AISHELL-3 데이터셋과 Bert-VITS2 프레임워크를 활용한 중국어 음성 합성(TTS) 시스템 개발 연구입니다.
개요
본 연구에서는 Bert-VITS2 프레임워크를 활용하여 빠르고 자연스러운 중국어(표준어) 음성 합성(TTS) 시스템을 개발한 결과를 보고합니다. 회의 시나리오에 특화되어, 명확하고 표현력 있으며 문맥에 적합한 음성 생성을 목표로 합니다.
주요 성과:
- 비교 모델 중 최저 WER 0.27 달성
- 음성 자연스러움 MOS 2.90 달성
- 최대 22초 음성 합성 성공
- AISHELL-3 데이터셋(85시간, 218명 화자)으로 학습
1. 서론
음성 합성(TTS)이란
음성 합성(TTS) 기술은 작성된 텍스트를 자연스러운 음성으로 변환합니다. 최신 TTS 시스템은 딥러닝을 활용하여 점점 더 자연스럽고 풍부한 표현의 음성을 생성하고 있으며, 주요 응용 분야는 다음과 같습니다.
- 지능형 어시스턴트
- 접근성 높은 읽기 솔루션
- 내비게이션 시스템
- 자동화된 고객 서비스
왜 중국어인가
중국어(표준어)는 10억 명 이상의 화자를 가진 세계 최대 언어입니다. 그러나 성조 언어라는 특성과 복잡한 언어 구조로 인해 TTS에서 독특한 도전 과제를 제시합니다.
Bert-VITS2란
Bert-VITS2는 사전 학습된 언어 모델과 최신 음성 합성 기술을 결합한 시스템입니다.
- BERT 통합: 의미적, 문맥적 뉘앙스에 대한 깊은 이해
- GAN 방식 학습: 적대적 학습을 통해 매우 사실적인 음성 생성
- VITS2 기반: 최첨단 음성 합성 아키텍처
2. 방법론
2.1 데이터셋 선정
본 연구에서는 AISHELL-3를 선정했습니다.
- 85시간의 오디오 데이터
- 218명의 화자
- 화자당 평균 약 30분
- 높은 전사 품질
참고: 초기에는 Alimeeting(118.75시간)으로 실험했으나, 전사 품질 부족과 화자당 오디오 시간 부족으로 빈 오디오가 생성되었습니다.
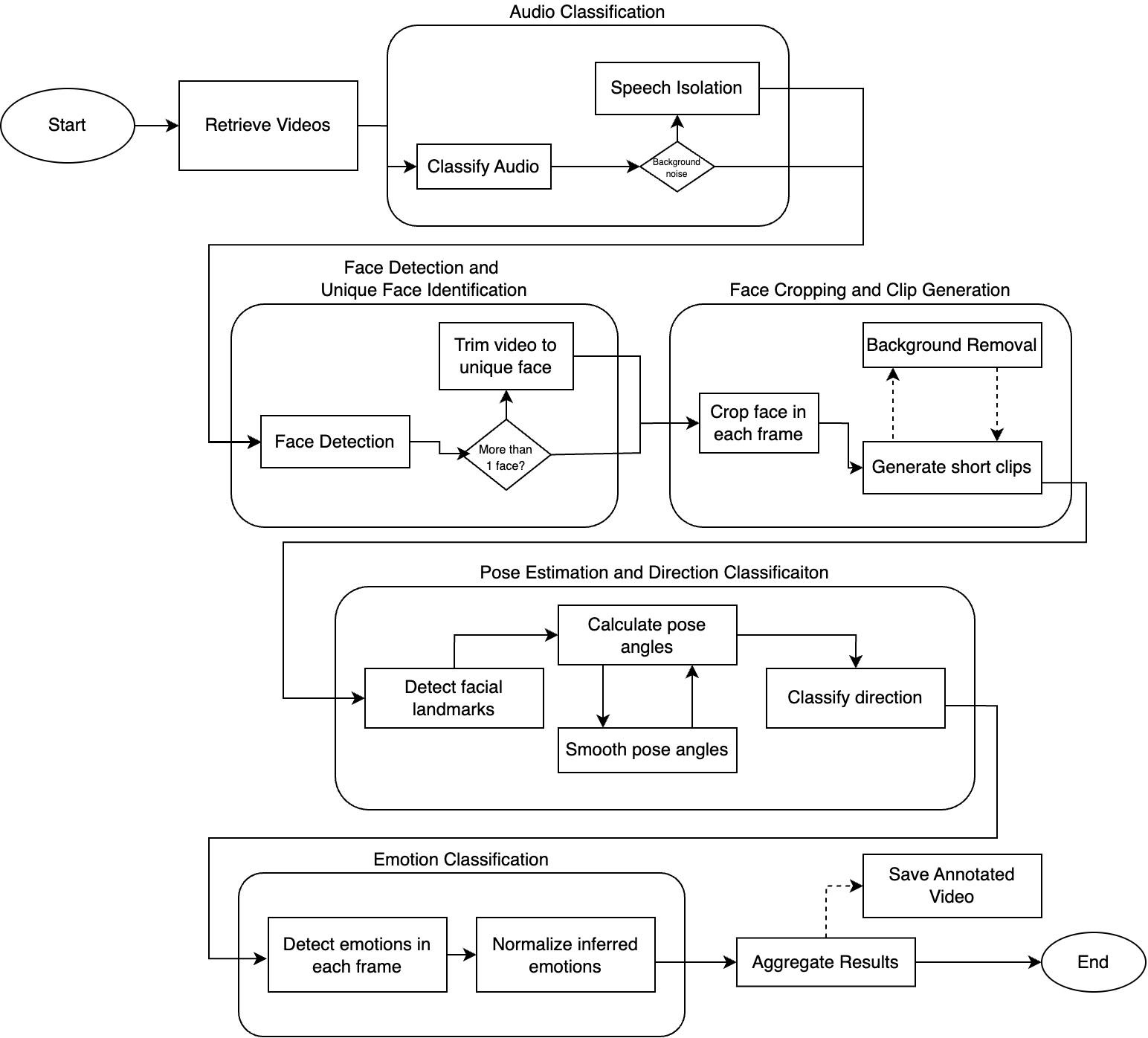
2.2 모델 아키텍처
Bert-VITS2 프레임워크는 네 가지 주요 구성 요소로 이루어져 있습니다.
| 구성 요소 | 기능 |
|---|---|
| TextEncoder | 사전 학습된 BERT로 입력 텍스트를 처리하여 의미를 파악 |
| DurationPredictor | 확률적 변동을 포함한 음소 지속 시간 추정 |
| Flow | 정규화 플로우를 사용한 피치 및 에너지 모델링 |
| Decoder | 최종 음성 파형 합성 |
2.3 학습 과정
손실 함수
- Reconstruction Loss: 생성된 음성을 정답 음성과 일치시킴
- Duration Loss: 음소 지속 시간 예측 오차 최소화
- Adversarial Loss: 사실적인 음성 생성 유도
- Feature Matching Loss: 중간 특징 정렬
모드 붕괴 완화
- 판별기 안정화를 위한 Gradient Penalty
- 생성기와 판별기의 Spectral Normalization
- 복잡도를 점진적으로 높이는 Progressive Training
하이퍼파라미터
| |
팁: RTX 4090 GPU 1대에서 bfloat16 정밀도로 학습을 수행했습니다.
3. 결과 및 논의
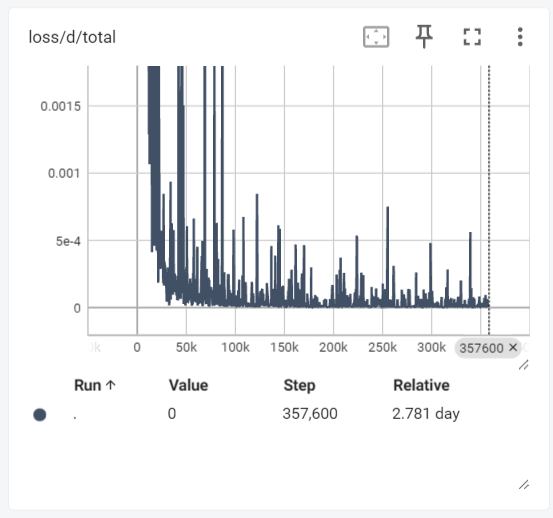
학습 과정
초기 학습에서 모드 붕괴(빈 음성 생성)가 발생했습니다. 조정 후:
- 판별기 손실 안정화
- 생성기 손실의 뚜렷한 하향 추세
- 학습 중 WER이 약 0.5에서 약 0.2로 감소
다른 모델과의 비교
| 모델 | WER | MOS |
|---|---|---|
| 본 모델 (Bert-VITS2) | 0.27 | 2.90 |
| myshell-ai/MeloTTS-Chinese | 5.62 | 3.04 |
| fish-speech (GPT) w/o ref | 0.49 | 3.57 |
참고: 본 모델은 최저 WER을 달성하여 정확한 음성 생성 능력을 보여주었습니다. 다만, MOS(자연스러움) 측면에서는 파라미터가 훨씬 많은 fish-speech에 비해 개선 여지가 있습니다.
생성 예시
다음과 같은 음성 합성에 성공했습니다.
- 짧은 구문 (2~10초)
- 장시간 음성 (22초) - 학습 데이터 범위 밖
한계점
코드 스위칭: 여러 언어가 혼합된 텍스트(예: 중국어에 영어 용어 “Speech processing"이 포함된 경우)는 처리할 수 없습니다.
4. 결론 및 향후 과제
달성 사항
- 중국어 TTS를 위한 Bert-VITS2 파인튜닝 성공
- 비교 모델 중 최저 WER 달성
- GAN 학습의 과제를 완화하는 방법론 습득
- 다양한 길이에서 명확하고 인식 가능한 음성 생성
향후 방향
- MOS 점수 향상을 위한 추가 학습
- 코드 스위칭 한계 해결
- 추가 화자 및 도메인으로의 확장
5. 참고 문헌
- Ren, Y., et al. (2019). “Fastspeech: Fast, robust and controllable text to speech.” NeurIPS.
- Wang, Y., et al. (2017). “Tacotron: Towards end-to-end speech synthesis.” Interspeech.
- Kim, J., et al. (2021). “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech.” ICML.
- Kong, J., et al. (2023). “VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech.” INTERSPEECH.
- Shi, Y., et al. (2020). “AISHELL-3: A Multi-speaker Mandarin TTS Corpus and the Baselines.” ArXiv.
- Saeki, T., et al. (2022). “UTMOS: UTokyo-SaruLab System for VoiceMOS Challenge 2022.” INTERSPEECH.
리소스
- Bert-VITS2 저장소: github.com/fishaudio/Bert-VITS2
- AISHELL-3 데이터셋: openslr.org/93