FastAPI + マルチプロセッシング構成における、GPU効率化を妨げるアーキテクチャ上のボトルネックの特定と分析
課題
私たちはFastAPIとvLLMを使用して翻訳マイクロサービスを運用しています。高負荷時にサーバーのレイテンシが増大しましたが、GPU使用率の指標からは説明がつきませんでした。
GPU使用率は不安定なパターンを示していました。93%まで急上昇した後、0%に低下し、再び急上昇するという繰り返しです。期待していた安定した高使用率とは程遠い状態でした。
疑問:GPUにアイドル期間があるなら、ボトルネックはどこにあるのか?
本記事では、FastAPI + マルチプロセッシング構成において、GPU効率化を妨げていたアーキテクチャ上の問題をどのように特定したかを解説します。
システム構成
翻訳サービスは、ロードバランサーの背後で複数のAPIサーバーとして稼働しています。
- クライアント: Web、モバイル、バックエンドサービス
- プロキシ: 言語ペアとサーバーの稼働状況に基づいてリクエストを振り分け
- APIサーバー: 複数のFastAPIインスタンス、各々がvLLMを実行
本記事では、単一のAPIサーバーの内部アーキテクチャとボトルネックに焦点を当てます。
APIサーバーのアーキテクチャ
1台のAPIサーバーの内部構造を示します。

コンポーネント
1. FastAPIメインプロセス
| |
- async/awaitによるHTTPリクエスト処理
- 単一Pythonプロセス、1つのイベントループ
- ノンブロッキングI/Oによる並行リクエスト処理
2. TranslationService
| |
- 翻訳タスクの作成
- asyncio.Eventを持つEventTaskオブジェクトの管理
- async/awaitとマルチプロセッシングの橋渡し
3. TranslationWorker(メインプロセス)
| |
- メインプロセスでキューを作成(ワーカーと共有)
- タスク配分用のJoinableQueue
- 共有タスク状態のためのmanager().dict()
- 結果返却用のEvent queue
4. ワーカープロセス
| |
- 独立プロセスとしてスポーン(ctx.Process)
- 各ワーカーが独自のvLLMモデルインスタンスをロード
- 共有translation_queueからプル
- 共有event_queue経由で結果を返却
5. EventTask(非同期同期機構)
| |
- マルチプロセッシングとasync/awaitの橋渡し
- 各リクエストにEventTaskを割り当て
await event.wait()でワーカーの完了までコルーチンをブロック
リクエストフロー
1件の翻訳リクエストの処理の流れを示します。

処理の流れ:
- クライアントがPOST /translate → FastAPIが非同期コルーチンを作成
- async translate() → TranslationServiceがリクエストを処理
- create_task() → IDを生成し、共有辞書にTranslationTaskを作成
- queue.put(key) → タスクキーをシリアライズしてワーカーに送信(IPCオーバーヘッド)
- ワーカー: vllm.translate() → ワーカーが翻訳を処理
- event_queue.put(result) → 結果をシリアライズして返送(IPCオーバーヘッド)
- event.set() → EventTaskを更新し、コルーチンを起動
- await event.wait()のブロック解除 → 結果を取得
- レスポンスを返却 → クライアントに送信
オーバーヘッドポイント:
- ステップ4:シリアライゼーション(タスクキーのpickle)
- ステップ6:シリアライゼーション(結果のpickle)
- ステップ8:マルチプロセッシング結果の非同期待機
- 全体にわたるIPCコーディネーション
ベースラインの性能
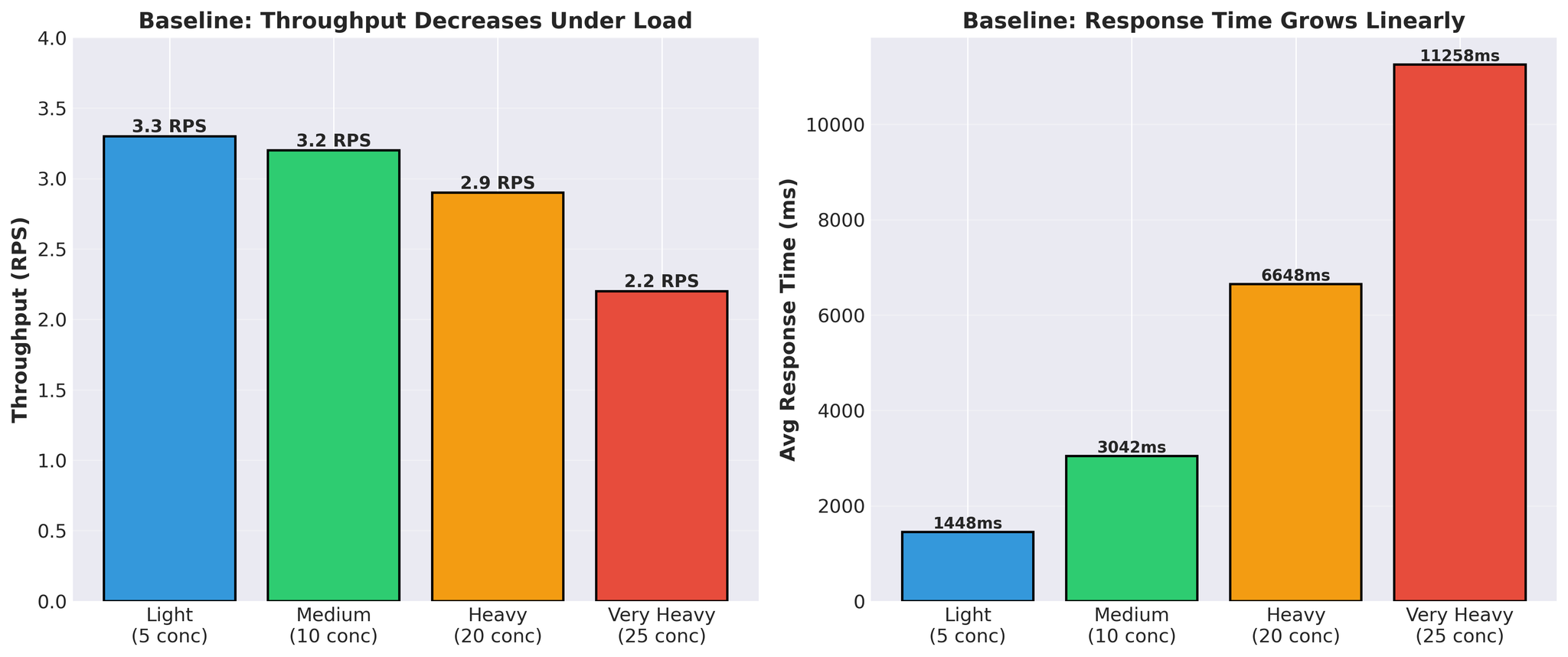
最適化前の状態:
パターン:
- レスポンスタイムが線形に増加(1.4秒 → 11.3秒)
- 負荷下でスループットが低下(3.3 → 2.2 RPS)
- 実際のvLLM翻訳時間:リクエストあたり300〜450ms
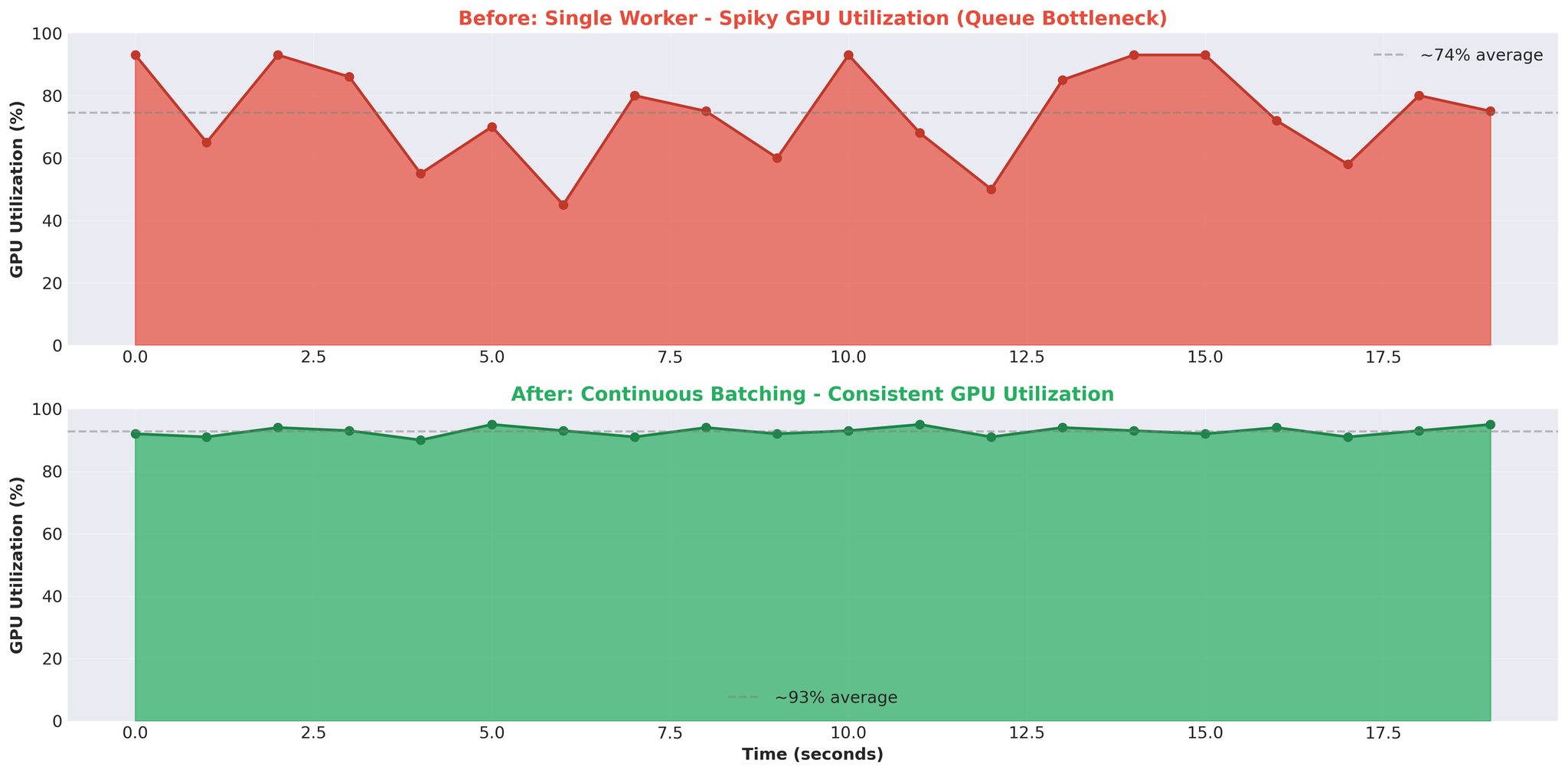
スパイク状パターン: GPUがビジーとアイドルを交互に繰り返す。これはGPUが処理を待っている状態であり、計算能力がボトルネックではないことを示しています。
試行1:複数ワーカー
最初の仮説:ワーカーを増やせば並列化が向上する。
ワーカー数を1から2に増やしました。
設定
| |
- ワーカー1:モデルA+B
- ワーカー2:モデルC
- 両方が同一GPUを共有
結果
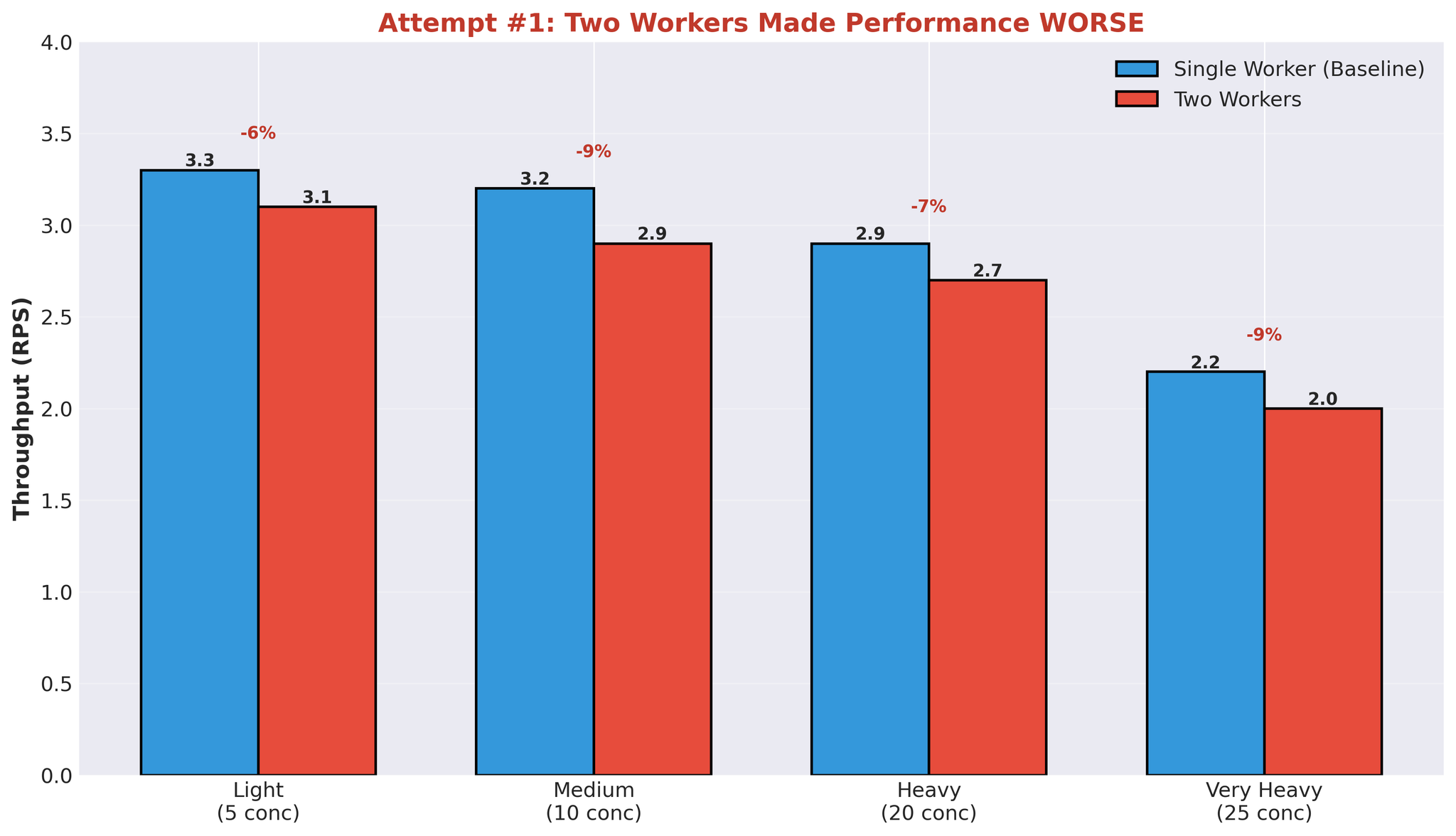
翻訳時間の中央値も悪化:452ms → 2,239ms。
すべての負荷レベルで性能が低下しました。
複数ワーカーが失敗した理由
GPUの動作と私たちのアーキテクチャを理解すれば、この結果は納得できます。

問題:計算リソースの競合
1つのワーカーが翻訳を処理しているとき:
- GPU計算能力の約90%を使用
- 他のワーカーは残りの容量を効果的に並列利用できない
- ワーカーはGPUの空きを待つことになる
並列化の効果がない理由:
- ワーカー1がvLLM生成を開始 → GPU計算能力の約90%を使用
- ワーカー2が開始しようとする → GPU計算能力は約10%しか利用可能でない
- ワーカー2は低速で実行されるか、待機状態になる
- 別プロセスにもかかわらず、実質的にシーケンシャル実行
追加のオーバーヘッド:
- プロセスのスポーンと管理
- ワーカー間でのGPUメモリ分割(各々がモデルウェイトをロード)
- IPCキューのコーディネーション
- プロセス間のコンテキストスイッチ
GPUは技術的には複数のCUDAカーネルを同時に実行できますが、1つのワーカーが計算能力の約90%を使用している状態では、もう1つのワーカーが効率的に並列実行できるだけの残容量がありません。
その他のアーキテクチャ上の問題
複数ワーカーが同一リソースを奪い合うことで:
- コンテキストスイッチのオーバーヘッド: OSがワーカープロセス間を切り替え
- メモリ使用量の倍増: 各ワーカーがモデルウェイトの全体をロード
- 実効的な並列性なし: 並列アーキテクチャにもかかわらずシーケンシャルなGPU実行
すべてのワーカーが同じキュー(translation_queueとevent_queue共有)を使用するため、リクエストあたりのIPCオーバーヘッドは一定です。しかし、プロセス管理、コンテキストスイッチ、メモリ重複による追加オーバーヘッドと、GPU並列化の恩恵がないことが相まって、性能が悪化しました。
特定されたボトルネック
この実験を通じて、根本的な問題を特定しました。
1. IPCシリアライゼーションのオーバーヘッド
- 全リクエストで:タスクのシリアライズ → ワーカー、結果のシリアライズ → メイン
- Pythonのマルチプロセッシングキューはpickleを使用
- リクエストごとにオーバーヘッドが発生
2. 計算リソースの競合
- 1つのワーカーがGPU計算能力の約90%を使用
- 他のワーカーは効果的に並列実行できない
- マルチプロセッシングにもかかわらずシーケンシャル実行
3. Async/Await + マルチプロセッシングのブリッジ
- asyncio.Eventがマルチプロセッシングの結果を待機
- スレッドベースのイベントキューコンシューマ
- 非同期モデルとマルチプロセスモデル間のコーディネーションオーバーヘッド
4. GPUサイクルの浪費
- キュー操作の待機中にGPUがアイドル
- スパイク状の使用率(93% → 0% → 93%)
- 翻訳時間は約400msなのに、合計レスポンスタイムは11秒以上
- 大半の時間がキューに費やされ、計算には使われていない
5. アーキテクチャの複雑さ
- FastAPI(async/await)
- TranslationService(ブリッジ)
- TranslationWorker(コーディネーション)
- JoinableQueue(IPC)
- ワーカープロセス(マルチプロセッシング)
- Event queue(IPC)
- EventTask(非同期同期)
- vLLM(実際の処理)
各レイヤーがレイテンシを追加していました。
重要な知見
1. Async/Await + マルチプロセッシング = オーバーヘッド
この2つの並行モデルを橋渡しするにはコーディネーションが必要です:
- 非同期待機のためのasyncio.Event
- イベントキュー消費のためのスレッドプール
- プロセス境界でのシリアライゼーション
このブリッジにはコストがかかります。
2. 複数プロセス ≠ GPU並列化
ワーカープロセスの追加がGPU使用率の向上に直結しないケース:
- 1つのワーカーがGPU計算能力の約90%を使用
- 並列処理に十分な残容量がない
- マルチプロセッシングのオーバーヘッドがあるのにシーケンシャル実行
3. キューのオーバーヘッドが支配的
25の同時リクエスト時:
- vLLM翻訳時間:約400ms
- 合計レスポンスタイム:11,258ms
- キューのオーバーヘッド:合計時間の約97%
大半の時間が計算ではなく、キューとコーディネーションに費やされていました。
4. スパイク状のGPU使用率 = アーキテクチャの問題
- 安定したGPU使用率(例:90〜95%)は計算律速のワークロードを示す
- スパイク状のパターン(93% → 0% → 93%)はGPUが処理を待っていることを示す。ボトルネックは別の場所にある(私たちの場合はキューとIPC)
まとめ
ボトルネックはGPUの処理能力ではありませんでした。マルチプロセッシングアーキテクチャそのものが原因でした。
特定された問題:
- キューのシリアライゼーションによるIPCオーバーヘッド
- 実効的な並列性のないGPU計算リソースの競合
- Async/await + マルチプロセッシングのコーディネーションオーバーヘッド
- vLLMの処理ではなくキュー待ちがレイテンシの大半を占める
症状:
- スパイク状のGPU使用率
- キュー待ちがレスポンスタイムの大部分を占める
- ワーカーの追加で性能がさらに悪化
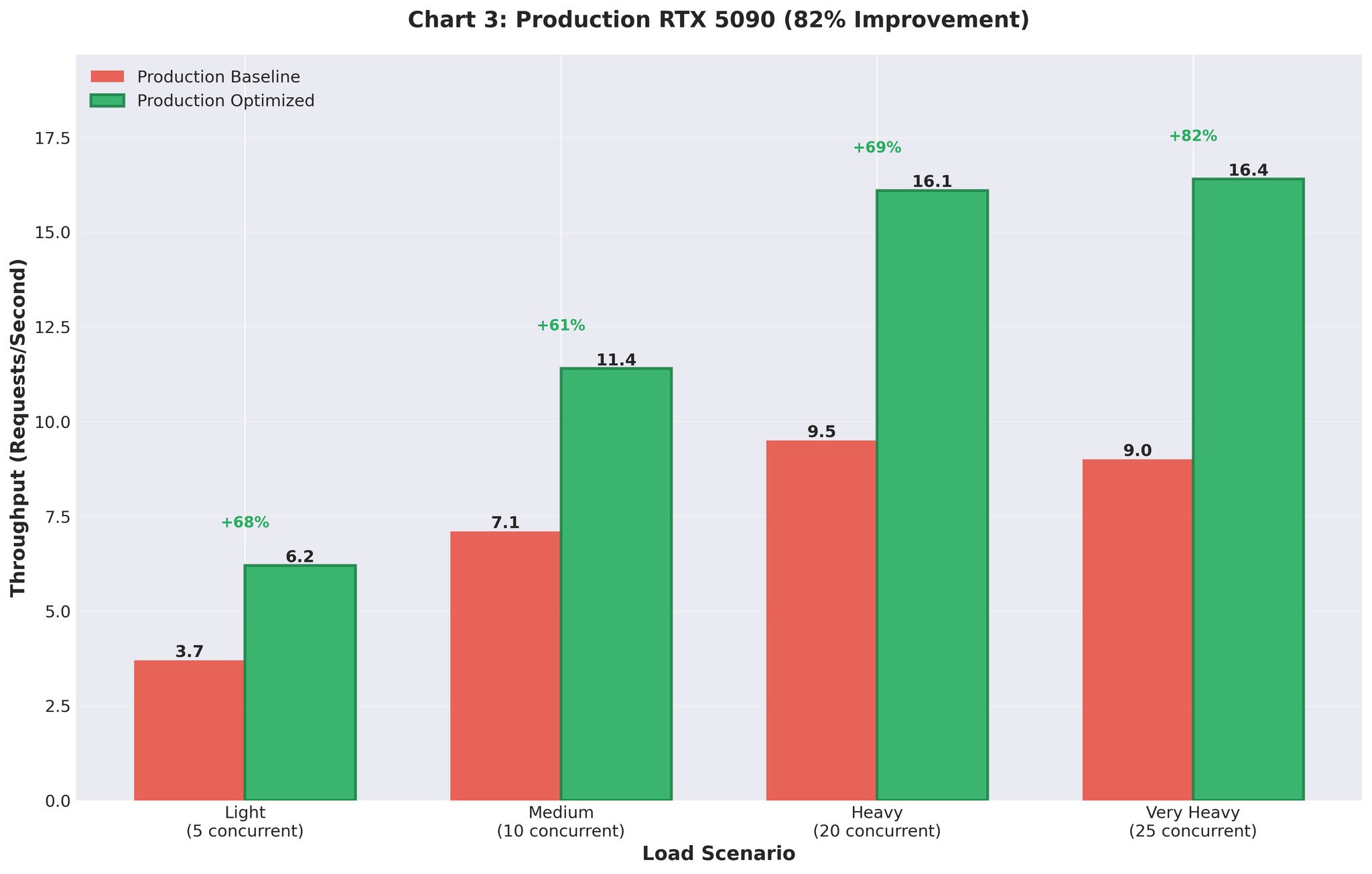
注: Part 2では、マルチプロセッシングを排除し、vLLMのAsyncLLMEngineを直接使用することで、本番環境でスループット82%向上を達成した解決策を紹介します。
次回の内容:
- マルチプロセッシングアーキテクチャの全面撤廃
- vLLMのAsyncLLMEngineをFastAPIと直接統合
- Continuous Batchingの適正な設定
- 本番環境での成果:スループット82%向上
続きはこちら: Part 2:翻訳推論のスケーリング:スループット+82%