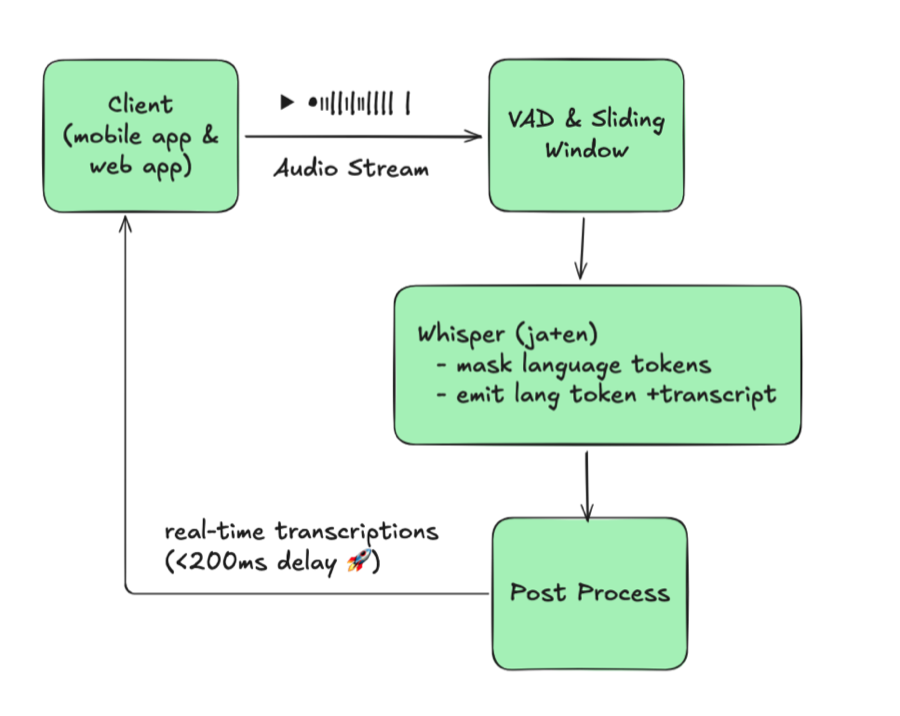
AsyncLLMEngineと適切なContinuous Batching設定により、vLLM推論スループットを82%向上させた方法
前回のおさらい
Part 1では、ボトルネックを特定しました。FastAPIサービスがマルチプロセッシングワーカーとIPCキューで翻訳タスクを分配しており、以下の問題が発生していました:
- キューのシリアライゼーションオーバーヘッド
- ワーカープロセス間のGPU計算リソースの競合
- スパイク状のGPU使用率パターン
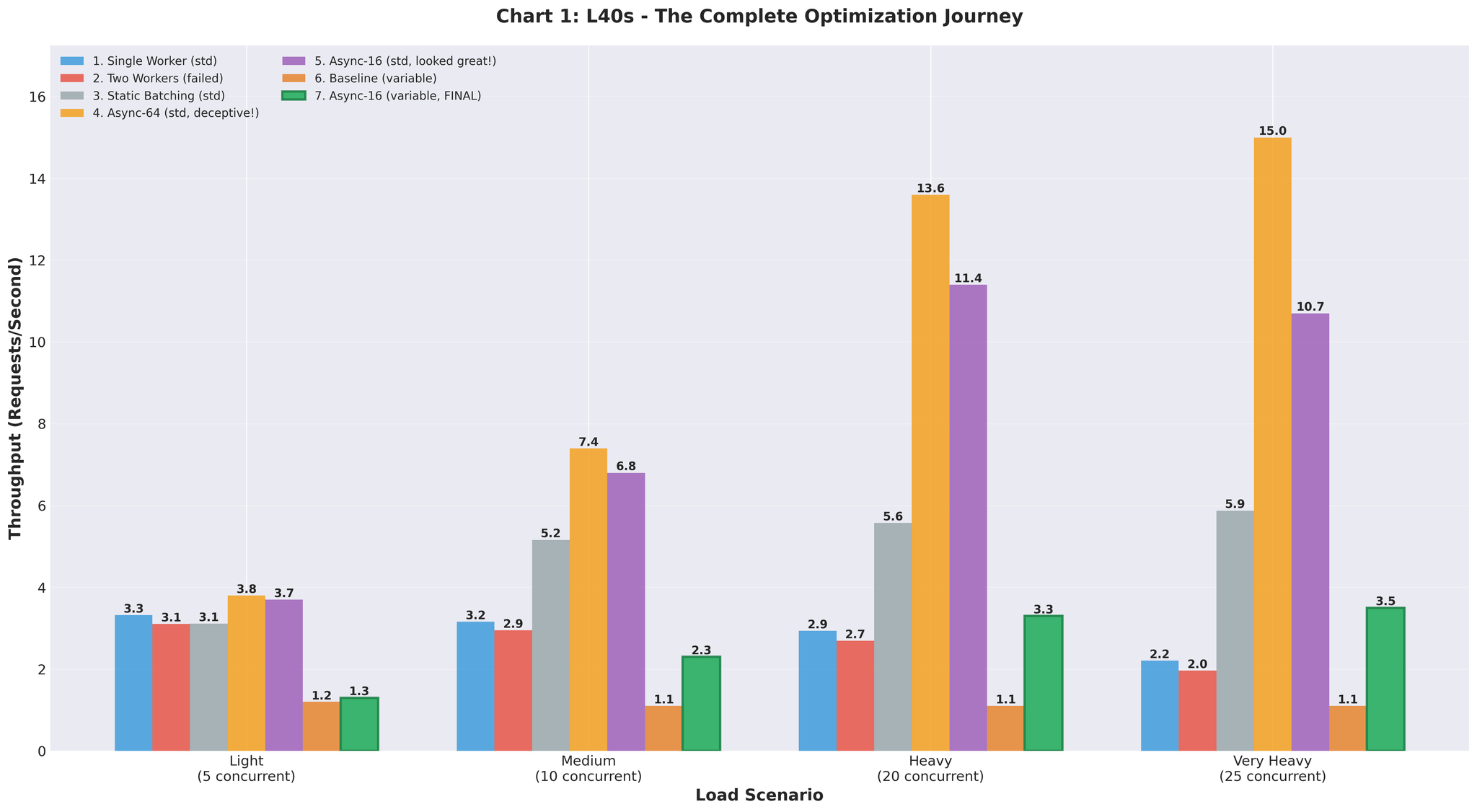
ベースライン:25並行リクエスト時に2.2 RPS
改善の方向性:マルチプロセッシングを排除し、vLLMのバッチ推論を活用する。
試行2:スタティックバッチ処理
既存のワーカープロセス内でスタティックバッチ処理を実装しました。
実装
| |
ポイント:
- バッチサイズ:16リクエスト
- タイムアウト:50ms(バッチが満杯になるまで無限に待たない)
- vLLMが複数シーケンスをまとめて処理
- マルチプロセッシングワーカーはそのまま使用
結果
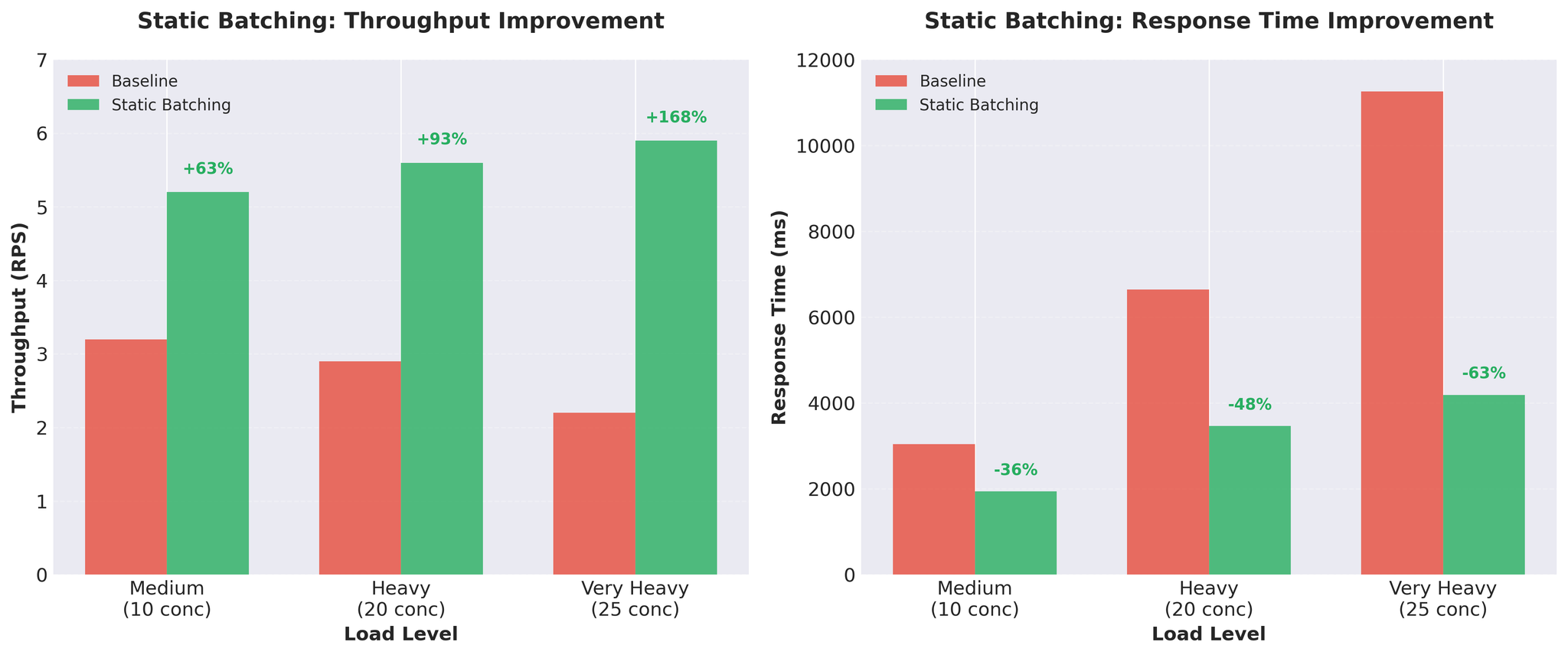
スループットが約3倍に向上。 リクエストあたりの推論時間:452ms → 171ms。
トレードオフ
メリット:
- 大幅なスループット向上
- GPUの活用効率が改善
- シンプルな実装
デメリット:
- Head-of-Lineブロッキング:すべてのリクエストが最も遅いリクエストの完了を待つ
- 入力長が可変の場合、短い翻訳が長い翻訳を待つ
- 例:[50トークン, 50トークン, 200トークン] → 最初の2つが200トークンの翻訳完了を待機
良い進展でしたが、Head-of-Lineブロッキングの問題を解消したいと考えました。
試行3:Continuous Batching
解決策:vLLMのAsyncLLMEngineによるContinuous Batching。
Continuous Batchingとは
スタティックバッチ処理とは異なり、Continuous Batchingはバッチを動的に構成します:
- 新しいリクエストが生成途中でもバッチに参加
- 完了したリクエストはすぐに離脱(他のリクエストを待たない)
- バッチ構成がトークンごとに更新
- vLLMのAsyncLLMEngineがこれを自動的に処理
Head-of-Lineブロッキングなし。 短い翻訳は完了次第すぐに返される。
実装
| |
アーキテクチャの変更点:
- AsyncLLMEngineをFastAPIで直接使用
- vLLMがContinuous Batchingエンジンで内部的にバッチ処理を管理
- 全体がpure async/await
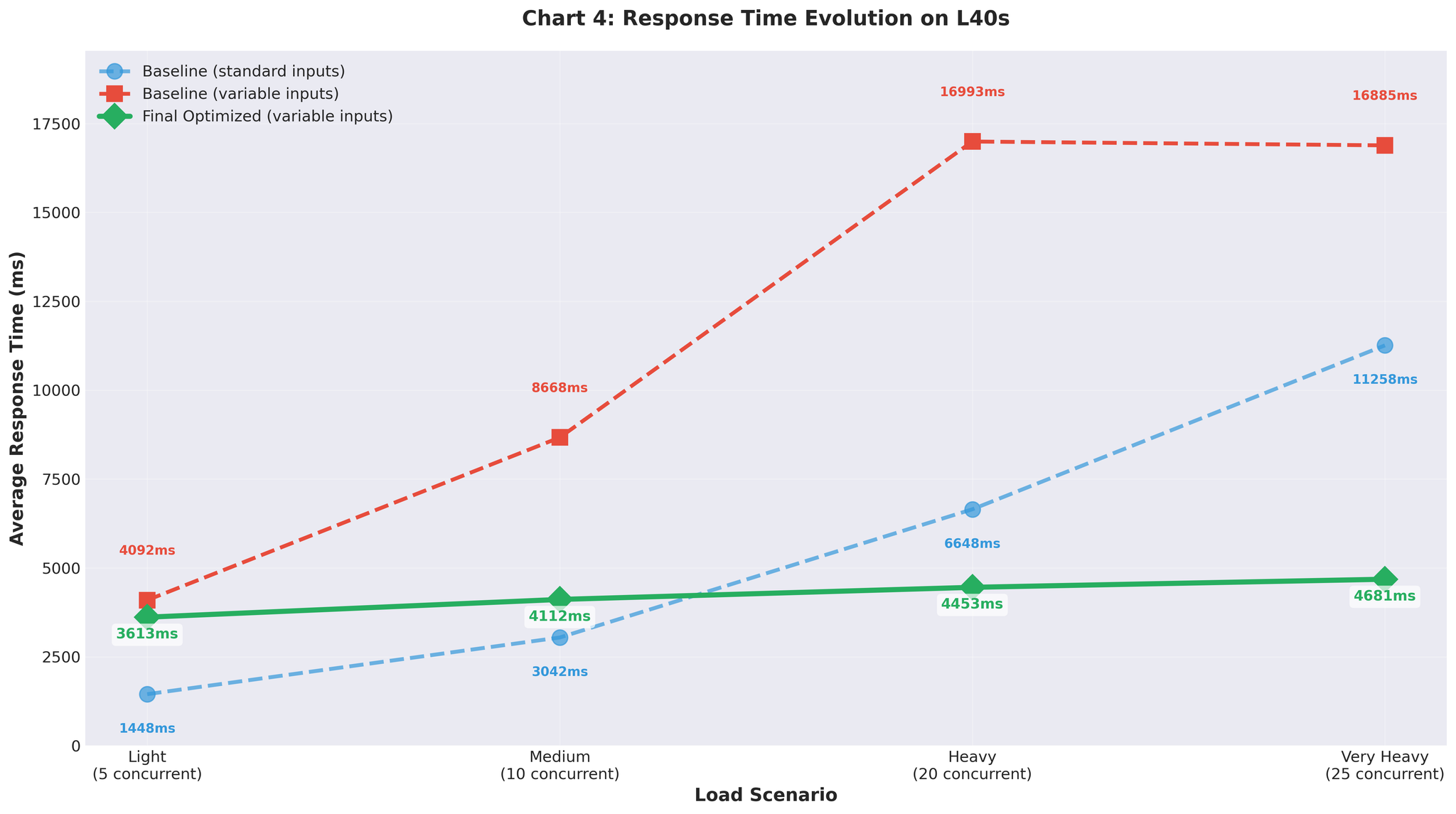
テスト結果の実際
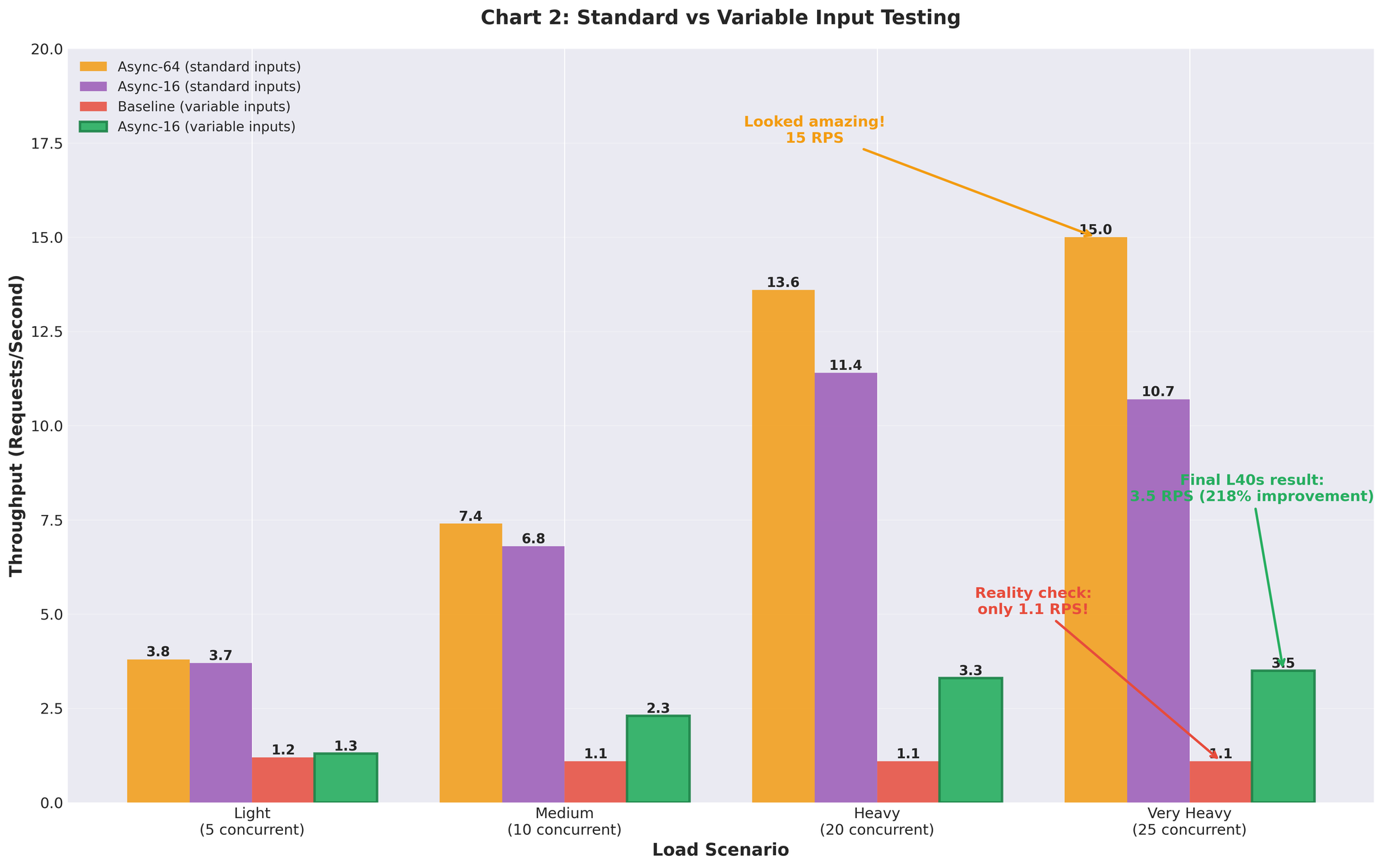
初期結果(均一な入力)
標準的な均一長の入力(類似の長さ)でテスト:
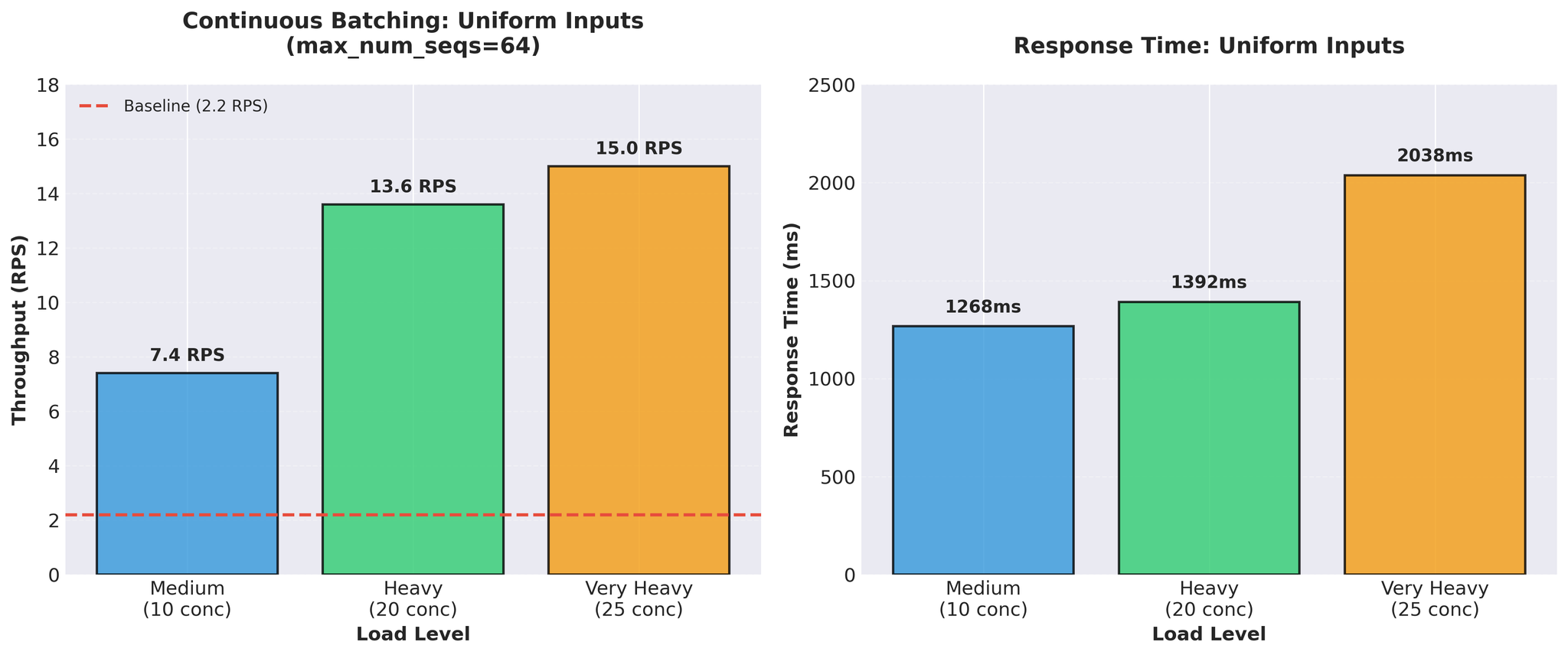
15 RPS vs ベースライン2.2 — 約7倍の改善。素晴らしい結果に見えました。
可変長入力(現実のデータ)
次に、現実的な可変長入力(10〜200トークン、短文と長文の混合)でテスト:
可変入力でのベースライン再実行:
- 非常に高い負荷:1.1 RPS(均一入力時の2.2 RPSと比較)
- ベースラインすら現実的なデータでは性能が低下
可変入力でのContinuous Batching(max_num_seqs=64):
- 非常に高い負荷:3.5 RPS(max_num_seqs=16に調整後)
- 均一入力で15 RPSを達成した同じ設定
設定のチューニング
max_num_seqs=64での可変長入力の性能不足を受けて、vLLMの内部メトリクスを分析しました。
判明したこと
| |
問題点:
- 実際のワークロード:サーバーあたり2〜20の同時リクエスト(本番ピーク時はサーバーあたり約20)
- 設定:max_num_seqs=64
- 結果:60以上の空きスロットがオーバーヘッドを生成
設定が過大な場合に起きること:
- 64シーケンス分のKVキャッシュが事前確保される
- vLLMスケジューラが64スロットを管理するが、実際に使用するのは5〜10個
- トークンあたりのデコード時間が増加
- 未使用シーケンススロットによるメモリの浪費
- 空きスロットに対するスケジューラオーバーヘッド
チューニングのアプローチ
vLLM Continuous Batchingチューニングガイドに基づき:
- 本番環境での実際の同時リクエスト分布を計測
- max_num_seqs=1から開始し、段階的に増加:2 → 4 → 8 → 16 → 32
- 各ステップでデコード時間とテールレイテンシを監視
- 性能が劣化した時点で停止
| max_num_seqs | 結果 |
|---|---|
| 8 | レイテンシは良好だが、スループットが制限される |
| 16 | 最適なバランス |
| 32 | デコード時間が増加し、テールレイテンシが悪化 |
最終設定
| |
設定の根拠
max_num_seqs=16:
- 本番ピーク:サーバーあたり約20の同時リクエスト
- テスト:25の同時リクエストまで検証済み
- リソースを浪費せず余裕を確保
- スケジューラのオーバーヘッドが実負荷に対応
max_num_batched_tokens=8192:
- デフォルトの16384から削減
- 平均シーケンス長に適合
- メモリ圧力を軽減
gpu_memory_utilization=0.3:
- RTX 5090(32GB)でモデル+KVキャッシュに約10GBのVRAMを割り当て
- vllm:gpu_cache_usage_percで追跡
- 構成に適したバランス
注: 原則:設定は理論的な上限ではなく、実際のワークロードに合わせる。
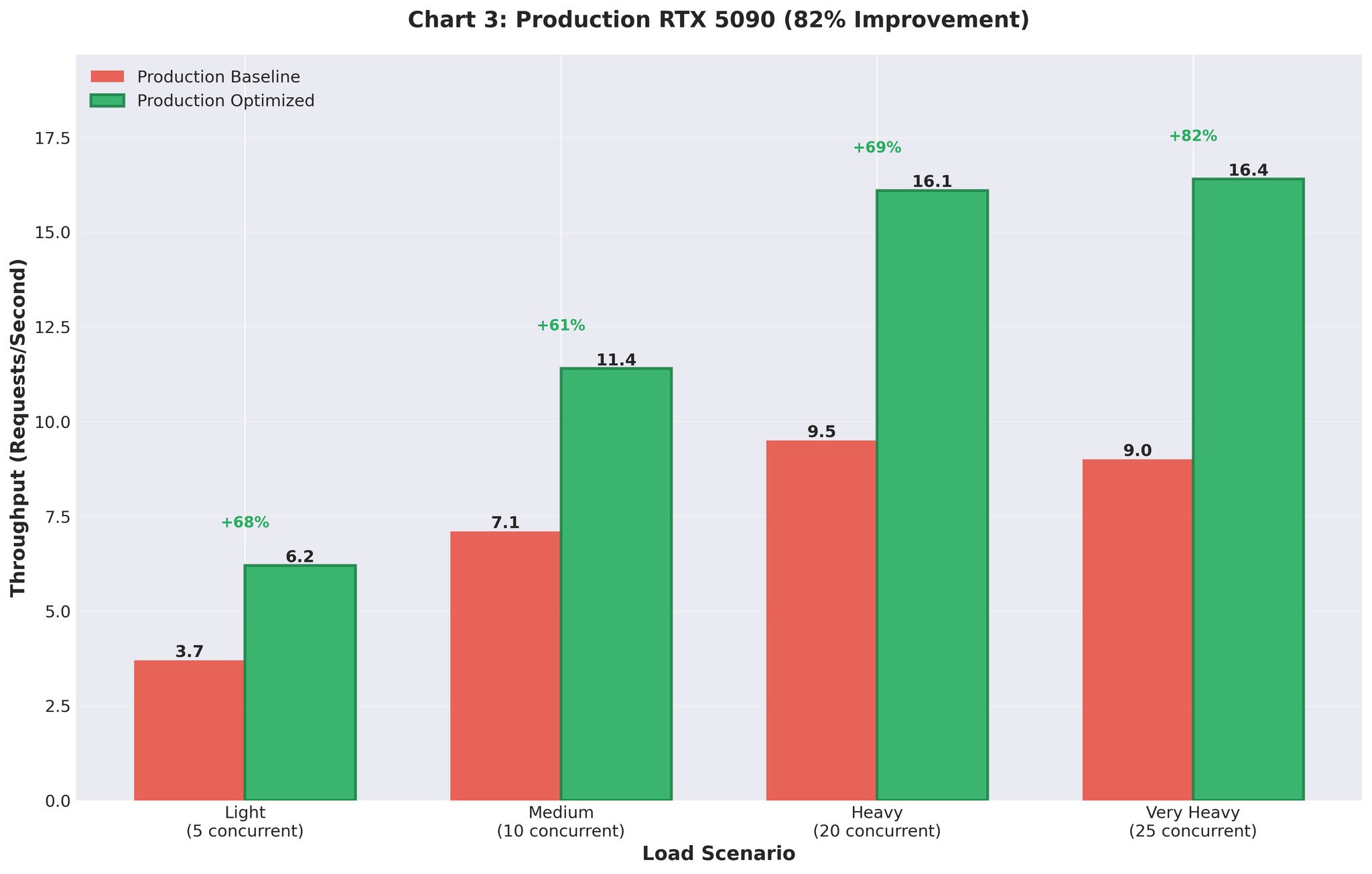
本番環境の結果
最適化した設定をRTX 5090 GPU搭載の本番環境にデプロイしました。
改善前 vs 改善後
| 指標 | 改善前(マルチプロセッシング) | 改善後(最適化AsyncLLM) | 変化 |
|---|---|---|---|
| スループット | 9.0 RPS | 16.4 RPS | +82% |
| GPU使用率 | スパイク状(93% → 0% → 93%) | 安定した90〜95% | 安定化 |
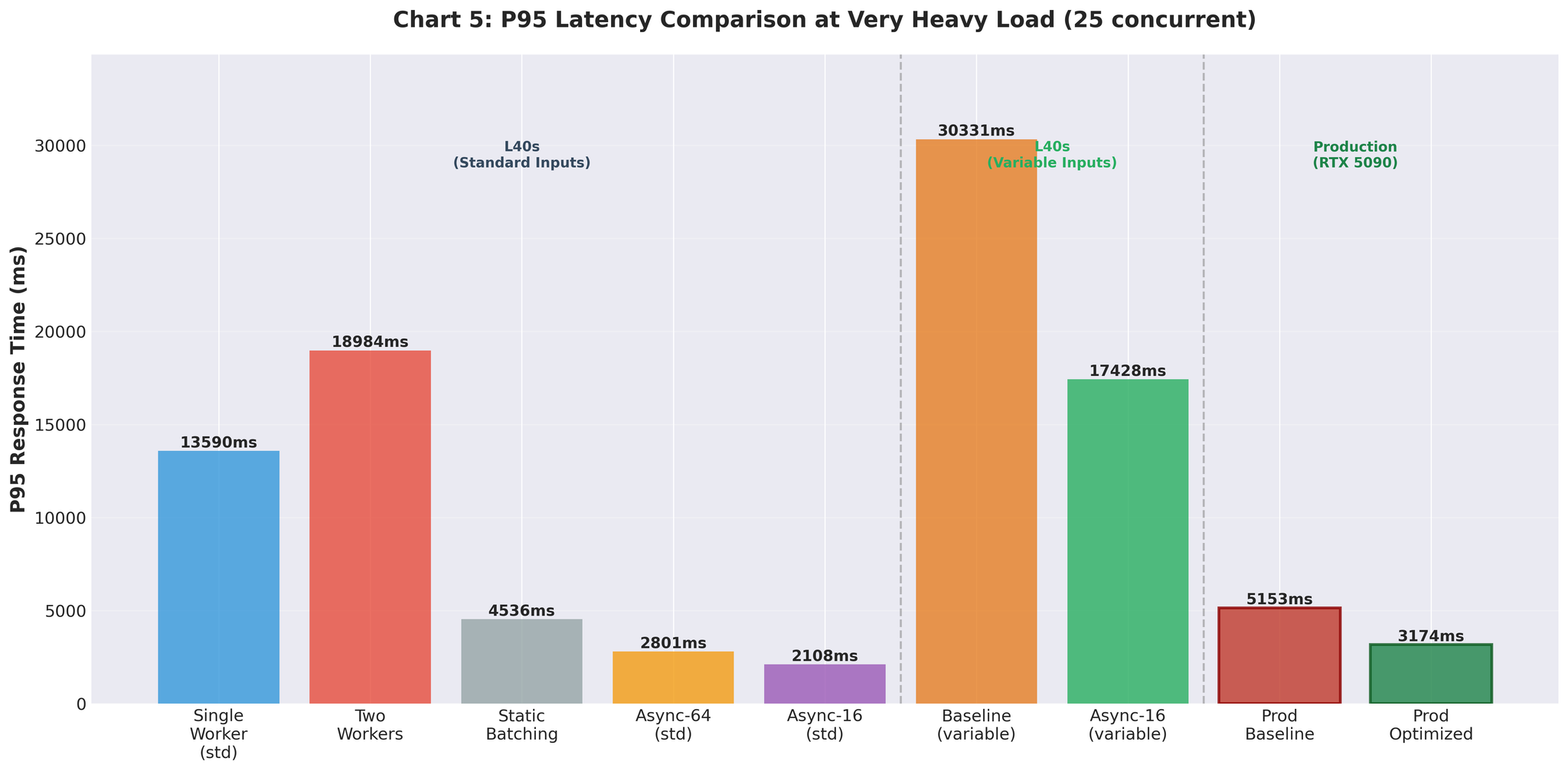
本番環境でも改善効果が維持されました。 実際のトラフィック下で9 RPSから16.4 RPSへ。
まとめ
効果があった施策
vLLMのContinuous Batching
- AsyncLLMEngineがバッチ処理を自動管理
- 手動のバッチ収集オーバーヘッドなし
- FastAPIとの直接async/await統合
適切な設定の選定
- max_num_seqs=16(サーバーあたりの実ワークロードに適合)
- 64(オーバーヘッドを生む理論的最大値)ではなく
- gpu_memory_utilization=0.3で10GBを確保
現実のデータでのテスト
- 可変長入力が設定の問題を露呈
- 均一テストデータでは誤解を招く15 RPSという結果
vLLMメトリクスの監視
- KVキャッシュ使用率
- トークンあたりのデコード時間
- キュー深度
- 設定の判断材料に活用
改善の全過程
| アプローチ | スループット | ベースライン比 | 備考 |
|---|---|---|---|
| ベースライン(マルチプロセッシング) | 2.2 RPS | - | IPCオーバーヘッド、GPU競合 |
| 2ワーカー | 2.0 RPS | -9% | 悪化 |
| スタティックバッチ | 5.9 RPS | +168% | Head-of-Lineブロッキング |
| Async(64, 均一) | 15.0 RPS | +582% | 誤解を招くテストデータ |
| Async(16, 可変) | 3.5 RPS | +59% | 現実的だがチューニングが必要 |
| 最終最適化版 | 10.7 RPS | +386% | ステージング検証 |
| 本番環境 | 16.4 RPS | +82% | 実トラフィック、RTX 5090 |