Llama 3.1を用いた中英翻訳のファインチューニングとハルシネーション軽減戦略に関する研究
概要
大規模言語モデル(LLM)は自然言語タスクにおいて優れた性能を示しています。本研究では、Llama 3.1を中国語から英語への機械翻訳用にファインチューニングし、学習およびデコーディング戦略を通じてハルシネーションの課題に取り組みます。
主な結果:
- ファインチューニングモデルが文書レベルデータで BLEU 40.8(ベースライン 19.6)を達成
- COMET 0.891(ベースライン 0.820)
- 長文コンテキスト翻訳におけるハルシネーションの軽減に成功
- 文書レベルの性能を向上させつつ、文レベルの品質を維持
1. 背景
大規模言語モデル
Llamaに代表されるLLMは自然言語処理を革新し、人間のようなテキストの理解・生成において顕著な能力を示しています。特定タスクへのファインチューニングが可能なため、機械翻訳の高度化に最適です。
パラメータ効率的ファインチューニング(LoRA)
LoRA(Low-Rank Adaptation)は、モデル全体のパラメータを更新せずにファインチューニングを実現する手法です。
- 事前学習済みモデルのパラメータを固定
- 学習可能な低ランク行列を挿入
- 学習コストと時間を大幅に削減
ニューラル機械翻訳とハルシネーション
NMTにおけるハルシネーションとは、忠実でない、捏造された、または意味をなさない内容を指します。
| 種類 | 説明 |
|---|---|
| 内在的ハルシネーション | 原文と比較して誤った情報を含む出力 |
| 外在的ハルシネーション | モデルが無関係な追加コンテンツを生成 |
| 摂動ハルシネーション | 入力の微小な変化に対して大幅に異なる出力を生成 |
| 自然ハルシネーション | 学習データセットのノイズに起因 |
デコーディング戦略
| 手法 | 説明 |
|---|---|
| 貪欲法 | 各ステップで最も確率の高いトークンを選択 |
| ビームサーチ | 最も確率の高いN個のシーケンスを考慮 |
| 温度サンプリング | 確率分布の鋭さを調整 |
| Top-pサンプリング | 累積確率の閾値を超えるトークンから選択 |
| Top-kサンプリング | 最も確率の高いk個のトークンから選択 |
2. 実験
データセット
| データセット | 文書数 | 文数 | 単語数(原文/訳文) |
|---|---|---|---|
| NewsCommentary-v18.1 | 11,147 | 443,677 | 1,640万/970万 |
| Ted Talks | 22 | 1,949 | 5.1万/3.2万 |
評価指標
- BLEU:Bilingual Evaluation Understudy - 参照訳とのn-gram一致を比較
- COMET:人間の判定との相関が最高水準のニューラル評価フレームワーク
実験環境
- モデル:Llama 3.1 8B Instruct
- GPU:NVIDIA A100(80GB)
- フレームワーク:Unslothによる高速学習
ファインチューニング設定
| |
3. 結果
分布内性能(文書レベル)
| 学習サンプル数 | BLEU | COMET |
|---|---|---|
| 10 | 35.8 | 0.885 |
| 100 | 36.9 | 0.889 |
| 1,000 | 39.7 | 0.890 |
| 10,000 | 40.8 | 0.891 |
| ベースライン | 19.6 | 0.820 |
ポイント: ファインチューニングにより、文書レベルの翻訳でベースラインと比較してBLEUが100%以上向上しました。
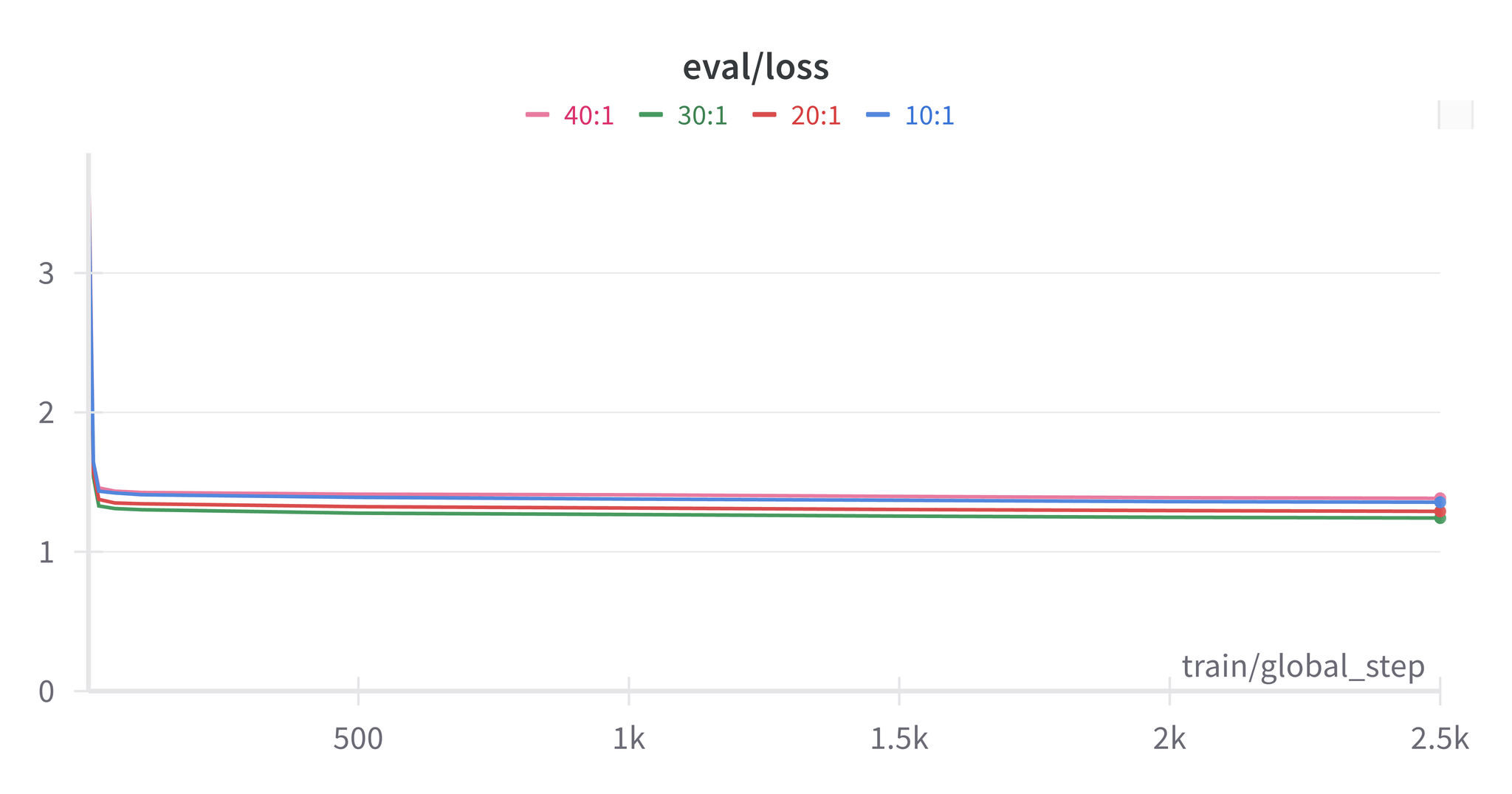
混合学習の最終結果
文対文書の比率30:1を使用:
| 評価レベル | ファインチューニング BLEU | ファインチューニング COMET | ベースライン BLEU | ベースライン COMET |
|---|---|---|---|---|
| 文書レベル | 37.7 | 0.890 | 19.6 | 0.820 |
| 文レベル | 30.7 | 0.862 | 30.9 | 0.864 |
ハルシネーション分析
確認された種類:
- 早期停止:翻訳完了前にモデルがEOSトークンを生成
- 冗長コンテンツ:文書レベルモデルが翻訳以外の長い説明を生成
軽減戦略:
- EOSトークン確率の閾値設定
- 文書レベルと文レベルの混合学習
- データセットの入念な準備
注意: 文書レベルでファインチューニングされたモデルは、暗黙的な事前知識を含む冗長な出力を生成する傾向があり、正確だがトピック外のコンテンツを生成することがあります。
4. 結論
適切なデータセット準備とファインチューニング技法により、以下が可能であることが示されました。
- 翻訳品質の大幅な向上(BLEUが2倍に改善)
- ハルシネーション問題の軽減
- 文書レベルの性能向上と文レベルの品質維持の両立
- より信頼性が高く一貫性のある翻訳の生成
5. 今後の課題
- 多様な入力シナリオ(文体、文化的背景、対話テーマ)をカバーするデータセットの準備
- バイアスを回避するための学習データにおけるコンテンツタイプのバランス調整
- 後処理手法による固有名詞エラーへの対処
- 追加のハルシネーション軽減技法の探索
参考文献
- Kocmi, T., et al. (2022). “Findings of the 2022 conference on machine translation (WMT22).”
- Hu, E., et al. (2021). “LoRA: Low-Rank Adaptation of Large Language Models.”
- Meta AI. (2024). “Llama 3.1 Model Documentation.”
- Ji, Z., et al. (2023). “Survey of Hallucination in Natural Language Generation.”