Voice Activity Detection(VAD)を活用して、クラウドSTTサービスの利用コストを大幅に削減したVoicePingの実装手法を解説します。
この記事では、VoicePingにおけるSpeech to Textの実装の詳細と、開発チームがクラウドサービスの利用効率を最大限に引き出した方法を解説します。
VoicePingは豊富な機能を備え、リモートチームに最適なソリューションです。現在、プレミアムサブスクリプションを1年間無料で提供しています。https://voiceping.net/ からお試しください。
概要
Speech-to-Textをゼロから実装し、高い認識精度を達成することは非常に困難です。そのため、多くの企業や開発者は、優れた認識精度を持ち、多言語に対応したSaaS型のSTTサービスを選択しています。
使用量によっては低コストな解決策となります。「従量課金」方式を採用しているからです。しかし、使用量が増えるとコストが高額になる可能性もあります。使い方と使用量次第です。
この記事では、会議中のユーザー音声にSTTを適用する際の高コストを削減するために、VoicePingが採用している戦略を紹介します。これが可能なのは、会議では大半のユーザーがリスナーであり、会議の大部分で発話しないためです。この戦略は、Voice Activity Detection(VAD)ライブラリを使用して、無音の音声がSTTサービスにストリーミングされるのを防ぐことに基づいています。
また、この戦略を実装する過程で直面したすべての問題と、その解決方法についても紹介します。
はじめに
Speech-to-Text(STT)は、自動音声認識(ASR)とも呼ばれ、多くのユースケースを持つ機能です。例えば、YouTubeで行われているような字幕の自動生成、Siri、Alexa、Cortanaのようなパーソナルバーチャルアシスタント、その他多くの音声対応アプリケーションで活用されています。
VoicePingでは、会議中にリアルタイムの文字起こしを表示するために使用しており、その文字起こしに対してリアルタイム翻訳を表示することが可能です。また、これらの文字起こしをSlackワークスペースのパブリックまたはプライベートチャンネルに自動同期するよう設定でき、社内の業務関連のすべてのコミュニケーションの記録を安全に保持できます。
Slackに同期された文字起こしは、Slackの便利な機能を活用できます。例えば、会議中に割り当てられたタスクに関するメッセージをブックマークしたり、特定の議論事項をチャンネルにピン留めしてチームが忘れないようにしたり、会議が早めに終了して十分な議論ができなかった場合にSlackスレッドで議論を続けることもできます。
実装
音声をテキストに変換するAIシステムの実装は容易ではなく、この記事のような簡単な解説で済む話ではありません。学習と検証のために大量の音声ファイルと文字起こしデータが必要で、対応言語が増えるほど作業量も増大します。
幸いなことに、多くのサービスが利用可能で、その品質は日々向上しています。場合によっては、プロの人間の文字起こし担当者に匹敵する精度を実現しています。ただし、アプリのユーザー数や収益状況によっては、これらのサービスは高額で持続不可能な場合があります。コスト問題を回避するための2つのソリューションを紹介します。
1つ目は最も安価なオプションで、無料サービスを利用する方法です。多くのサービスには無料枠があり、同時利用数や利用時間に制限が設けられています。無料枠では不十分な場合、課金なしのSaaS型STTソリューションは知りませんが、実験的なWeb Speech APIがあります。Google ChromeやMicrosoft Edgeなど、一部のブラウザではすでに実装されています。
これらは優れていますが、実験的APIであるため全ブラウザが対応しているわけではなく、ユーザーに別のブラウザの使用を求めるのはアプリの評判に影響する可能性があります。また、どの入力デバイスを使用するか選択する方法がなく、.start()を呼ぶとデフォルトの入力デバイスから録音が始まるという制限もあります。
そのため、サードパーティサービスを選択し、その上でコスト削減の方法を見つけることにしました。次のセクションでこの2つ目のソリューションについて説明します。
コスト削減
このようなサービスを利用する場合、サーバーに生成するワークロードに応じて課金されるのは当然です。Speech to Textソリューションでは、1時間あたり約1.00〜1.50 USDの料金がかかります。月間80,000時間以上の非常に大量の利用の場合、1時間あたり約0.50 USDまで下がることもあります。そして最も問題なのは、音声ストリームや音声ファイルを処理に送信する際、音声に発話が含まれていようがいまいが、サービス側はそれを処理すべきバイト列としてしか見ないことです。受信帯域幅のコストがあり、無音の処理コストがいくらか低いとしても、処理はしているため課金されます。
VoicePingでは、5人参加の1時間の会議があれば、その1つの会議だけで5 USDの支払いが必要になります。同じチームが月に6回この会議を行えば30 USD。参加者が5人ではなく10人なら60 USD、たった1チームでこの金額です。このようなチームが10チームアプリを使っていれば、月に600 USDになります。有効に活用しているなら問題ありませんが、10人参加の会議の場合、全員が同時に話しているわけではありません。大部分の時間、話しているのは1人だけです。場合によっては誰も話していないこともあります。スクラムのレトロスペクティブミーティングに参加したことがあればわかるでしょう。カウントダウンタイマーを画面に表示し、前回のスプリントの良かった点と改善点を書き出す数分間は、誰も発話しません。これはSTT利用時間の大きな無駄です。
この無駄を解消するために、最も明白な解決策はマイクがミュートされているときにSTTをオフにすることです。私たちもこれを実施しており、使用量を大幅に削減できますが、ユーザーが話していないときにマイクをオフにするかどうかに依存するため、十分ではありません。多くの会議に参加したことがある方ならわかるように、話していないユーザーがマイクをオンにしたままにしていることはよくあります。話すたびにマイクのオン・オフを切り替えるのは面倒ですし、ノイズを出さない限りオンのままでも問題ないからです。
VoicePingではデフォルトで有効になっている優れたノイズリダクション機能のおかげで、会議中ずっとマイクをオンにしていても他の参加者を妨げることはありません。これは別のテーマの記事で扱いますが、VoicePingのノイズリダクションについてはこちらをご覧ください:https://tagdiwalaviral.medium.com/struggles-of-noise-reduction-in-rtc-part-1-cfdaaba8cde7
実際のところ、多くのユーザーがマイクをオンにしたままにしているため、無音音声によるSTT利用時間の無駄を防ぐ必要があります。そこで、音声をSTTサービスに送信する前に、Voice Activity Detection(VAD)を使ってクライアント/ブラウザ側で前処理を行います。
コードを見ていきましょう。まずは初期セットアップと期待される結果からです。
初期セットアップ
ReactとTypeScriptを使用していますので、React Hooksを使用した例を示します。また、Azure Speech to Textサービスを使用していますので、例ではAzure APIを使用しますが、使用量削減の戦略はどのサービスにも有効です。
カスタムフックuseSpeechToTextを作成しました。コードは後ほど示しますが、まずこのカスタムフックを呼び出すルートコンポーネントの例があります。
上記のコードには2つの要素しかありません:
- マイクのミュート/ミュート解除ボタン
- 認識された音声のリスト:
コンポーネントのstateに結果の配列を定義し、showMessage関数で最後のSTT結果を配列に挿入するか、部分的な結果の場合は最後の要素を置き換えます。以下のデモビデオで動作を確認できます。以下の点に注意してください:
上記のコードからわかるように、STTサービスの呼び出しロジックは含まれていません。このロジックはすべてuseSpeechToTextフック内にあり、以下のコードで確認できます。
多くの詳細がありますが、最も重要な部分はサービスにデータを送信する箇所で、onAudioProcess関数内、具体的にはpushStream.write(block.bytes);(73行目)の呼び出しです。使用量を削減するための最も重要な変更はこの行の周辺で行われます。
上記のビデオで確認できるように、マイクがミュート解除されている間、データはサービスに継続的に送信されます。これを修正するために、このフックにVADを統合します。
Voice Activity Detection(VAD)
音声をテキストに変換するのは複雑な処理で、自前で実装するのは困難です。それがサービス料金に見合う理由です。しかし、無音には明らかに発話が含まれておらず、音声に発話が含まれているかどうかを判定することはそれほど複雑ではありません。実際、オープンソースのコードが無料で利用可能なので、車輪の再発明は不要です。これを実現するnpmパッケージが2つあります。
harkパッケージを使用することにしました。非常に使いやすく、再利用可能なフックを作成しました。
このコードは、すでに持っているMediaStreamオブジェクトをパラメータとして受け取り、このストリーム上でharkをインスタンス化し、harkのspeakingイベントとstopped_speakingイベントにユーザーが発話中かどうかを示すboolean stateを設定する関数をバインドします。このstateを使用してSTTのオン・オフを切り替えます。ただし、いくつかの問題に対処する必要があります。次の例で説明します。
VADコードのSTTコードへの統合
useSpeechToTextフックの以前のバージョンでは、サービスにデータを送信すべきかどうかを確認するためにmutedRef react refを使用していました。onAudioProcess関数はAzureのSpeechRecognizerインスタンスをインスタンス化するのと同じuseEffectフック内で定義されているため、Azureインスタンスの再作成を避けるためにrefを使用しました。
VADを統合するために、muted state(パラメータmuted)とuseAudioActiveフックで定義したVAD state(ここではspeakerActive変数として使用)に基づくstreamingFlagRefという新しいフラグを使用します。Azureインスタンスが初期化される前にストリーミングが始まらないようrunning.currentも使用しています。
これらの変数をすべてshouldStream変数のANDブール式で保持し、その変更がstreamingFlagRef refの値を更新するuseEffectをトリガーします。
データをサービスに送信するpushStream.write(block.bytes);の前に、if (!mutedRef.current)の代わりにif (streamingFlagRef.current)をチェックします。コードの変更箇所は以下の通りです。
以下のビデオで確認できるように、発話を停止するとデータの送信が停止しますが、新しい問題が発生しました:
上記のビデオで確認できるように、発話を停止した際にストリーミングが早すぎるタイミングで中断されたようです。これは、サービスが前の文の終わりと次の文の始まりを識別するために発話の一時停止を必要とするからです。少なくとも少しの無音をストリーミングしないと、サーバーは両方の文を一時停止のない1つの連続した文として認識してしまいます。
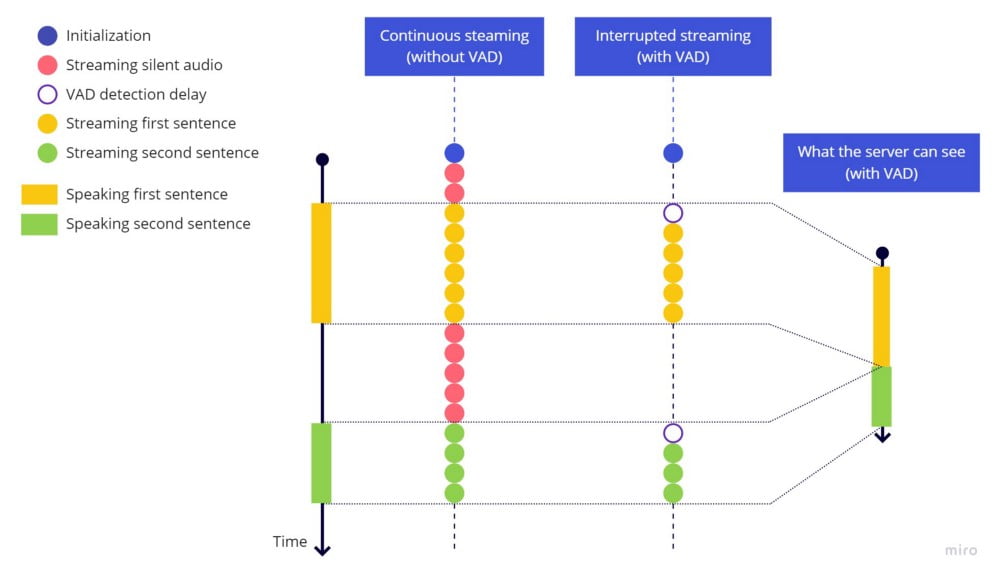 連続ストリーミング(VADなし) vs 中断ストリーミング(VADあり)
連続ストリーミング(VADなし) vs 中断ストリーミング(VADあり)
この問題の簡単な修正は、ストリーミング停止前にタイムアウトを設けることです。ハイライトされた行を追加して試してみましょう。
再度テストすると、以下の結果になります:
ストリーミング停止前のタイムアウトが機能し、各文は適切に終了し、次の文は無音の一時停止後に新しい文として識別されます。しかし、速く話すと文の冒頭が欠けてしまいます。これは、発話を開始してからVADライブラリが音声を検出してストリーミングを再開するまでの遅延によるものです。
実際に起きていることの図解です。各文の冒頭にVAD検出遅延による空白が残っていることに注意してください:
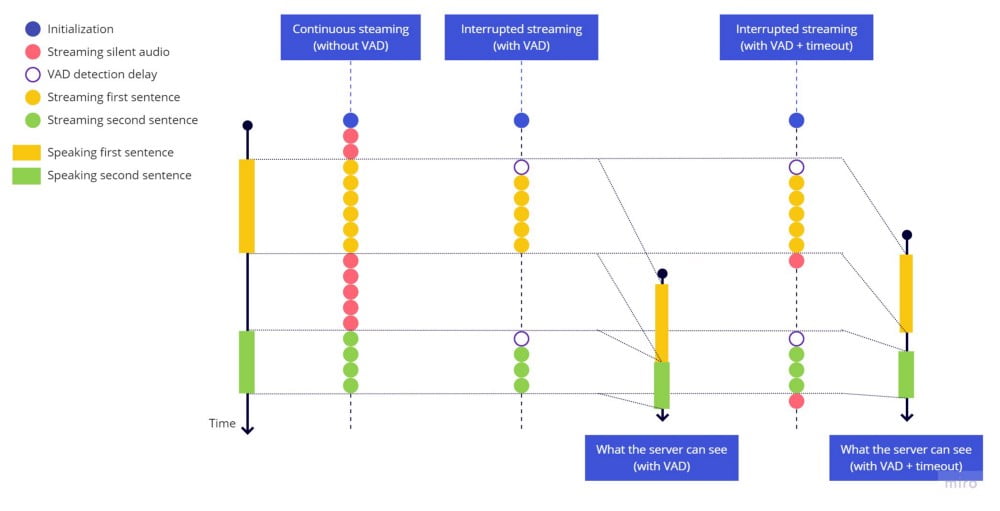 連続ストリーミング vs 中断ストリーミング(VADのみ) vs 中断ストリーミング(VAD+タイムアウト)
連続ストリーミング vs 中断ストリーミング(VADのみ) vs 中断ストリーミング(VAD+タイムアウト)
ストリーミングを開始した時点で、最初の単語の冒頭に対応する音声部分はこの遅延のためにすでに失われています。文末で発生した問題と同様ですが、ここではタイムアウトを追加しても解決できません。過去に実行されるタイムアウトを設定する必要があり、それは不可能だからです。
さらに、VADライブラリが非常に敏感であるため、小さな一時停止でもhark_stoppedがトリガーされ、バウンシング効果が発生してストリーミングが文の途中で何度もスタート・ストップを繰り返す問題が悪化します。
最終的な解決策
2つの問題は関連しており、バウンシングの問題を切り取りの問題なしに示すのが難しいため、両方を同時に処理します。
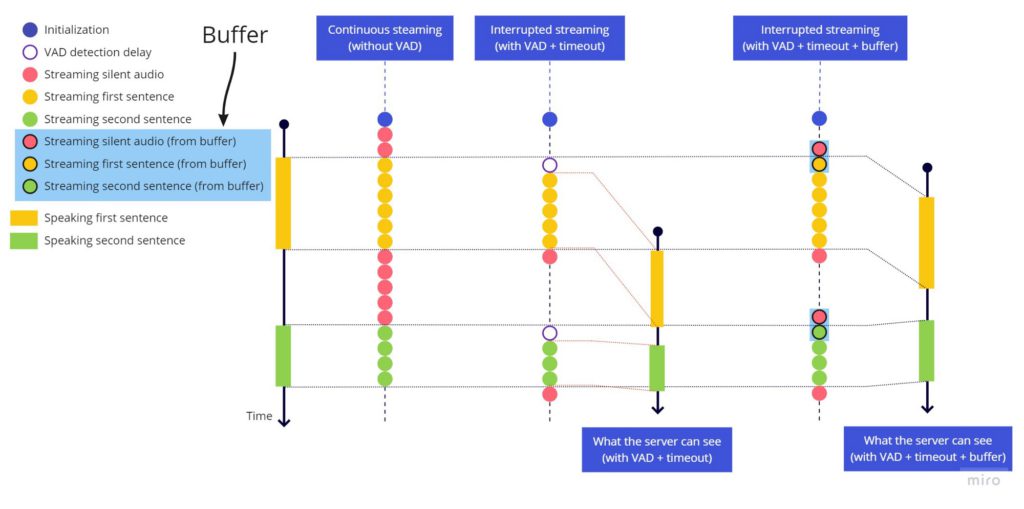
切り取り問題を修正するために、文頭にタイムアウトを追加するのは意味がないため(文末に使用したのと同じ方法では)、常に直近2秒間の音声を保持するバッファを追加します。harkが音声活動を検出すると、ライブストリーミングを送信する直前にバッファ全体を先に送信します。遅延はそれほど大きくありませんが、2秒に設定しました。一部の言語では、発話の開始前に少しの無音/沈黙があった方が認識精度が向上するためです。
バウンシング効果を修正するために、stop_speaking harkイベントがトリガーされたら2秒のタイムアウトを開始し、2秒後にのみストリーミングを停止します。ただし、この期間中に音声活動(speaking harkイベント)が検出された場合は、タイムアウトをキャンセルし、音声活動の停止を検出しなかったかのようにストリーミングを継続します。
変更点は以下の通りです:
ファイル先頭にバッファサイズ(秒)を保持するBUFFER_SECONDS定数を追加
フック実装の先頭にバッファ配列を保持するbufferBlocks refを追加
streamingFlagRef refの値を制御するuseEffectフック内にバウンシング効果を処理するタイムアウトを追加
onAudioProcess内でサービスに音声をストリーミングできるかチェック:
最後のuseEffectクリーンアップ関数内でバッファをクリーンアップし、マイクのミュート/ミュート解除時にクリーンなバッファで開始することを保証
動作を確認しましょう:
音声活動を検出した際にライブストリームの開始前に送信するため、直近の数秒間をいつでも利用可能にするバッファの動作は以下の通りです:
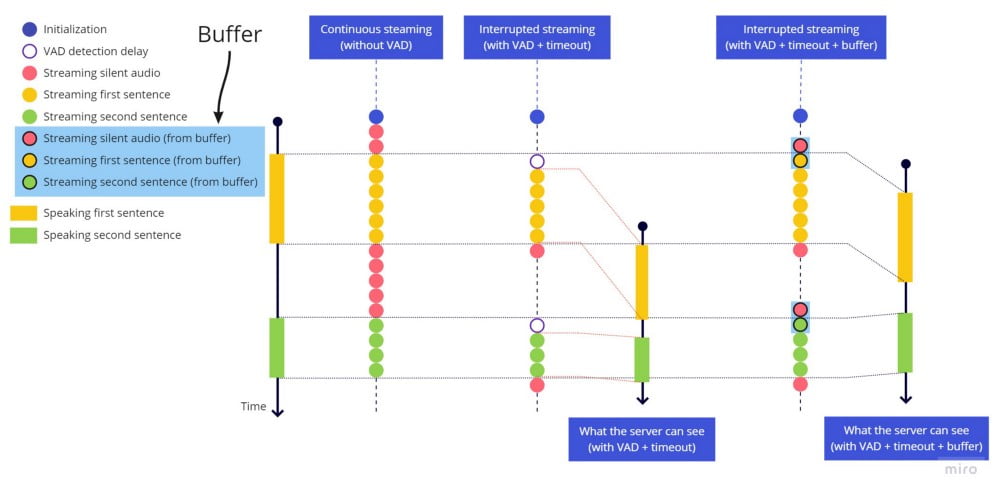 連続ストリーミング(VADなし) vs 中断ストリーミング(VAD+タイムアウト) vs 中断ストリーミング(VAD+タイムアウト+バッファ)
連続ストリーミング(VADなし) vs 中断ストリーミング(VAD+タイムアウト) vs 中断ストリーミング(VAD+タイムアウト+バッファ)
まとめ
Chromeデベロッパーツールのネットワークタブで確認できるように、Azureサービスに送信されるデータは発話中のみです。この記事で解決したすべての問題は、VoicePingの開発中に実際に直面した問題です。このコードは本番環境の現行コードと完全に同じではありません。違いの1つは、createScriptProcessor(非推奨API)をAudioWorkletNodeに置き換え、Web Workerを使用してメインイベントループ外で音声処理を行っている点です。チュートリアルをシンプルに保つため、ここではscript processorバージョンを示しました。
もう1つ推奨するアーキテクチャの変更点は、バウンシング効果のハンドリングをstreamingFlagRefフラグの値を定義するコードに混在させるのではなく、harkの使用をカプセル化するuseAudioActive内に保持することです。私たちのコードではそうしていませんが、useAudioActiveが複数の箇所で使用されており、他の箇所ではバウンシング効果をそのまま維持したいためです。
VoicePingでこれらの機能をぜひお試しください:https://voiceping.net/
ソースコード
以前のすべての変更を適用した最終バージョンです。お読みいただきありがとうございます。


