話者ダイアライゼーションフレームワークの比較評価。DER分析とリアルタイムアプリケーション開発を通じて、Pyannote.audioとNvidia NeMoの性能差を検証します。
概要
本論文では、最先端のオープンソース話者ダイアライゼーションフレームワークであるPyannote.audioとNvidia NeMoの2つを評価・比較します。異なる音声シナリオにおけるDiarization Error Rate(DER)、実行時間、GPU使用率を中心に評価を行います。さらに、ダイアライゼーション精度を向上させるため、OpenAIのGPT-4-Turboを用いた後処理アプローチについても検討します。
主な結果:
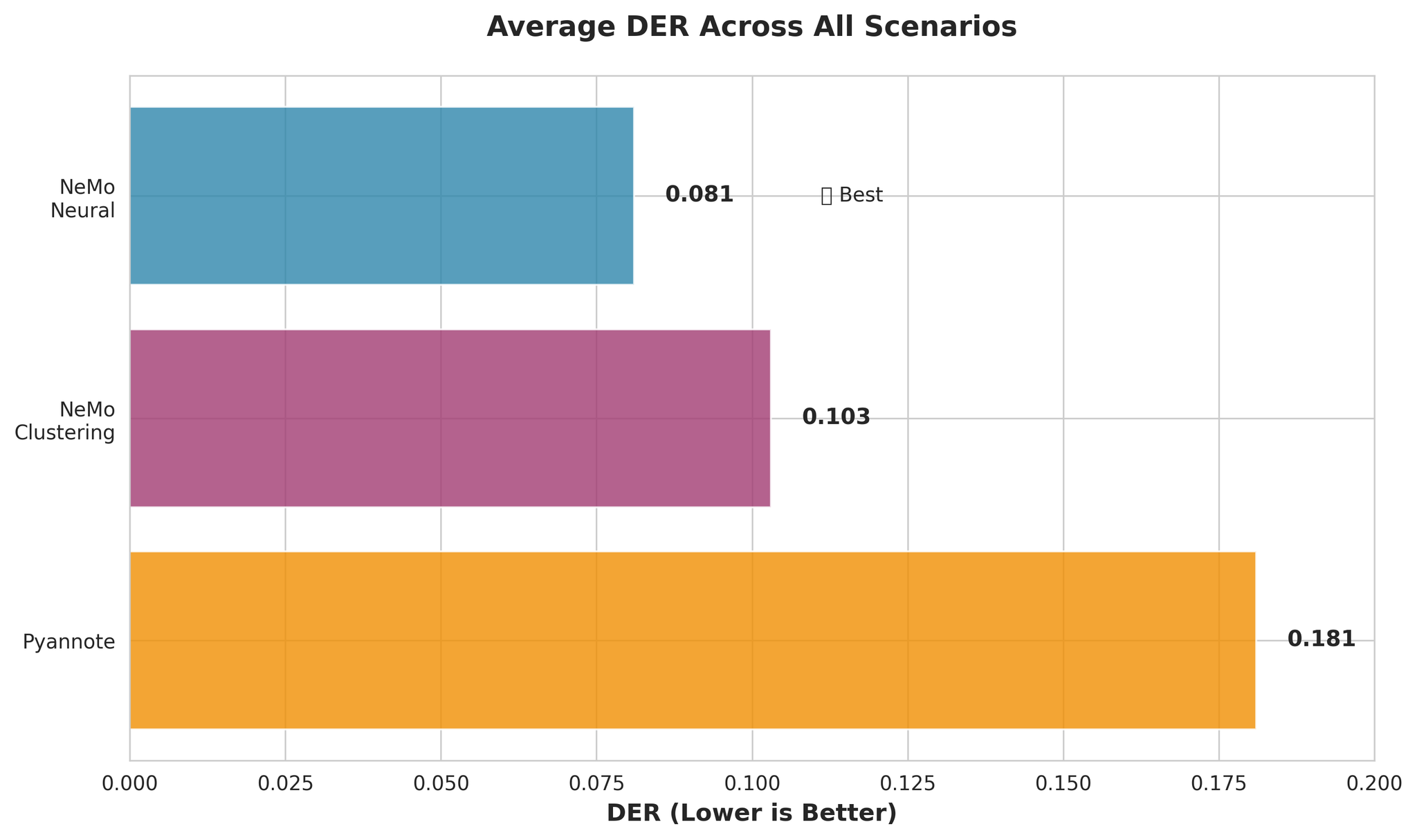
- Nvidia NeMoは2話者シナリオでDERが約9%低い
- Pyannote.audioは多話者(9人以上)シナリオで優れた性能を発揮
- GPT-4-Turboによる後処理は可能性を示すが、音声コンテキストの統合が必要
- リアルタイム話者ダイアライゼーションWebアプリケーションのデモを実施
1. はじめに
話者ダイアライゼーションとは
話者ダイアライゼーションとは、音声をさまざまな話者に基づいてセグメント化し、ラベル付けするプロセスです。つまり、与えられた音声に対して「誰がいつ話したか」という問いに答える技術です。自動音声認識(ASR)と組み合わせることで、会話分析における重要なツールとなります。
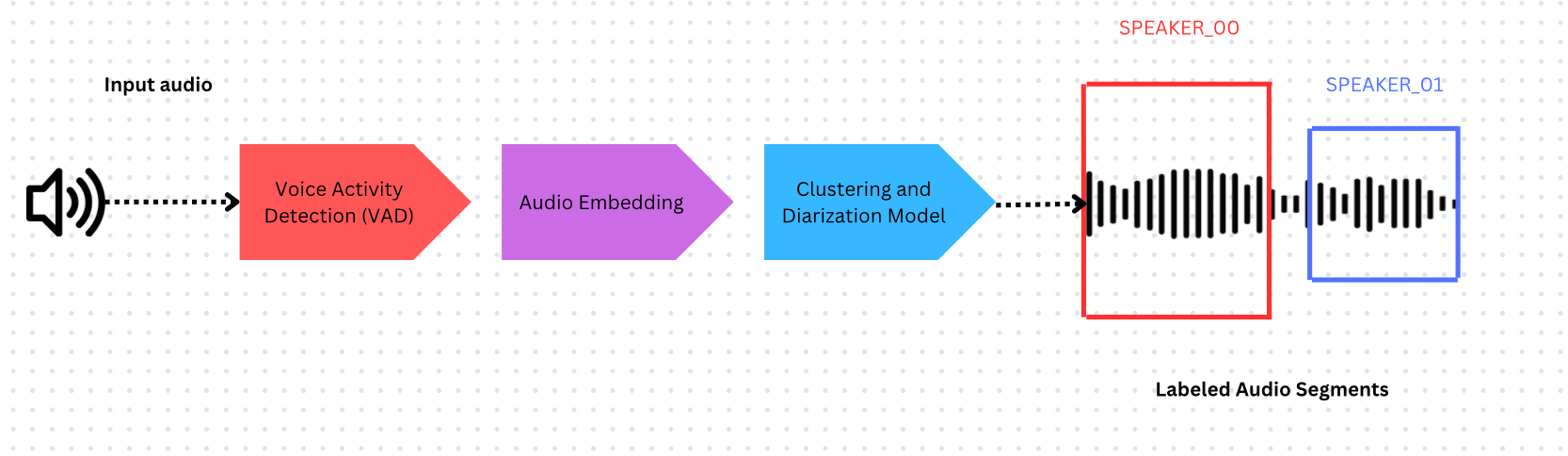
話者ダイアライゼーションシステムは以下の要素で構成されます:
- 音声活動検出(VAD) - 発話が発生しているタイムスタンプの特定
- 音声埋め込みモデル - タイムスタンプ付きセグメントからの埋め込み抽出
- クラスタリング - 埋め込みをグループ化して話者数を推定
Pyannote.audio
Pyannote.audioは、PyTorchベースの話者ダイアライゼーションおよび話者埋め込みのためのオープンソースPythonツールキットです。
Nvidia NeMo
Nvidia NeMoは、マルチスケールセグメンテーションとNeural Diarizer(MSDDモデル)を活用した異なるアプローチを採用し、話者の重複発話に対応します。
マルチスケールセグメンテーション
NeMoは、話者識別品質と時間的粒度のトレードオフに対処します:
- 長いセグメント → 話者表現の品質が高いが、時間解像度が低い
- 短いセグメント → 話者表現の品質が低いが、時間解像度が高い
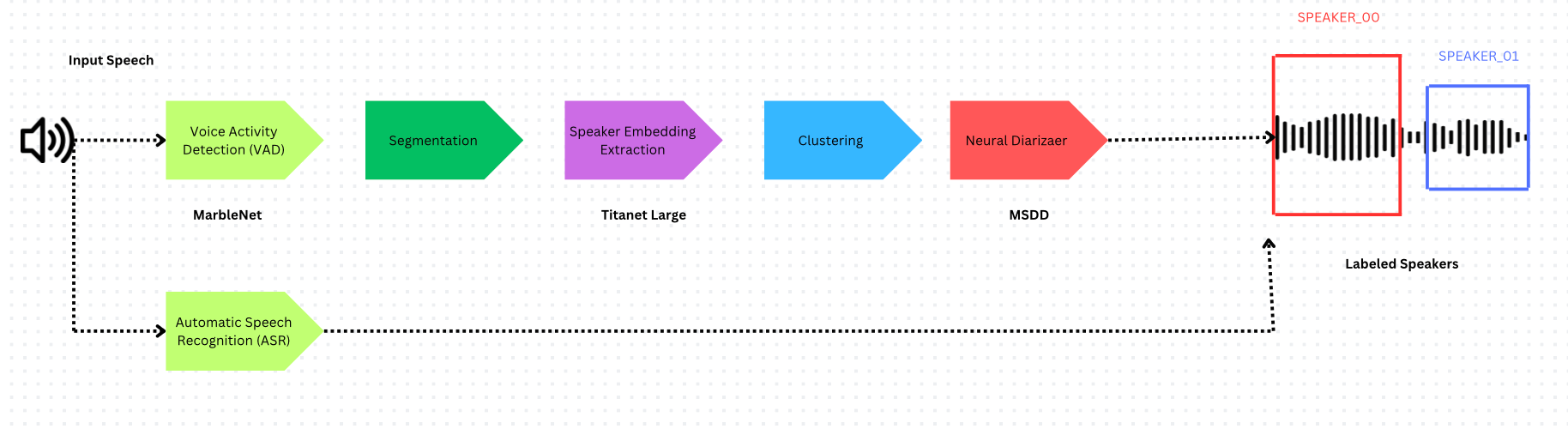
フレームワークの比較
| コンポーネント | Pyannote.audio | Nvidia NeMo |
|---|---|---|
| VAD | Pyannote from SyncNet | Multilingual MarbleNet |
| 話者埋め込み | ECAPA-TDNN | Titanet Large |
| クラスタリング | Hidden Markov Model | Multi-scale Clustering (MSDD) |
2. 評価方法
Diarization Error Rate(DER)
話者ダイアライゼーションの標準評価指標で、NISTにより2000年に導入されました:
DER = (False Alarm + Missed Detection + Confusion) / Total
各要素の意味:
- False Alarm: 話者がいないのに発話が検出された
- Missed Detection: 話者がいるのに発話が検出されなかった
- Confusion: 発話が誤った話者に割り当てられた
注: DERは0に近いほどエラーが少ないことを示します。
RTTMファイルフォーマット
Rich Transcription Time Marked(RTTM)は、話者ダイアライゼーション出力の標準フォーマットです:
SPEAKER obama_zach(5min).wav 1 66.32 0.27 <NA> <NA> SPEAKER_01 <NA> <NA>
主要フィールド:セグメント開始時刻(66.32)、持続時間(0.27)、話者ラベル(SPEAKER_01)
3. 実験環境
データセット
- 5分間の音声 - 2話者(Obama-Zachインタビュー)、Audacityを用いて手動アノテーション
- 9分間の音声 - VoxConverseデータセットからの9話者、プロによるグラウンドトゥルース付き
ハードウェア
- GPU: Nvidia GeForce RTX 3090
- 時間計測にはPythonの
timeモジュールを使用
Pyannote.audioのコード
| |
Nvidia NeMoのコード
| |
4. 結果と考察
DER結果 - 2話者(5分)
| フレームワーク | DER |
|---|---|
| Pyannote.audio | 0.252 |
| Pyannote.audio(話者事前特定あり) | 0.214 |
| Nvidia NeMo | 0.161 |
| Nvidia NeMo(話者事前特定あり) | 0.161 |
ポイント: Nvidia NeMoは2話者シナリオにおいて、Pyannote.audioより約9%低いDERを達成しています。
DER結果 - 9話者(9分)
| フレームワーク | DER |
|---|---|
| Pyannote.audio | 0.083 |
| Pyannote.audio(話者事前特定あり) | 0.098 |
| Nvidia NeMo(話者事前特定あり) | 0.097 |
多話者シナリオでは、Pyannote.audioがNvidia NeMoより約1.4%低いDERを達成しています。
GPT-4による後処理結果
| フレームワーク | GPT-4-Turbo DER | GPT-3.5 DER |
|---|---|---|
| Pyannote(5分, 2話者) | 0.427 | 0.494 |
| Nemo(5分, 2話者) | 0.179 | 0.544 |
| Pyannote(9分, 9話者) | 0.103 | 0.214 |
| Nemo(9分, 9話者) | 0.128 | 0.179 |
注意: GPT-4による後処理はDERが高くなる傾向があります。これは音声データへの直接アクセスがないためです。話者のタイミング情報や音声コンテキストを提供することで、結果の改善が期待できます。
実行時間の比較
| フレームワーク | 5分音声 | 9分音声 |
|---|---|---|
| Pyannote.audio | 31.3秒 | 44.5秒 |
| Pyannote(話者事前特定あり) | 29.8秒 | 41.5秒 |
| Nvidia NeMo | 63.9秒 | - |
| Nemo(話者事前特定あり) | 49.9秒 | 108.2秒 |
Nvidia NeMoはPyannote.audioと比較して約2倍の実行時間を要します。
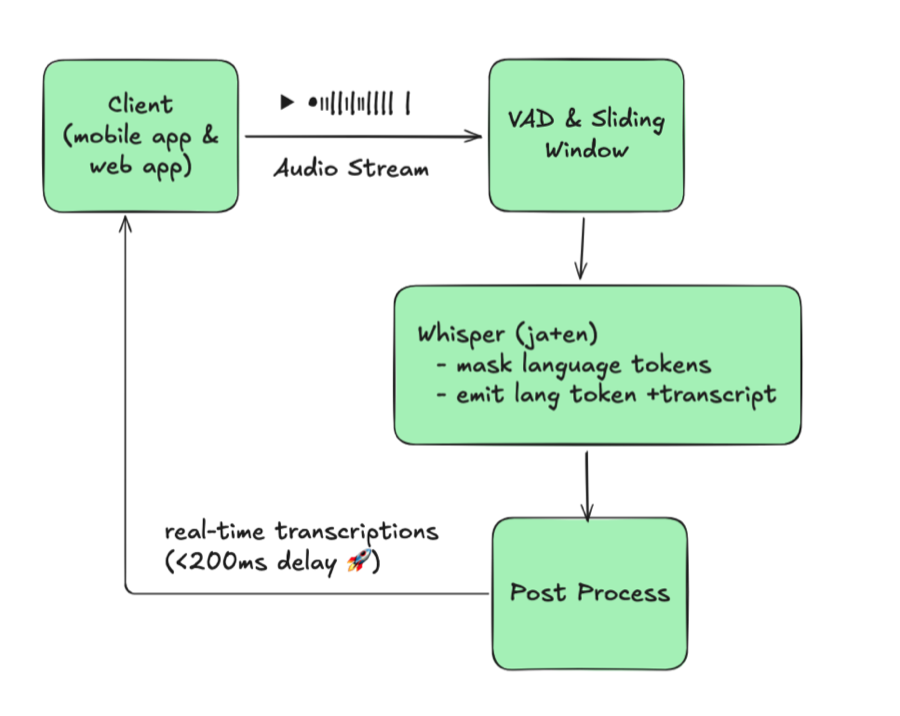
5. リアルタイムアプリケーション
以下の技術を用いて、リアルタイム話者ダイアライゼーションWebアプリケーションを開発しました:
- WebSockets による音声ストリーミング
- FastAPI によるバックエンド
- Pyannote.audio によるダイアライゼーション
実装のポイント
リアルタイム性能の向上のため、30秒チャンクの代わりに3秒チャンクの音声を使用しています:
| |
結果の比較


変更後のチャンクロジックにより、タイミングエラーが大幅に減少し、話者の切り替えがスムーズになりました。
6. まとめ
主な知見
- Nvidia NeMo は短い音声で話者数が少ない場合に優れている(DER: 0.161 vs 0.252)
- Pyannote.audio は話者数が多い場合や、話者数の事前特定がある場合に優れた性能を発揮
- GPT-4による後処理 は可能性を示すが、音声コンテキストの統合が必要
- 実行時間: Pyannote.audioは約2倍高速
- リアルタイムアプリケーション: チャンクロジックの改良により精度が向上
今後の課題
- Nvidia NeMoモデルを非電話シナリオ向けに調整
- GPT後処理への音声コンテキストの統合
- リアルタイムアプリケーション向けの話者識別閾値の最適化
- ダイアライゼーションタスクに特化したドメイン固有LLMの探索
7. 参考文献
- NIST Rich Transcription Evaluation (2022)
- Nvidia NeMo Documentation - Speaker Diarization
- Pyannote.audio GitHub Repository
- OpenAI GPT-4 Turbo Documentation
- VoxConverse Speaker Diarization Dataset
謝辞
- 中島明紀 - VoicePing株式会社 代表取締役
- Melnikov Ivan - VoicePing株式会社 AI開発者