TF-IDFによる検索を活用してGPT-4翻訳のIn-Context Learningの性能を向上させる手法に関する研究レポートです。
1. はじめに
大規模言語モデル(LLM)は、入力とラベルのペアを条件として与えることで、下流タスクにおいて優れた能力を発揮しています。この推論モードはIn-Context Learningと呼ばれています(Brown et al. 2020)。GPT-4はファインチューニングなしで、特定のタスク例を提示するだけで翻訳能力を向上させることができます。
In-Context Learningの有効性は、暗黙的ベイズ推論に起因します(Xie et al. 2022)。例をランダムに選択するだけでは、GPT-4がプロンプトの概念を効果的に理解することはできません。本研究の主な目的は、ユーザー入力に基づいて適切な例を戦略的に選択することです。
2. 提案手法
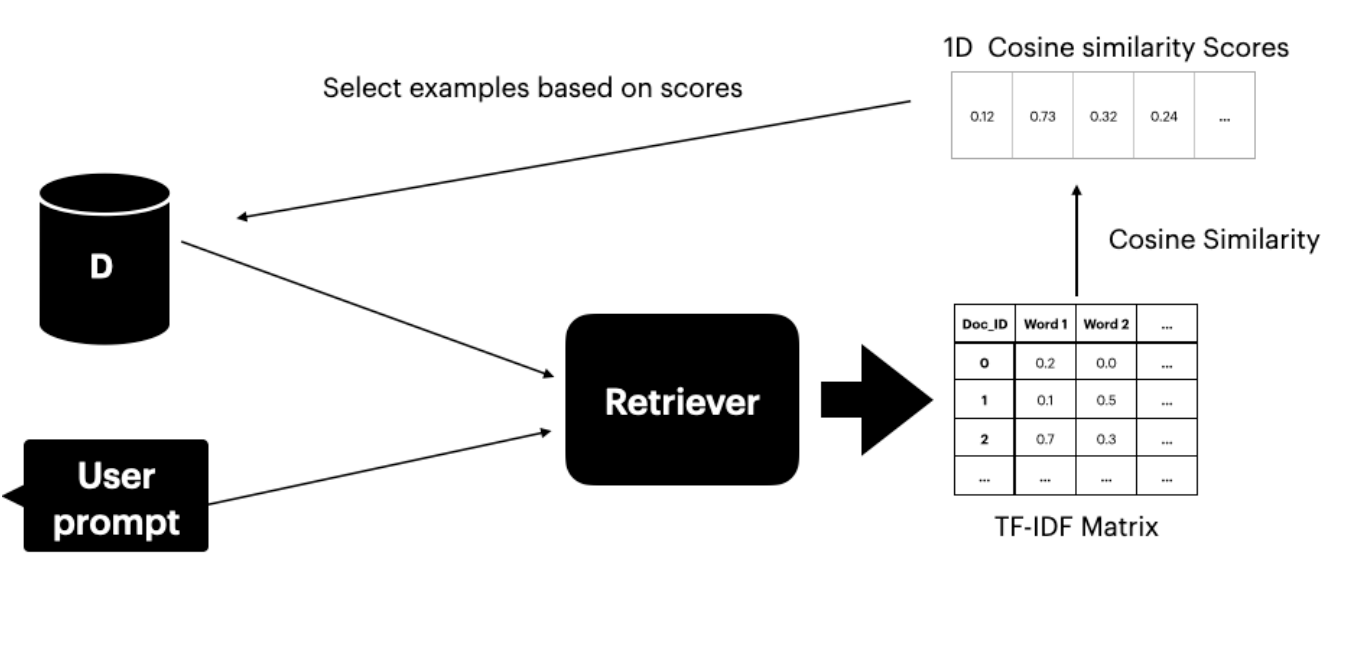
本手法は、翻訳ペアを含むデータセットDsへのアクセスを前提としています。テキストリトリーバー(Gao 2023)を使用して、ユーザーのプロンプトと意味的に類似する上位K文を検索・選択します。
リトリーバーは2つのコンポーネントで構成されています。
- TF-IDF行列 - 単語頻度と逆文書頻度を測定
- コサイン類似度 - TF-IDFベクトル間の類似度を計算
TF-IDFスコア
TF-IDFスコアは、文書内の単語の重要度を測定します。
- TF(単語頻度): 文書内での単語の出現頻度
- IDF(逆文書頻度): コーパス全体における単語の重要性
コサイン類似度
コサイン類似度は、2つのベクトルの表現間の角度を考慮して類似性を評価します。スコアが高いほど、ユーザーのプロンプトとデータセット内の文書の類似度が高いことを示します。
3. 実験設定
3.1 実験手順
実験は3つのシナリオを対象としています。
- ICLなし: In-Context Learning例なしのGPT-4翻訳
- ランダムICL: 翻訳例をランダムに選択
- 提案手法: TF-IDFリトリーバーが類似度スコアに基づいて上位4つの例を選択
評価指標
- BLEUスコア: 翻訳セグメントを参照翻訳と比較(Papineni et al. 2002)
- COMETスコア: 人間の判断との最先端の相関を達成する多言語機械翻訳評価のためのニューラルフレームワーク(Rei et al. 2020)
3.2 データセット
OPUS-100(Zhang et al. 2020)を選択した理由:
- 多様な翻訳言語ペアを含む(ZH-EN、JA-EN、VI-EN)
- 効果的な例選択のための多様なドメインをカバー
設定:
- Ds用に言語ペアごとに10,000のトレーニングインスタンス
- 評価用にテストセットの最初の100文
3.3 実装
scikit-learnのTfidfVectorizerとcosine_similarity関数を使用:
- ユーザーのプロンプトとDsを結合
- プロンプトと全文間のコサイン類似度スコアを算出
- 類似度に基づいて上位4つの例を選択
- 例をGPT-4のプロンプトに埋め込み

4. 結果と考察
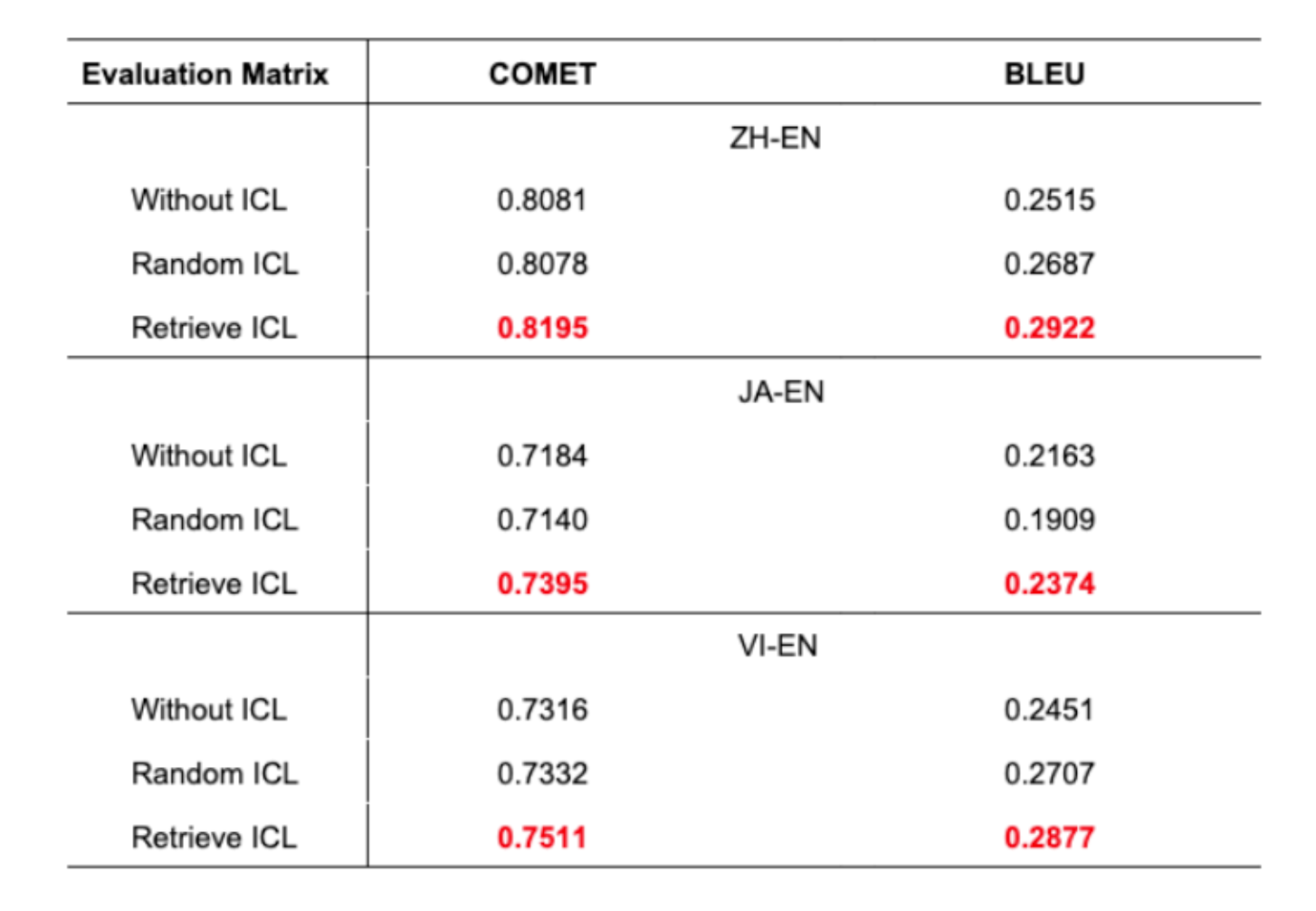
主な発見:
- 提案手法は全言語ペアで優れた翻訳精度を達成
- BLEUスコアの1%の改善は機械翻訳において有意義な向上
- ランダムICLはICLなしよりも悪い結果を出す場合がある
- これは適切な例選択の重要性を裏付けている
データセットサイズの影響

100万文でのテストにより、より大きなDsデータセットがGPT-4のタスク学習効果を向上させることが確認されました。
5. 結論と今後の課題
本論文では、TF-IDFによる検索を活用したIn-Context Learningを通じてGPT-4の翻訳性能を向上させる手法を提案しました。本手法は以下を実現しています。
- TF-IDF行列とコサイン類似度を用いたリトリーバーの構築
- ユーザーのプロンプトと密接に一致する文の選択
- BLEUスコアとCOMETスコアの両方での改善
今後の研究方向:
- データセット構築: 多様なドメインにわたる包括的で高品質な翻訳データセットの作成
- 例の数: 4つの代わりに5つまたは10個の例を使用した場合の影響の調査
6. 参考文献
- Brown, T., et al. (2020). “Language models are few-shot learners.”
- Xie, S. M., et al. (2022). “An Explanation of In-context Learning as Implicit Bayesian Inference.”
- Bashir, D. (2023). “In-Context Learning, in Context.” The Gradient.
- Das, R., et al. (2021). “Case-based reasoning for natural language queries over knowledge bases.”
- Liu, J., et al. (2022). “What makes good in-context examples for GPT-3?”
- Margatina, K., et al. (2023). “Active learning principles for in-context learning with large language models.”
- Gao, L., et al. (2023). “Ambiguity-Aware In-Context Learning with Large Language Models.”
- Papineni, K., et al. (2002). “BLEU: A method for automatic evaluation of machine translation.”
- Rei, R., et al. (2020). “COMET: A Neural Framework for MT Evaluation.”
- Zhang, B., et al. (2020). “Improving Massively Multilingual Neural Machine Translation and Zero-Shot Translation.”