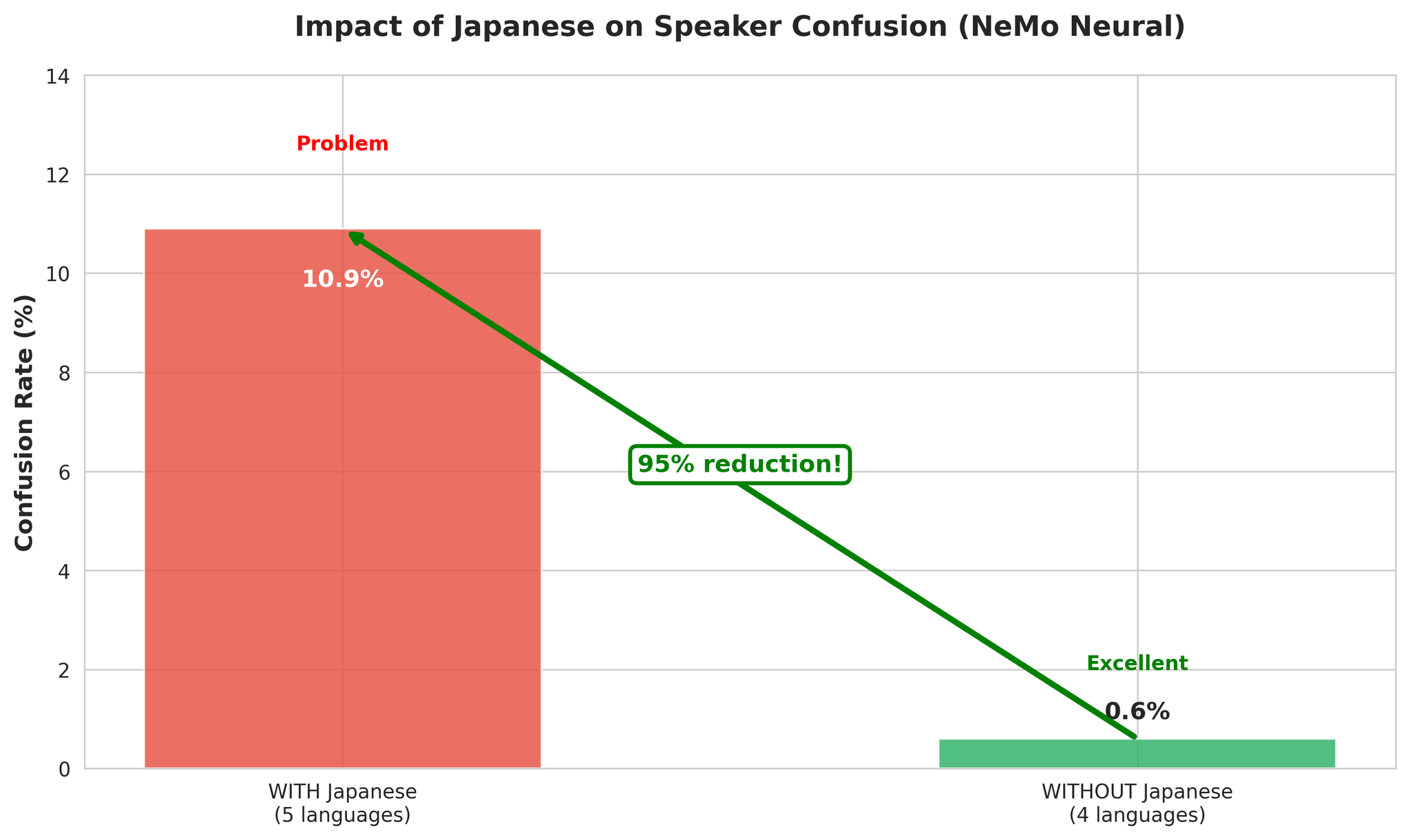
4개 언어 다국어가 좋은 성과를 보이는 이유:
- 음향적 다양성이 VAD의 음성 경계 탐지를 지원
- 언어 전환이 자연스러운 세그먼트 경계를 제공
- EN, KO, VI, ZH는 호환 가능한 음향 특성 보유
- 일본어의 피치 악센트 특성이 교차 언어 화자 혼동을 유발
9. 결론
핵심 결론
NeMo Neural이 최적의 선택:
- 최고 정확도: DER 0.081 (평균)
- 빠른 처리: RTF 0.020 (실시간의 50배)
- 일본어 제외 다국어에서 우수: DER 0.050
주요 발견:
- 일본어는 긴 컨텍스트에서 크게 개선 (30분이 최적)
- 일본어 포함 다국어는 어렵지만 (DER 0.142) 관리 가능
- MSDD 신경망 정제는 클러스터링 대비 소폭 개선 (27% 향상)
- 모든 모델이 빠르고 프로덕션 준비 완료
권장 사항
| 사용 사례 | 모델 | 이유 |
|---|---|---|
| 최고 정확도 | NeMo Neural | DER 0.081 |
| 최고 속도 | NeMo Clustering | 2배 빠름 |
| 장시간 오디오 (30분~1시간) | NeMo Neural | 복잡성 대응 |
| 다국어 (일본어 제외) | NeMo Neural | DER 0.050 |
| 일본어 (30분 이상) | NeMo Neural | 컨텍스트가 도움 |
기본 선택: NeMo Neural - 최고 정확도와 빠른 처리를 겸비.