VoicePingがカスタマイズしたWhisper V2モデルを活用し、単一WebSocketストリーム内で自動・低遅延の言語切替を実現するバイリンガルモードをどのように設計したか。
VoicePingは現在、日本語・英語・中国語(普通話)・広東語・韓国語・ベトナム語が文中で入り混じる本番環境の会議で、バイリンガル音声文字起こしを稼働させています。ユーザーが求めているのは、コードスイッチ(言語切替)が何度起きても途切れない音声認識と翻訳です。本記事では、カスタマイズした Whisper V2 モデルを搭載し、単一 WebSocket ストリーム上で自動・低遅延の言語切替を実現する「バイリンガルモード」の設計について解説します。
目次
- 1. モノリンガルベースライン
- 2. 「バイリンガルモード」が必須である理由
- 3. 素朴な解決策:外部言語検出(とその失敗)
- 4. ブレイクスルー:Whisperに言語を判定させる
- 5. コードスイッチ境界の安定化
- 6. ユニバーサルパディングによる短い音声の安定化
- 7. 運用上の制約:GPU・MPS・並行処理
- 8. まとめ
- 参考文献
1. モノリンガルベースライン
まず従来型のリアルタイムASRスタックから出発しました。
- クライアントが16 kHz PCM音声をストリーミングする。
- VADが音声をスライディングウィンドウ(設定可能なオーバーラップ付き、約Xミリ秒)にチャンク化する。
- Whisper V2派生モデルが固定の
language=jaでデコードする。 - 後処理で部分仮説の重複除去、テキスト補正を行い、WebSocket経由で更新をストリーミングする。
このスライディングウィンドウ+連結パイプラインは、“Streaming Whisper: Enhanced Streaming Speech Recognition”(https://arxiv.org/abs/2307.14743)に記述されたStreaming Whisperアプローチを踏襲しており、バイリンガル機能を重ねる前の安定したベースラインとなりました。
図1:モノリンガルベースライン(単一固定言語)
このアーキテクチャはセッション中に言語が変わらないことを前提としています。バッファ、フレーズバイアシング辞書、メッセージセッションはすべてその単一言語をキーとしています。コードスイッチが発生した途端にシステムは破綻しました。通話中に顧客が日本語から英語に切り替えたとき、サーバーは ja に固定されたままなので、Whisperは文字化けしたテキストか空のテキストを出力します。これを修正するには、人間がWebSocket接続を切断し、セッション言語を再設定して再接続する必要がありました——話者が言語を変えるたびに、毎回その手動操作と強制再接続のサイクルがアーキテクチャ全体のボトルネックになっていました。
2. 「バイリンガルモード」が必須である理由
実際の会議では、言語の切り替えは仮定上のエッジケースではありません。日本語話者がプレゼンし、英語話者の同僚が割り込み、中国語話者のステークホルダーがフォローアップの質問をする。イベントでは、司会者が日本語で進行し、参加者が英語で質問を続ける。従来の単一言語システムでは会話のフローが壊れました。切替のたびに誰かが操作を止め、セッションを再設定して再接続しなければならず、会議が延び、調整コストが増大していたのです。
チームからは繰り返しこう要望されました:「設定した2言語のどちらが話されているか自動で検出し、何も操作しなくても文字起こし(と翻訳)を続けてほしい。」このシンプルな要求がバイリンガルモードの指針となりました。
「Whisperをフル多言語モードのままにすればいいのでは?」と思われるかもしれませんが、本番環境のユーザーは予測可能な出力を期待します。Whisperを無制約で実行すると、90以上の言語のどれでも出力してしまいます。特にリアルタイムの短くノイズの多いバッファでは顕著で、テスト中にJA/ENの会議で突然スペイン語やロシア語のトークンが出現することがありました——話者のつぶやきや咳が別言語の音素に似ていたためです。バッチモードならより長いクリップで再処理できますが、ライブ文字起こしでは致命的です。ユーザーが2言語を選択することで、下流の翻訳、UI、QAがストリームを信頼できるようになります。
これを実現するため、要求を具体的な要件に落とし込みました。
- リアルタイム性: 切替オーバーヘッドを200ミリ秒以内に抑えないとUIがフリーズする。
- 自動化: 会議中にトグルを切り替える人間の介入は不要にする。
- 制約付き言語ペア: ストリームごとに設定された2言語のみ(現在はJA/EN/zh-Hans/zh-Hant/KO/VIの組み合わせ)とし、UXの予測可能性を確保する。
- 安定したセッション: 誤切替は見逃しより有害。フィラーワードのたびに言語が行き来してはならない。
これらの制約により、バイリンガルモードは「あればいい」機能ではなく、システムに不可欠な必須機能となりました。
デモ:バイリンガルモードの動作
3. 素朴な解決策:外部言語検出(とその失敗)
最初のプロトタイプでは、Whisperの前段に言語識別モデルを挿入しました。
図2:外部LIDによる素朴な多言語方式
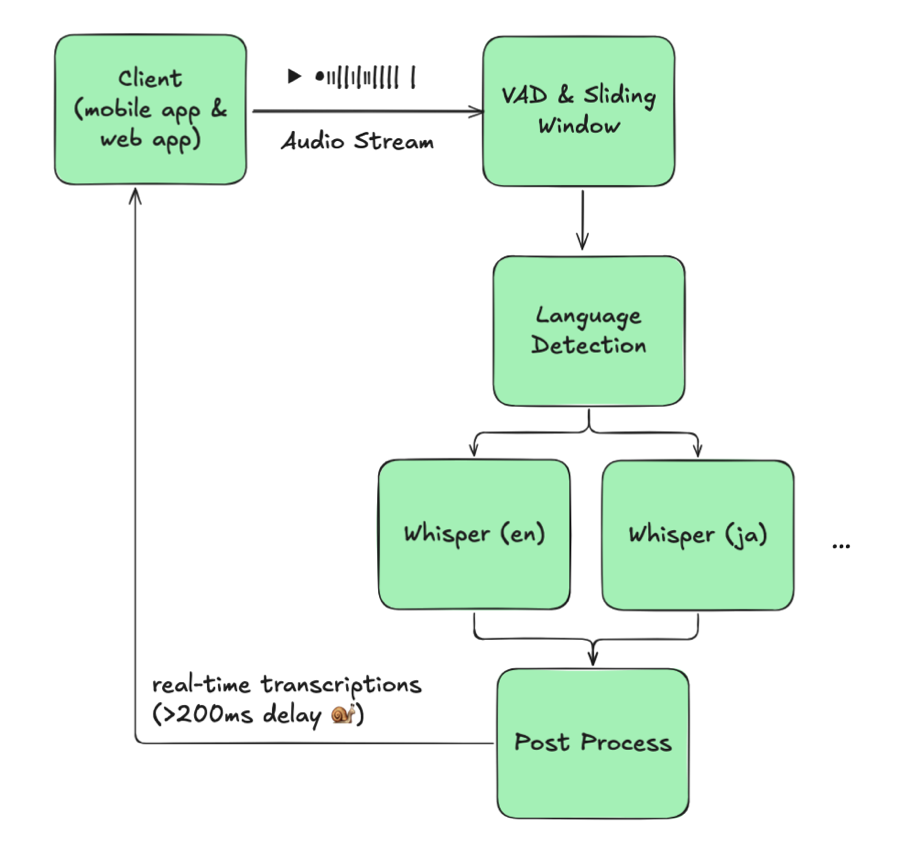
理論はシンプルでした。各バッファの言語を検出し、そのバッファをモノリンガルWhisperインスタンスに渡す。しかし現実は違いました。
根本的な問題は、解消できないトレードオフでした。検出頻度を下げると切替を見逃し、上げると約100ミリ秒の遅延追加とGPU使用量の倍増を招きます。精度と応答性は両立できませんでした。
そのトレードオフを受け入れたとしても、他の障壁が積み重なりました。各言語に専用のWhisperインスタンスが必要で、使用量は均等に分散しません——JA/ENが圧倒的に多く、KOやVIのモデルはGPUを占有しながらほぼアイドル状態です。このアーキテクチャはスケールしませんでした。
フィールドテストでモノリンガルベースラインよりも遅延と精度が悪化したことが判明し、このアプローチは破棄しました。
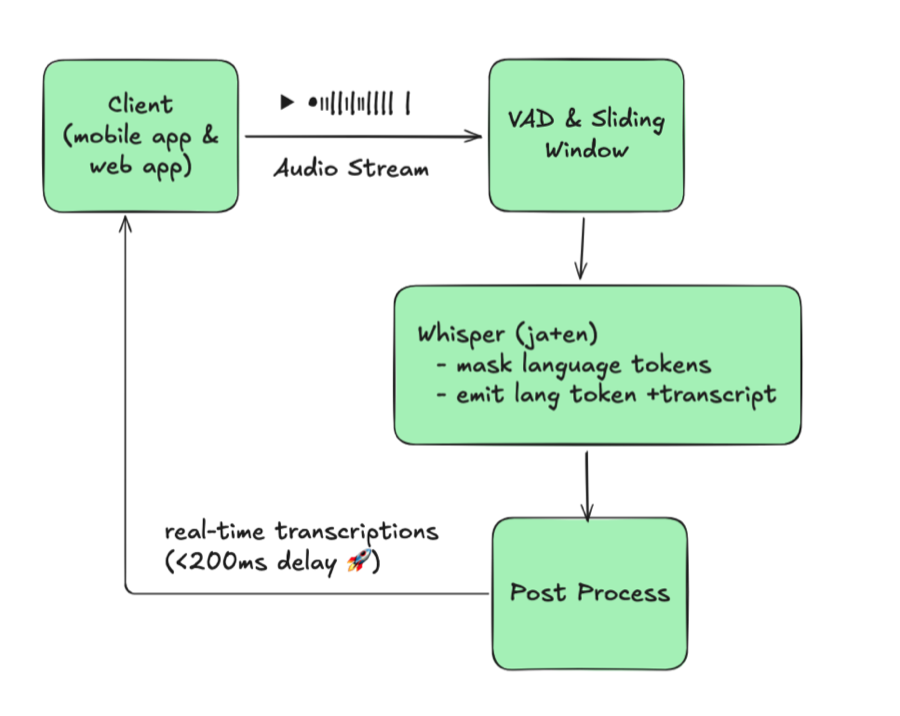
4. ブレイクスルー:Whisperに言語を判定させる
前設計の最も弱いリンクは外部言語検出器でした。Whisperの内部構造を精査したところ、必要なシグナルはモデルが既に出力していることがわかりました——正しい使い方をしていなかっただけです。
4.1 Whisperネイティブ言語検出
Whisperはデコーダの位置1で言語トークン(<|ja|>、<|en|> など)を出力します。デフォルトでは数十の言語をデコードできますが、本番環境では安定性のために単一言語に固定していました。言語トークンを傍受してそのlogitsを制約することで、精度を犠牲にすることなく単一のWhisperモデルを多言語対応にできます。
- 言語トークンの取得: 各ビームの最初のトークンを傍受してデコードし、検出言語として扱う。
- 許可言語の制約: 位置1で設定済みペア(例:JA/EN)のみが出現するようlogitsをマスクする。これにより、音声にノイズがある場合の
<|ru|>のようなランダムな検出を防止する。
| |
この制約により、1回のWhisper推論で文字起こしと言語コードの両方が得られます。追加モデルもルーティングも不要、音声ウィンドウあたり1パスです。
4.2 Whisperネイティブ検出によるアーキテクチャ
図3:Whisperネイティブ言語検出
このレイアウトはモノリンガルベースラインとほぼ同一に見えますが、Whisperが単一セッションで2言語を処理できるようになった点が異なります。1つのモデルで両言語に対応するため、JA/EN/KOのインスタンスを個別に起動したりルーティングを管理したりする必要がなくなりました。素朴な設計と比較して、言語識別ステージの完全な排除、言語ごとのモデル重複の解消、そして遅延の横ばい維持を達成しました。
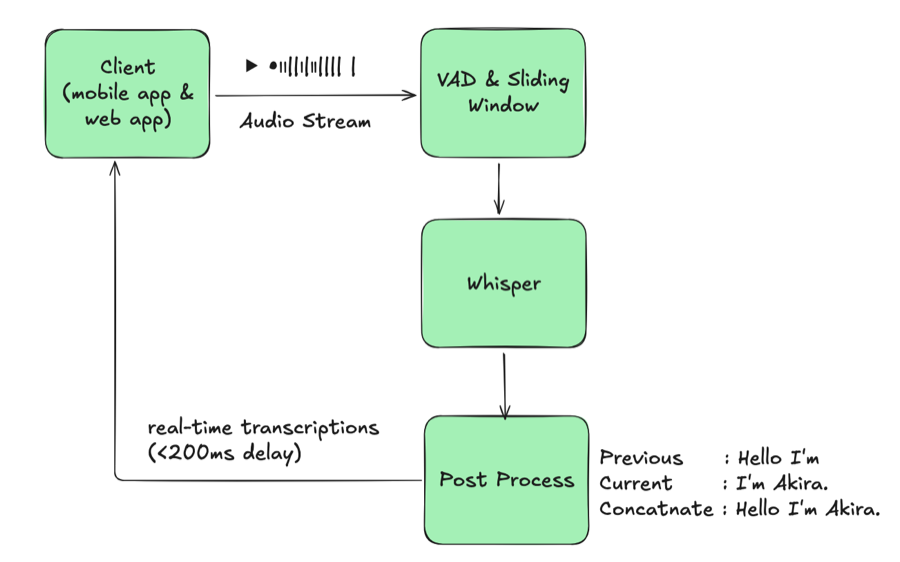
5. コードスイッチ境界の安定化
Whisperが検出言語トークンを出力するようになりましたが、トークンごとに切替を発行するとトランスクリプトが振動してしまいます。実際の会話では、言語の切替は徐々に起こります——フィラー、ためらい、混合語が現れてから話者が完全に言語を変えます。ガードレールがないと、出力は以下のようになりました。
| |
認識器は数フレームごとにJAとENを行き来し、読者にも下流システムにも使えないインターリーブされたテキストを生成しました。まずヒステリシスを追加し、連続する複数フレームが信頼度閾値を超えて同一言語トークンを出力した場合にのみ、言語切替を確定するようにしました。ノイズの多い「I / いあ / I am」のようなバーストはこのルールで消えます。
短いテキストの解決が最大の安定化レバーでした。6文字未満のフラグメントは、日本語のかな、明らかな英字、韓国語のハングル、ベトナム語のマーカーを簡易なヒューリスティクスでチェックします。日本語と中国語はどちらも漢字を使うため、ルールはあえて緩めに設定しています。シグナルが曖昧な場合は、切り替えるのではなく、直前に確定した言語を維持します。
| |
このシンプルな工夫により、「um」や「えー」のようなフィラーがセッションを繰り返しトグルすることを防止します。
新しい言語が確定すると、既存の部分トランスクリプトをファイナライズし、補正ジョブを起動し、Whisperのバッファをリセットして新しいセッション/メッセージIDで開始します。このハードバウンダリにより、JAとENのテキストが下流の翻訳や分析のためにきれいに分離されます。最後に、VAD由来の無音区間を活用して自然なポーズ中にバッファ内テキストをフラッシュし、発話の途中で単語を分割しないようにしています。
これらのレイヤーが揃うことで、コードスイッチが断片的なスクランブルではなく意図的なハンドオフとして見えるようになり、下流の翻訳や検索の信頼性が保たれます。
6. ユニバーサルパディングによる短い音声の安定化
短いバッファは非常に不安定で、Whisperがハルシネーションを起こし、言語トークンがランダムに変動します。私たちの解決策は直感に反するものでした——バッファをモデルに送る前に、言語的に中立なパディングクリップ(“Okay, bye bye.")を先頭に付加するのです。このパディング音声はデコーダを安定させるのに十分な長さでありながら言語的に中立であり、キャプチャ音声が設定可能なカットオフ(数秒程度)より短い場合にのみ挿入するため、長い発話には影響しません。さらに、クリップが固定なのでビームサーチはすぐにそれを無視するようになり、言語トークンは十分なコンテキストを得て安定します。
| |
このように短いクリップにパディングを施すことで、混合言語を含む短い音声セグメントのハルシネーションが大幅に減少します。
7. 運用上の制約:GPU・MPS・並行処理
マルチASRはスケールできなければ意味がないため、コンシューマ向けRTXシリーズGPUにデプロイし、CUDAのMulti-Process Serviceを活用して推論パイプラインの稼働率を維持しています。
一般的なRTX 5090では、3つのWhisper V2ワーカー(各約2 GB、合計約6〜7 GB)がカードの約30 GBメモリを共有するため、VRAMがボトルネックになることはありません。制約となるのはCUDAコアです。
実運用では、このRTX 5090構成で約20〜30のアクティブ音声ストリームを、エンドツーエンド遅延約100ミリ秒で処理できます。4つ目のワーカーを追加してもメモリには収まりますが、遅延がリアルタイム閾値を大きく超えてしまうため、CUDAコアが処理能力の上限を決定しています。
8. まとめ
現在のシステムは、発話中のコードスイッチでもサブ200ミリ秒の遅延を実現し、チューニング済みWhisper V2モデルを自社運用することで予測可能なオンプレミスコストを維持しています。
現行のデプロイメントはストリームあたり2言語に最適化されており、それ以上に拡張するにはUIとポリシーの変更が必要なため、本番ではなくロードマップに位置付けています。
次のステップとして、さらなる遅延削減のためTensorRTやVLLMスタイル推論の実験を進めており、多言語フレーズバイアシングの詳細解説も準備中です。バイリンガルやコードスイッチが頻繁な環境で運用されている方は、ASRモデルから直接言語トークンを読み取ってみてください——必要なシグナルはすでに手元にあるかもしれません。
参考文献
Streaming Whisper: Enhanced Streaming Speech Recognition https://arxiv.org/abs/2307.14743
バイリンガルモード構築にあたり参考にした主なプロジェクト:
SimulStreaming https://github.com/ufal/SimulStreaming
Whisper Streaming https://github.com/ufal/whisper_streaming
WhisperLiveKit https://github.com/QuentinFuxa/WhisperLiveKit
当初、WhisperLiveKit + ストリーミングSortformerを検討し、ダイアライゼーションにより言語トークンの推論頻度を減らせることを期待しました。しかし実際にはSortformerと独自の言語検出の両方を実行する必要があり、遅延の改善はわずかで、Sortformerの攻撃的な挙動は会議での使用に適さないことがわかりました。
NVIDIA Nemotron Speech ASR(まだ試していない新しいリアルタイムASR) https://huggingface.co/blog/nvidia/nemotron-speech-asr-scaling-voice-agents