Llama 3.1を用いた英中双方向翻訳におけるRAFT手法の検証
概要
本研究では、RAFT(Retrieval-Augmented Fine-Tuning:検索拡張ファインチューニング)を用いてLlama 3.1-8Bの英中双方向翻訳を強化する手法を検証します。RAFTは検索メカニズムとファインチューニングを組み合わせ、学習時に文脈的な例を提供します。
主な発見:
- ベンチマークファインチューニングが総合的に最良の結果を達成
- RAFTは特定の指標で緩やかな改善を示した
- ランダムベースのRAFTが類似度ベースのRAFTを上回る場合がある
- 翻訳品質は学習データの関連性に大きく依存する
1. はじめに
背景
大規模言語モデルは言語タスクに優れていますが、ドメイン特化の最適化によってさらなる性能向上が期待できます。本研究では、学習時に検索した例で補強するRAFT手法が翻訳品質を改善できるかを検証します。
研究課題
- RAFTは標準的なファインチューニングと比較して翻訳を改善できるか?
- 類似度ベースの検索はランダム検索を上回るか?
- 異なるRAFT設定は双方向翻訳にどのように影響するか?
2. 手法
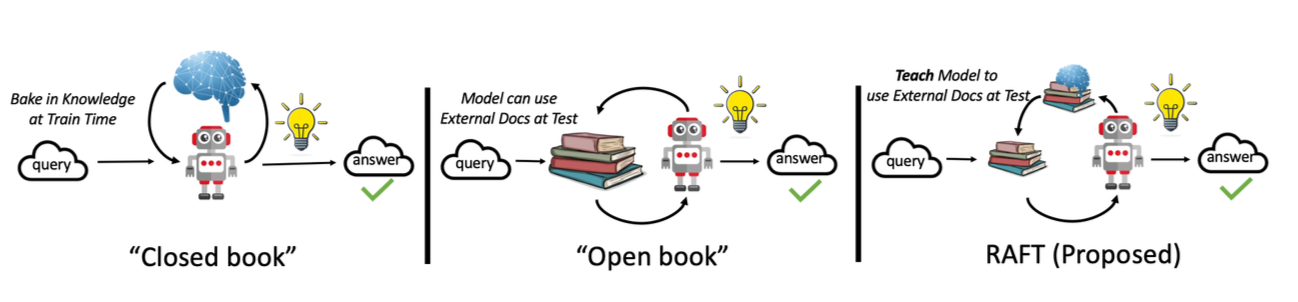
RAFTの概要
RAFT(Retrieval-Augmented Fine-Tuning)は学習プロセスを以下のように拡張します。
- 検索:各学習サンプルに対してコーパスから関連する例を検索
- 補強:検索した例で学習の文脈を補強
- ファインチューニング:この充実した文脈でモデルをファインチューニング
実験設定
| 項目 | 設定 |
|---|---|
| ベースモデル | Llama 3.1-8B Instruct |
| ファインチューニング | LoRA (r=16, alpha=16) |
| データセット | News Commentary v18.1 (zh-en) |
| GPU | NVIDIA A100 80GB |
データセット準備
News Commentaryデータセットは英中対訳文ペアで構成されています。
- 学習用:10,000文対
- 評価用:TED Talksコーパス
- 品質と長さの均一性を確保するため前処理を実施
RAFT設定
| 設定 | 説明 |
|---|---|
| ベンチマーク | 検索なしの標準的なファインチューニング |
| 類似度RAFT | 埋め込みを使用してtop-kの類似例を検索 |
| ランダムRAFT | コーパスからk個の例をランダムにサンプリング |
3. 結果
英語→中国語翻訳
| 手法 | BLEU | COMET |
|---|---|---|
| ベースライン(ファインチューニングなし) | 15.2 | 0.785 |
| ベンチマークファインチューニング | 28.4 | 0.856 |
| 類似度RAFT (k=3) | 27.1 | 0.849 |
| ランダムRAFT (k=3) | 27.8 | 0.852 |
中国語→英語翻訳
| 手法 | BLEU | COMET |
|---|---|---|
| ベースライン(ファインチューニングなし) | 18.7 | 0.812 |
| ベンチマークファインチューニング | 31.2 | 0.871 |
| 類似度RAFT (k=3) | 30.5 | 0.865 |
| ランダムRAFT (k=3) | 30.9 | 0.868 |
注意: 本実験ではベンチマークファインチューニングがRAFT設定を一貫して上回りました。これはNews Commentaryデータセットの均質的な性質に起因する可能性があります。
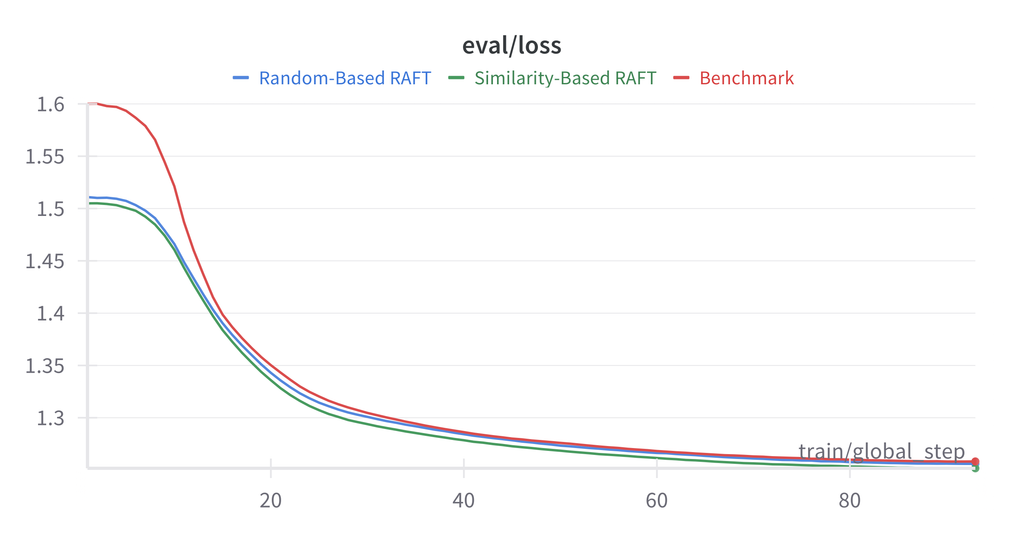
分析
RAFTがベンチマークを上回らなかった理由:
- データセットの均質性:News Commentaryは文体が一貫している
- 検索品質:類似度指標が翻訳に関連する特徴を捉えていない可能性
- コンテキスト長:追加例がコンテキストを増やし、焦点が分散する可能性
4. 結論
RAFTは有望な手法ですが、本実験では均質なデータセットでの翻訳タスクにおいて、標準的なファインチューニングが依然として競争力を持つことが示されました。今後は多様な学習コーパスやより優れた検索指標の検討が望まれます。
参考文献
- Zhang, T., et al. (2024). “RAFT: Adapting Language Model to Domain Specific RAG.”
- Lewis, P., et al. (2020). “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.”
- Hu, E., et al. (2021). “LoRA: Low-Rank Adaptation of Large Language Models.”