要約
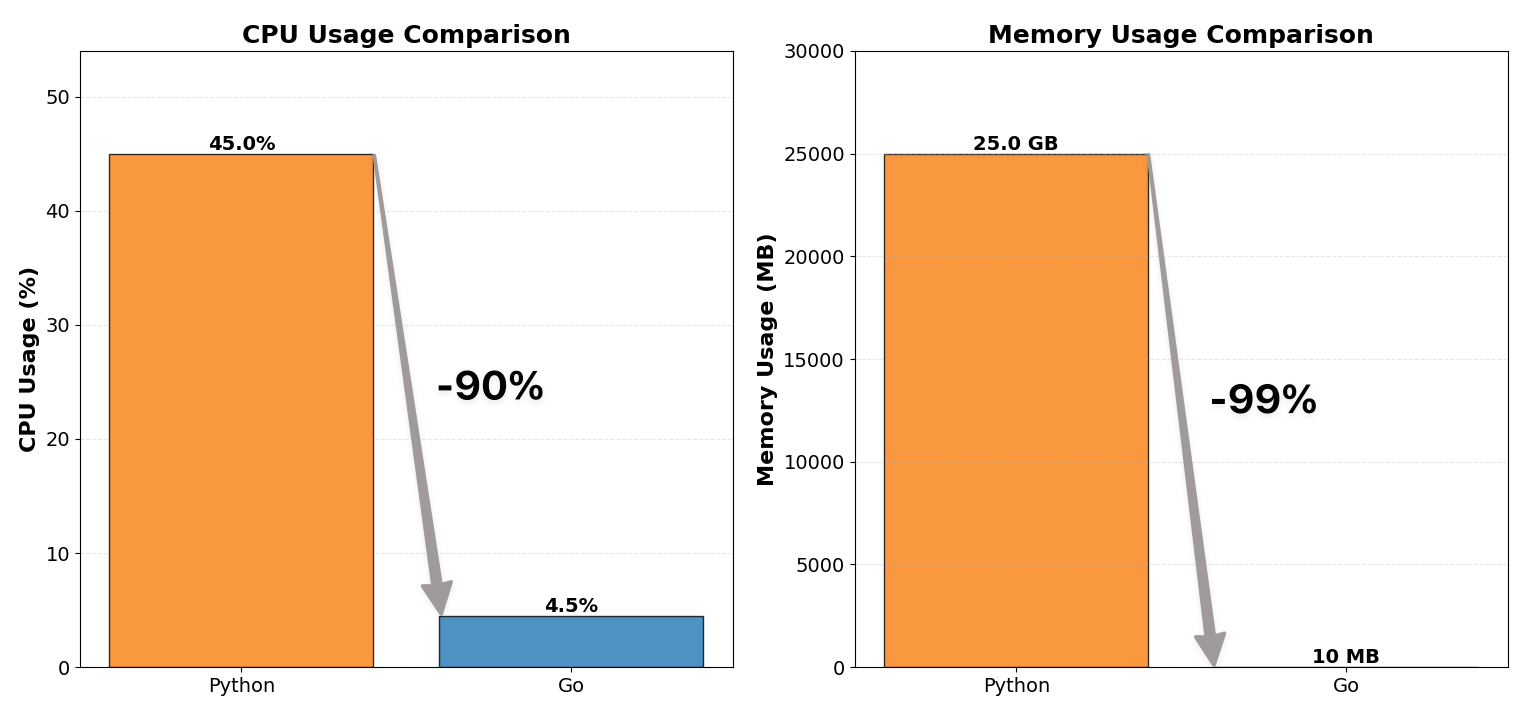
WebSocketプロキシサーバーをPythonからGoにリライトし、CPU使用率を1/10、メモリ消費を1/100に削減しました。
このプロジェクトはリソース効率の改善だけでなく、並行処理に関する重要な教訓をもたらしました。
ロックはできるだけ小さく、できるだけ少なく。
背景
VoicePingのシステムは、リアルタイムのSTT(音声認識)と翻訳パイプラインです。各クライアントデバイスはバックエンドに音声をストリーミングし、複数言語での音声認識と翻訳を行います。
WebSocketプロキシサーバーはこのパイプラインの中間に位置します。
- 各クライアントはSTTプロキシとの永続的なWebSocketセッションを維持
- プロキシは音声パケットをGPUベースの推論サーバーの一つに中継
- 文字起こしテキストを待機し、部分的なトランスクリプトと翻訳をストリーミングで返送
このアーキテクチャは数千の同時リアルタイム音声セッションをサブ秒のレイテンシで処理する必要があります。
しかし、以前のPythonベースのプロキシがボトルネックとなっていました。
改善前:Pythonプロキシ(非効率)
最初のプロキシサーバーはPython(FastAPI + asyncio + websockets)で実装され、Gunicornの複数ワーカープロセスでデプロイしていました。
小規模では問題なく動作しましたが、本番トラフィックではすぐにリソースの限界に達しました。
| 指標 | Before (Python) | After (Go) |
|---|
| CPU使用率 | 約12コア × 40〜50% | 約12コア × 4〜5% |
| メモリ使用量 | 約25 GB | 約10 MB |
Pythonが苦戦した理由
非同期であるにもかかわらず、Pythonのアーキテクチャにはいくつかの構造的なボトルネックがありました。
シングルスレッドのイベントループ:
asyncioモデルは単一スレッド上で数千のコルーチンを多重化します。つまり、一度に実行されるコルーチンは1つだけで、他はループが制御を渡すまで待機します。高負荷のI/O環境では、この単一ループが中心的なチョークポイントとなり、特に読み書きイベントが絶えないWebSocketワークロードでは深刻です。
Gunicornマルチプロセス:
全CPUコアを活用するため、複数のワーカープロセスを起動しました。各プロセスが完全なPythonランタイムとアプリケーションステートをロードするため、メモリ使用量が線形に増加します。
重いタスクコンテキスト:
各WebSocket接続は独自のスタックフレーム、Future、コールバックを保持し、接続あたり大量のメモリを消費します。
インタプリタのオーバーヘッド:
すべてのコルーチンがCPythonインタプリタ内で実行され、動的な型チェックとバイトコードディスパッチのオーバーヘッドが加わります。
結果として、システムは見かけ上は並行処理を行っていましたが、本質的にはシーケンシャルでした。すべてのコルーチンが同じイベントループで待機し、接続数が増えるにつれてレイテンシとCPU負荷が増大しました。
避けられないことでした。Pythonのモデルは、この規模での長寿命・高スループット・低レイテンシのWebSocket多重化には適していなかったのです。
そこでGoでリライトしました。
プロキシサーバーの全体像
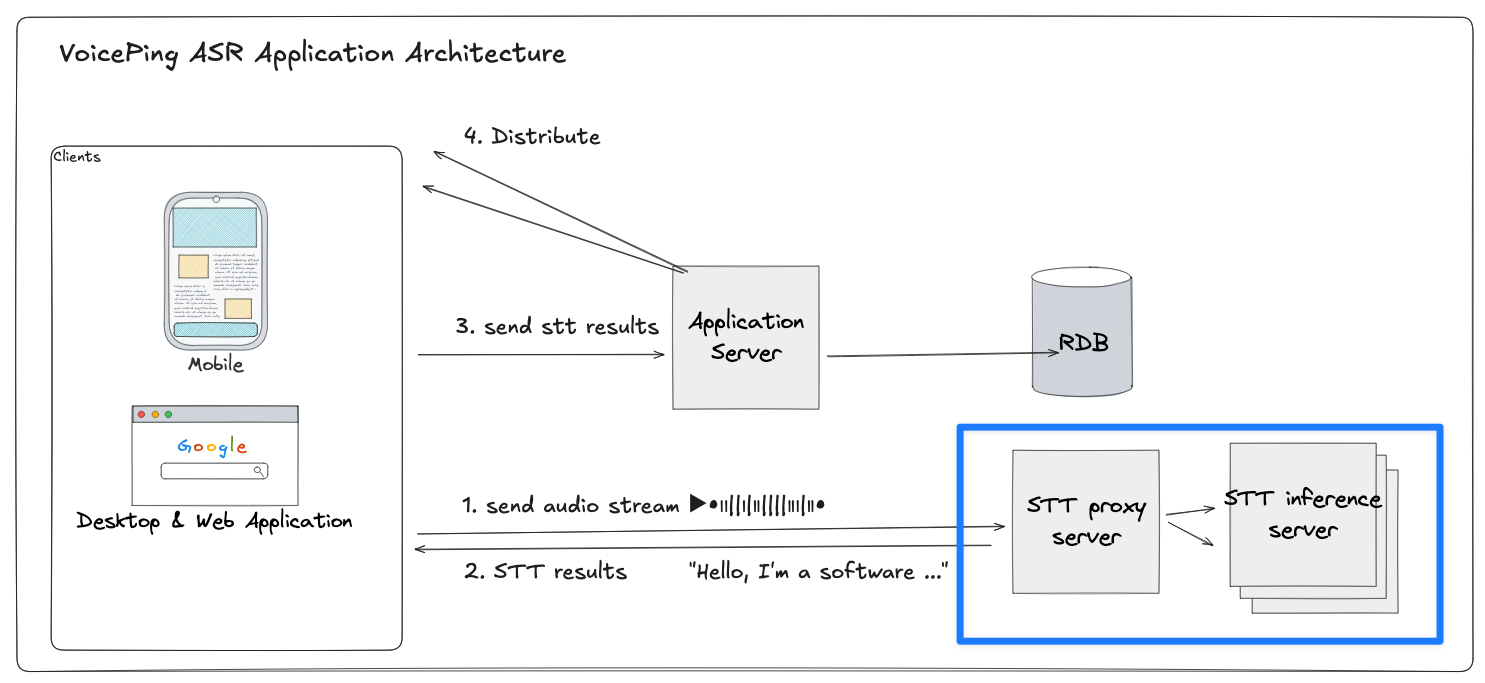
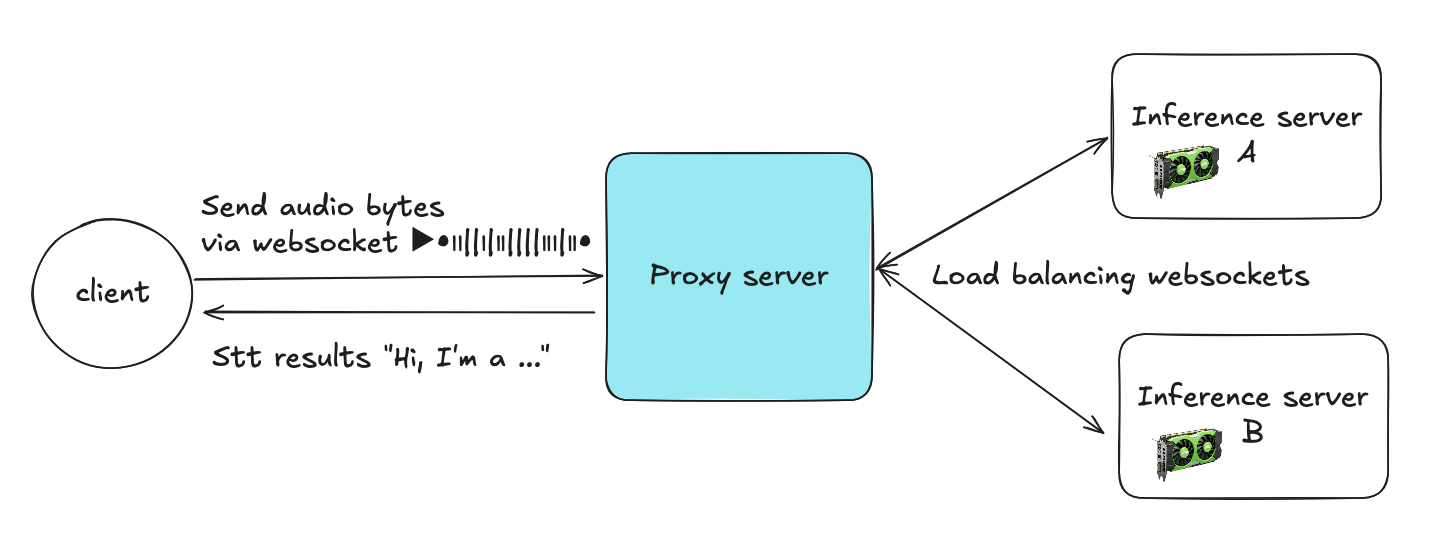
プロキシサーバーはクライアントと複数の推論サーバーの間の中間層として機能します。クライアントはWebSocket経由で音声バイトを送信し、プロキシは各ストリームを複数のSTT推論サーバーの一つにルーティングします。
クライアント → プロキシ:
各クライアントはプロキシへのWebSocket接続を開き、音声チャンクを継続的に送信します。
プロキシ → 推論サーバー:
プロキシはWebSocketコネクションプール(サーバーAにはプールA、サーバーBにはプールBなど、永続的なバックエンド接続のプール)からアクティブな接続を1つ選択します。
ストリーミング処理:
プロキシはセッション全体にわたってクライアントと選択されたバックエンド接続のマッピングを維持し、音声パケットを転送してSTT結果をリアルタイムで返送します。
接続の再利用:
セッション終了時(クライアント切断時)、プロキシはバックエンド接続をプールに戻し、別のクライアントが利用可能にします。この再利用メカニズムにより、接続の頻繁な生成・破棄とリソースのオーバーヘッドが大幅に削減されます。
プロキシサーバーは主に2つの部分を管理します。
- コネクションマネージャー: クライアント接続のルーティングとライフサイクルを管理
- WebSocketコネクションプール: 各推論サーバー向けの再利用可能なバックエンド接続を管理
各プールは1つの推論ターゲット(例: AまたはB)に対応し、事前確立されたWebSocket接続を一定数保持します。
このアーキテクチャにより、プロキシは以下を実現できます。
- 推論サーバー間の効率的な負荷分散
- 頻繁な接続確立のオーバーヘッドの回避
コネクションプール管理の機能要件
コネクションプール管理の設計は、新しいプロキシアーキテクチャで最も重要な部分でした。プールは数千の同時WebSocketセッションを効率的に処理しつつ、システムの安定性と軽量性を維持する必要がありました。
| 要件 | 目的 |
|---|
| 利用可能な接続の取得 | 受信リクエストは他のクライアントをブロックせずに、即座に利用可能なバックエンド接続を取得する必要があります。低レイテンシと円滑な負荷分散を確保します。 |
| 接続のプールへの返却 | クライアントセッション終了後、接続を解放して再利用可能にします。接続の頻繁な開閉のオーバーヘッドを最小化します。 |
| 健全な接続のみを維持 | 定期的なヘルスチェックで障害のある接続を除去または再作成します。異常な接続の蓄積によるサイレント障害を防ぎます。 |
| データベース設定の同期 | 中央データベースからバックエンド接続設定を定期的に同期し、再起動なしで動的スケーリングを可能にします。 |
初期設計(ナイーブ)
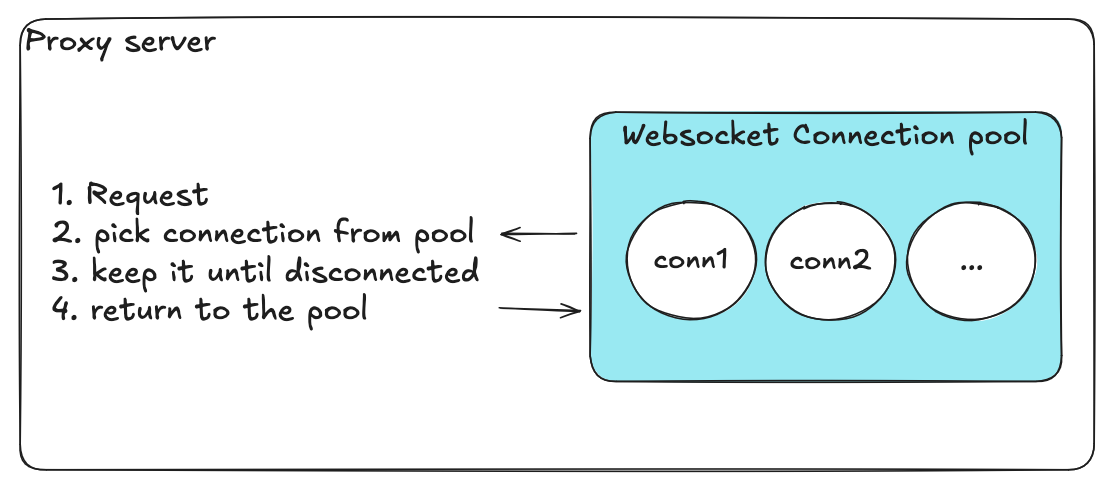
最初は素朴でシンプルな設計を実装しました。
- 全接続を保持する単一の配列
- 「使用中」/「利用可能」状態を示すブーリアンフラグ
- 全操作に対する1つのグローバルロック
接続の取得手順:
- ロックの取得
- 配列をスキャンして利用可能な接続を探す
- 「使用中」としてマーク
- ロックの解放
接続の返却も同様で、ロックを取得し、フラグを反転し、ロックを解放します。
データベース設定を定期的にチェックする別のgoroutineも用意しました。このgoroutineはデータベースからサーバーリストやプールサイズなどのバックエンド設定を更新し、再起動なしで常に最新の設定を維持できるようにしました。
別のヘルスチェックgoroutineが定期的に全接続をスキャンし、異常な接続を除去して必要に応じて新しい接続を追加しました。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
| // ────────────────────────────
// FIRST DESIGN (naive, global mutex)
// Single slice + flags, one coarse-grained mutex.
// ────────────────────────────
type Conn struct {
id string
ws *websocket.Conn
inUse bool
healthy bool
}
type Pool struct {
mu sync.Mutex
conns []*Conn
maxSize int
dialURL string
}
// newConn dials a backend and returns a connected *Conn.
// NOTE: In this first design we (incorrectly) call this under the global lock.
func (p *Pool) newConn(ctx context.Context) (*Conn, error) {
d := websocket.Dialer{}
c, _, err := d.DialContext(ctx, p.dialURL, nil)
if err != nil {
return nil, err
}
return &Conn{
id: uuid.NewString(),
ws: c,
inUse: false,
healthy: true,
}, nil
}
// ────────────────────────────
// AdjustPool
// Check capacity vs current size; if not full, fill it.
// BAD PATTERN: holds the global mutex across slow I/O (dial).
// ────────────────────────────
func (p *Pool) AdjustPool(ctx context.Context) error {
p.mu.Lock()
defer p.mu.Unlock()
cur := len(p.conns)
if cur >= p.maxSize {
return nil
}
needed := p.maxSize - cur
for i := 0; i < needed; i++ {
conn, err := p.newConn(ctx)
if err != nil {
return fmt.Errorf("adjust: dial failed: %w", err)
}
p.conns = append(p.conns, conn)
}
return nil
}
// ────────────────────────────
// GetPoolStats
// Return total / in-use / available counts.
// BAD PATTERN: O(n) scan under global lock every call.
// ────────────────────────────
type PoolStats struct {
Total int
InUse int
Available int
Healthy int
Unhealthy int
}
func (p *Pool) GetPoolStats() PoolStats {
p.mu.Lock()
defer p.mu.Unlock()
var inUse, healthy int
for _, c := range p.conns {
if c.inUse {
inUse++
}
if c.healthy {
healthy++
}
}
total := len(p.conns)
return PoolStats{
Total: total,
InUse: inUse,
Available: total - inUse,
Healthy: healthy,
Unhealthy: total - healthy,
}
}
// ────────────────────────────
// HealthCheck
// Ping all connections and mark healthy=false on failures.
// BAD PATTERN: holds global lock during network I/O & mutates in place.
// ────────────────────────────
func (p *Pool) HealthCheck(ctx context.Context, timeout time.Duration) {
p.mu.Lock()
defer p.mu.Unlock()
deadline := time.Now().Add(timeout)
for _, c := range p.conns {
if c.ws == nil {
c.healthy = false
continue
}
if err := c.ws.WriteControl(websocket.PingMessage, []byte("ping"), deadline); err != nil {
c.healthy = false
_ = c.ws.Close()
c.ws = nil
continue
}
c.healthy = true
}
}
|
初期設計の問題点
小規模テストでは動作しましたが、負荷がかかると初期のプーリングモデルは破綻しました。以下の問題を観測しました。
合計数の不正確さ(オーバーシュート/アンダーシュート):
並行するpick/return操作が1つの粗いロックの下で同じスライスとフラグを変更するため、リトライやタイムアウトにより接続が二重に返却されたり失われたりし、最大値を超えたりプールが枯渇したりしました。
競合状態による並行アクセス → クラッシュと状態の破損:
ヘルスチェックとメトリクスのgoroutineがリクエストハンドラーと競合し、長時間のヘルスチェックがグローバルロックを保持する一方、リーダーが半分更新されたフラグを読み取ることがあり、パニックや容量があるにもかかわらず「利用可能な接続がありません」エラーが発生しました。
goroutineリーク:
失敗したダイアルやタイムアウトしたヘルスチェックが必ずしもキャンセルまたは回収されず、リトライが新しいgoroutineを生成する一方で古いgoroutineへの参照が残りました。
脆弱な可観測性:
スライスとフラグから導出されたカウンターが実際の状態と頻繁に不一致となり、アラートがノイジーになって実際のインシデントが隠れました。
ロック競合とレイテンシスパイク:
単一ロックの下でのO(n)スキャンにより、並行度が増すにつれてテールレイテンシが増大しました。
警告: 根本原因を一言で言えば:1つの広く長く保持されるロックで守られた過剰な共有ステートに加え、独立すべき操作(ヘルスチェック/メトリクス)が同じロックを奪い合っていたことです。
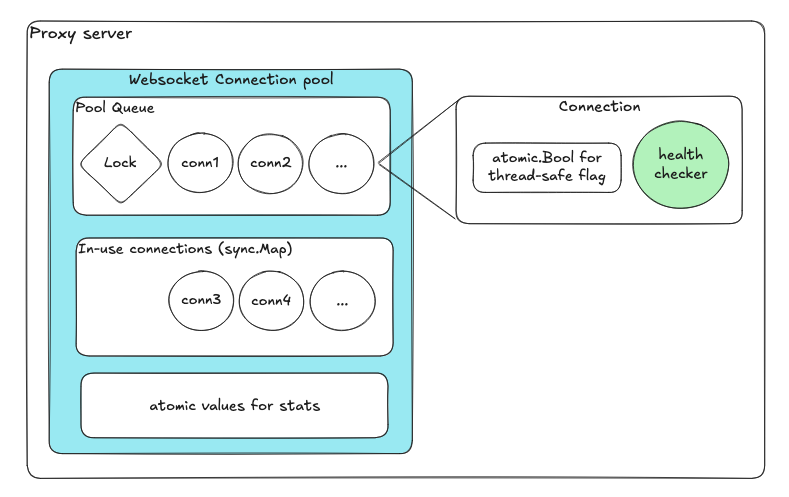
改善後の設計
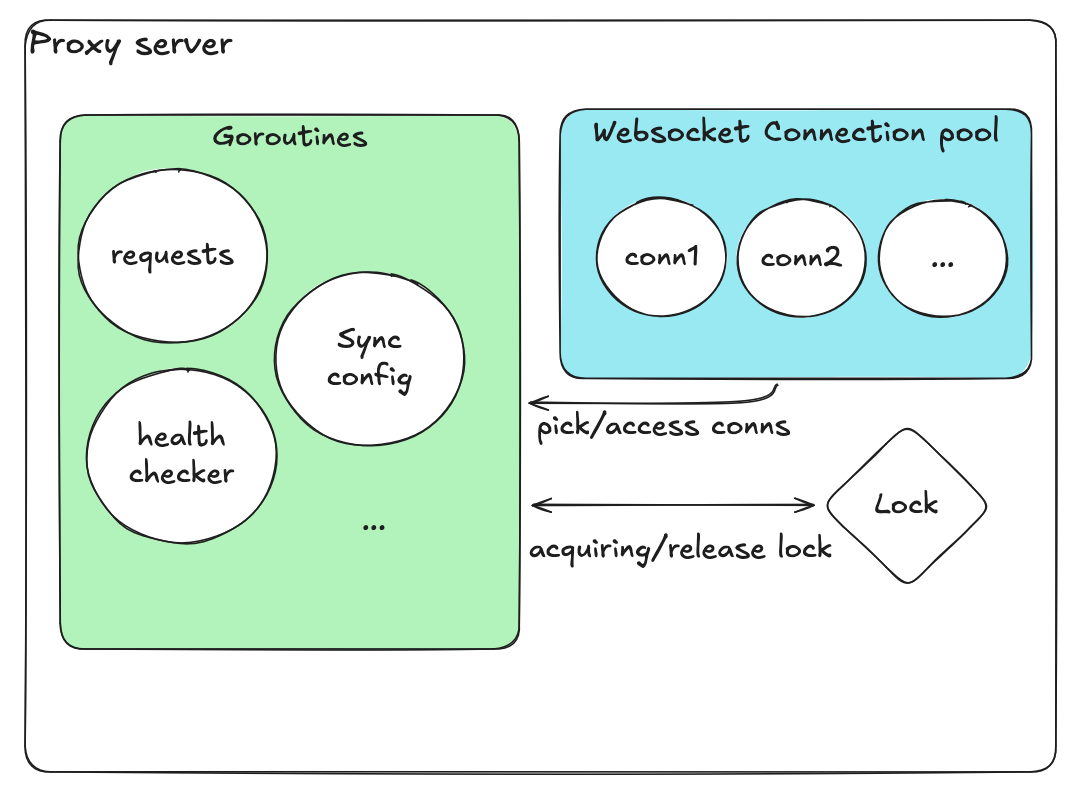
再設計は共有ステートの最小化と責務の分離に焦点を当てました。
| コンポーネント | 目的 |
|---|
| 利用可能接続用キュー | エンキュー/デキューが内部ロックを自動的に処理 |
| 使用中接続用sync.Map | ロックフリーの並行マップ |
| アトミック変数 | ヘルスフラグとカウンター |
| 接続ごとの専用goroutine | 独立したヘルスチェック |
各コンポーネントが独立して動作し、プール全体のロックはありません。ロックの数とスコープが劇的に減少しました。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
| package pool
import (
"context"
"errors"
"net/http"
"sync"
"sync/atomic"
"time"
"github.com/google/uuid"
"github.com/gorilla/websocket"
)
// ────────────────────────────
// Conn (a single reusable backend WebSocket connection)
// ────────────────────────────
//
// ✅ GOOD PATTERN:
// - Keep each connection self-contained and concurrent-safe using atomics.
// - Encapsulate health logic inside the Conn itself (no shared state mutation).
// - Avoid external locks and let each conn manage its own goroutine lifecycle.
type Conn struct {
id string
ws *websocket.Conn
healthy atomic.Bool // ✅ lock-free health status flag
lastPing atomic.Int64 // ✅ atomic timestamp for last heartbeat
}
// ✅ GOOD PATTERN: Explicit small helper methods (no external mutation)
func (c *Conn) ID() string { return c.id }
func (c *Conn) IsAlive() bool {
return c.healthy.Load()
}
// ✅ GOOD PATTERN: Safe close, idempotent and isolated
func (c *Conn) Close() error {
if c.ws != nil {
return c.ws.Close()
}
return nil
}
// ✅ GOOD PATTERN: Health loop runs independently per connection
// - No shared/global lock.
// - Non-blocking heartbeat.
// - Fails fast and marks itself dead without blocking pool operations.
func (c *Conn) StartHealthLoop(ctx context.Context, interval time.Duration) {
t := time.NewTicker(interval)
defer t.Stop()
for {
select {
case <-ctx.Done():
return
case <-t.C:
deadline := time.Now().Add(interval / 2)
if err := c.ws.WriteControl(websocket.PingMessage, []byte("ping"), deadline); err != nil {
c.healthy.Store(false)
_ = c.Close()
return
}
c.lastPing.Store(time.Now().UnixNano())
c.healthy.Store(true)
}
}
}
// ────────────────────────────
// ConnPool (fast path only — no dialing, no blocking I/O)
// ────────────────────────────
//
// ✅ GOOD PATTERN:
// - Separate responsibilities: pool only manages available connections.
// - No dialing / blocking I/O under locks.
// - Use channel buffering and atomic counters for concurrency safety.
// - Eliminates coarse-grained global mutex.
type ConnPool struct {
available chan *Conn // ✅ buffered channel for ready conns (lock-free)
inUse sync.Map // ✅ concurrent map for tracking active conns
statsIn atomic.Int64 // ✅ atomic counters (no need for locks)
statsOut atomic.Int64
}
// ✅ GOOD PATTERN: Explicit, fixed-capacity pool construction
func NewConnPool(capacity int) *ConnPool {
return &ConnPool{
available: make(chan *Conn, capacity),
}
}
func (p *ConnPool) Capacity() int { return cap(p.available) }
// ✅ GOOD PATTERN: Non-blocking Acquire
// - Never holds locks while waiting for I/O.
// - Returns instantly if no conn available.
func (p *ConnPool) Acquire(ctx context.Context) (*Conn, error) {
select {
case c := <-p.available:
p.inUse.Store(c.id, c)
p.statsIn.Add(1)
return c, nil
case <-ctx.Done():
return nil, ctx.Err()
default:
return nil, errors.New("no connection available")
}
}
// ✅ GOOD PATTERN: Non-blocking Release
// - Never waits for space in the channel.
// - Drops unhealthy or excess conns immediately.
// - No global mutex.
func (p *ConnPool) Release(c *Conn) {
p.inUse.Delete(c.id)
p.statsOut.Add(1)
if c.IsAlive() {
select {
case p.available <- c:
// ✅ returned to pool safely
default:
// ✅ pool full → discard stale conn safely
_ = c.Close()
}
} else {
// ✅ unhealthy → close immediately
_ = c.Close()
}
}
// ✅ GOOD PATTERN: Offer is used by reconciler (external goroutine)
// - Keeps dialing/repair logic out of hot path.
// - Backpressure-safe with non-blocking insert.
func (p *ConnPool) Offer(c *Conn) bool {
select {
case p.available <- c:
return true
default:
return false
}
}
// ────────────────────────────
// Stats and Metrics
// ────────────────────────────
//
// ✅ GOOD PATTERN:
// - Lock-free snapshot using atomics.
// - Avoids holding locks during metrics collection.
type PoolStats struct {
Capacity int
Available int
InUse int
Acquired int64
Released int64
}
// ✅ GOOD PATTERN: Snapshot safely aggregates pool state without blocking
func (p *ConnPool) Snapshot() PoolStats {
inUseCount := 0
p.inUse.Range(func(_, _ any) bool {
inUseCount++
return true
})
return PoolStats{
Capacity: cap(p.available),
Available: len(p.available),
InUse: inUseCount,
Acquired: p.statsIn.Load(),
Released: p.statsOut.Load(),
}
}
|
ポイント: 各コンポーネントがプール全体のロックなしで独立して動作します。ロックの数とスコープが劇的に減少しました。
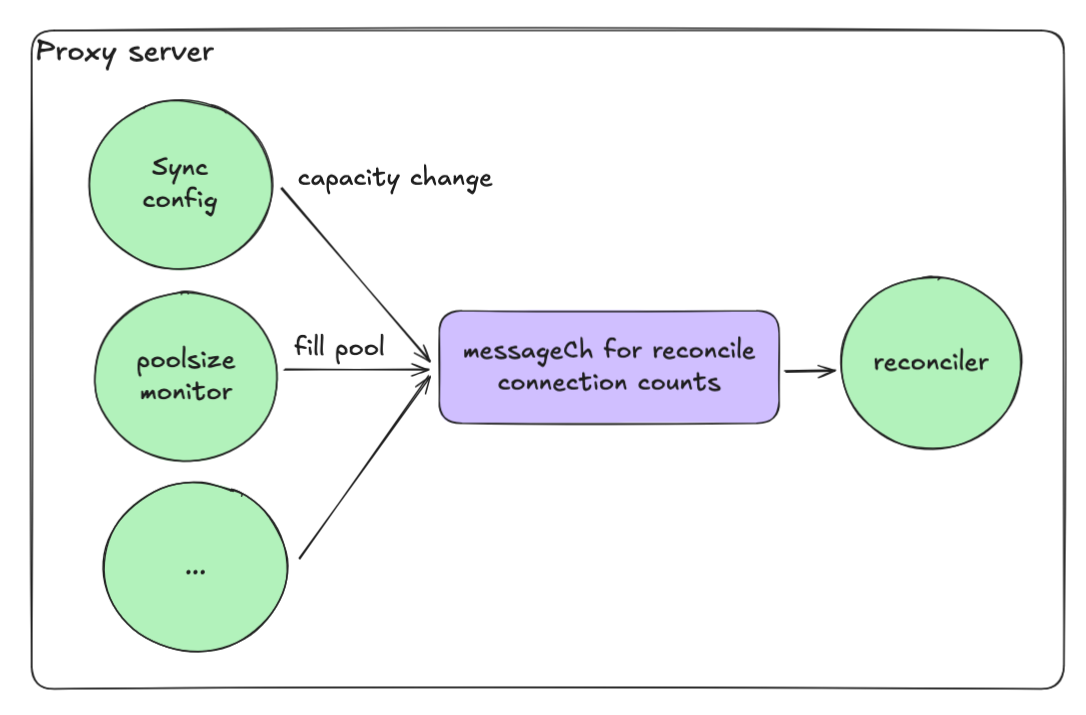
イベント駆動型リコンシリエーション
プールの適切なサイズを維持することも課題でした。接続の失敗や返却時に、リコンシリエーションが並行で実行されると最大プールサイズを簡単にオーバーシュートしてしまいます。
解決策はイベント駆動型のリコンシリエーションループでした。
- 各操作がチャネル(messageCh)にメッセージを送信
- リコンシリエーションgoroutineがこれらのメッセージを順次処理
- これにより競合状態が排除される
このモデルにより、高い並行性を維持しつつ、決定的で安全なシステムを実現できました。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
| type ServerConnectionPool struct {
ctx context.Context
cancel context.CancelFunc
reconcileCh chan struct{}
logger *zap.Logger
// ... other fields ...
}
// ✅ GOOD PATTERN: Constructor wires a buffered (size=1) signal channel to enable coalescing.
func NewServerConnectionPool(logger *zap.Logger /* ... */) *ServerConnectionPool {
ctx, cancel := context.WithCancel(context.Background())
return &ServerConnectionPool{
ctx: ctx,
cancel: cancel,
reconcileCh: make(chan struct{}, 1), // ✅ coalescing buffer
logger: logger,
// ... init other fields ...
}
}
// ✅ GOOD PATTERN: Non-blocking signal helper; bursts coalesce into a single pending signal.
func (bp *ServerConnectionPool) trySend(ch chan struct{}) {
select {
case ch <- struct{}{}:
default:
// already queued; coalesced
}
}
// triggerReconcile only *requests* reconciliation; never performs it inline.
// ✅ GOOD PATTERN: no work on the caller's goroutine, prevents stampedes.
func (bp *ServerConnectionPool) triggerReconcile() {
bp.trySend(bp.reconcileCh)
}
// ✅ GOOD PATTERN: Public starter that owns the worker lifecycle.
func (bp *ServerConnectionPool) Start() {
go bp.reconcileWorker()
}
// ✅ GOOD PATTERN: Graceful shutdown.
func (bp *ServerConnectionPool) Stop() {
bp.cancel()
}
// reconcileWorker serializes reconciliation and coalesces bursts.
// ✅ GOOD PATTERN:
// - Single-threaded worker → no concurrent ensureCapacity() runs
// - Periodic safety net with light jitter to avoid thundering herds
// - Drain queue before each run to collapse multiple signals into one
func (bp *ServerConnectionPool) reconcileWorker() {
jitter := func(base time.Duration) time.Duration {
// small ±10% jitter
n := time.Duration(float64(base) * (0.9 + 0.2*rand.Float64()))
return n
}
ticker := time.NewTicker(jitter(5 * time.Second))
defer ticker.Stop()
bp.logger.Debug("Reconciliation worker started", zap.String("pool", bp.GetName()))
defer bp.logger.Debug("Reconciliation worker stopped", zap.String("pool", bp.GetName()))
// Optional: run once immediately on startup
bp.ensureCapacity()
for {
select {
case <-bp.ctx.Done():
return
case <-ticker.C:
// ✅ Periodic reconciliation as a safety net
bp.ensureCapacity()
// reset ticker with jitter to spread load
ticker.Reset(jitter(5 * time.Second))
case <-bp.reconcileCh:
// ✅ Drain any queued signals: burst -> single reconciliation
for {
select {
case <-bp.reconcileCh:
// keep draining
default:
bp.ensureCapacity()
goto CONTINUE
}
}
}
CONTINUE:
}
}
// ensureCapacity is the single authoritative place that:
// 1) Cleans unhealthy queued conns
// 2) Computes current vs target
// 3) Grows or shrinks the pool
// 4) Emits metrics/logs
func (bp *ServerConnectionPool) ensureCapacity() {}
// ────────────────────────────
// Event sources that *request* reconciliation
// ────────────────────────────
// Health watcher: when a server flips health, request reconcile.
// ✅ GOOD PATTERN: do not call ensureCapacity() here; just signal.
func (bp *ServerConnectionPool) startHealthWatcher(healthCh <-chan HealthEvent) {
go func() {
for {
select {
case <-bp.ctx.Done():
return
case ev := <-healthCh:
if ev.Changed {
bp.logger.Debug("health change → reconcile",
zap.String("server", ev.ServerID))
bp.triggerReconcile()
}
}
}
}()
}
// Config watcher: when scale target changes, request reconcile.
// ✅ GOOD PATTERN: apply config change, then signal worker.
func (bp *ServerConnectionPool) startConfigWatcher(cfgCh <-chan ScaleTarget) {
go func() {
for {
select {
case <-bp.ctx.Done():
return
case target := <-cfgCh:
// update internal target state...
bp.logger.Debug("scale target changed → reconcile",
zap.Int("target", target.Connections))
bp.triggerReconcile()
}
}
}()
}
|
設計のポイント:
- シングルスレッドワーカーがリコンシリエーションをシリアライズ
- バッファ付きチャネルがバーストを単一操作に集約
- ジッターを伴う定期的なセーフティネットがサンダリングハードを防止
ローカルパフォーマンステスト
以下のセットアップでローカル環境でのパフォーマンスを検証しました。
テスト構成
| コンポーネント | 設定 |
|---|
| プロキシ | Goベースの WebSocketプロキシ |
| バックエンド | 3台のEcho WebSocketサーバー |
| 負荷 | 3,000接続を同時に(ランプアップなし) |
| トラフィック | 1 KBテキストメッセージ @ 接続あたり100メッセージ/秒 |
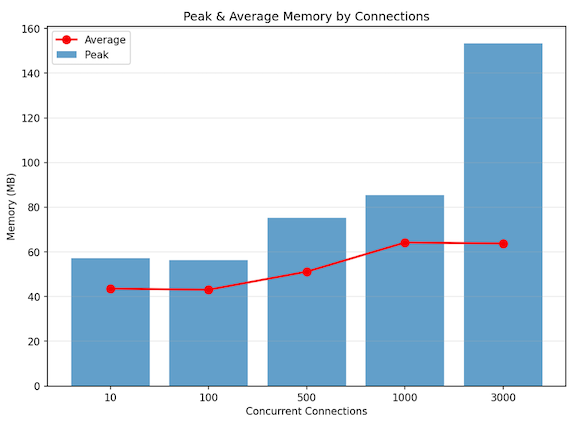
結果
| 指標 | 値 |
|---|
| 同時セッション数 | 約3,000(安定) |
| スループット | 約30万メッセージ/秒 |
| ピークメモリ | 約150 MB |
| 平均メモリ | 約60 MB |
| CPU使用率 | 12コアの約4〜5% |
プロキシが完全な同時接続バーストの下でもフラットなメモリフットプリントを維持することが確認され、コネクションプールの分離とイベント駆動型リコンシリエーションモデルの有効性が実証されました。
まとめ
新しいGoベースのプロキシをデプロイした後、パフォーマンス、スケーラビリティ、安定性の全面で大幅な改善を確認しました。
| カテゴリ | Python (FastAPI + asyncio + Gunicorn) | Go (Goroutines + Channels + Atomics) | 改善率 |
|---|
| CPU使用率 | 約12コア × 40〜50% | 約12コア × 4〜5% | 約90%削減 |
| メモリ使用量 | 約25 GB | 約60〜150 MB | 約99%削減 |
| スケーラビリティ | 数百接続が限界 | 数千接続を維持 | 10倍のスケール |
Goへのリライトは単なる言語変更ではなく、並行処理モデルの変革でした。
注: 重要なポイント: 並行処理は、保護された共有可変ステートとしてではなく、独立した通信プロセスとして設計すべきです。
このアーキテクチャの転換により、プロキシは数百から数千の同時WebSocketセッションに、ほぼ一定のリソース消費で、コードや運用の明確さを損なうことなくスケールできるようになりました。
参考文献
- Go Concurrency Patterns - golang.org/doc/effective_go
- gorilla/websocket - github.com/gorilla/websocket
- Python asyncio Event Loop - docs.python.org