顔分析、姿勢推定、感情検出のための動画前処理パイプラインの構築に関する研究レポートです。
概要
本プロジェクトでは、動画・音声データの前処理を自動化し、動画生成モデルの学習に必要な情報を抽出するパイプラインを構築しました。顔検出、感情分類、姿勢推定、音声処理を一貫して処理します。
主な機能:
- 固有の顔の自動検出と分離
- 頭部姿勢の推定(ヨー、ピッチ、ロール)
- ディープラーニングによる感情分類
- 音声分類と音声分離
- クリップ生成(3〜10秒のセグメント)
1. はじめに
動画ベースの生成モデルの台頭により、適切に前処理された動画データセットの需要が高まっています。本プロジェクトは以下の自動化を実現します。
- 固有の顔の自動分類・認識
- 時系列での顔の感情と頭部姿勢の検出
- BGMの音声分類と音声の分離
- 生成モデル用の動画のトリミングと精緻化
2. 方法論
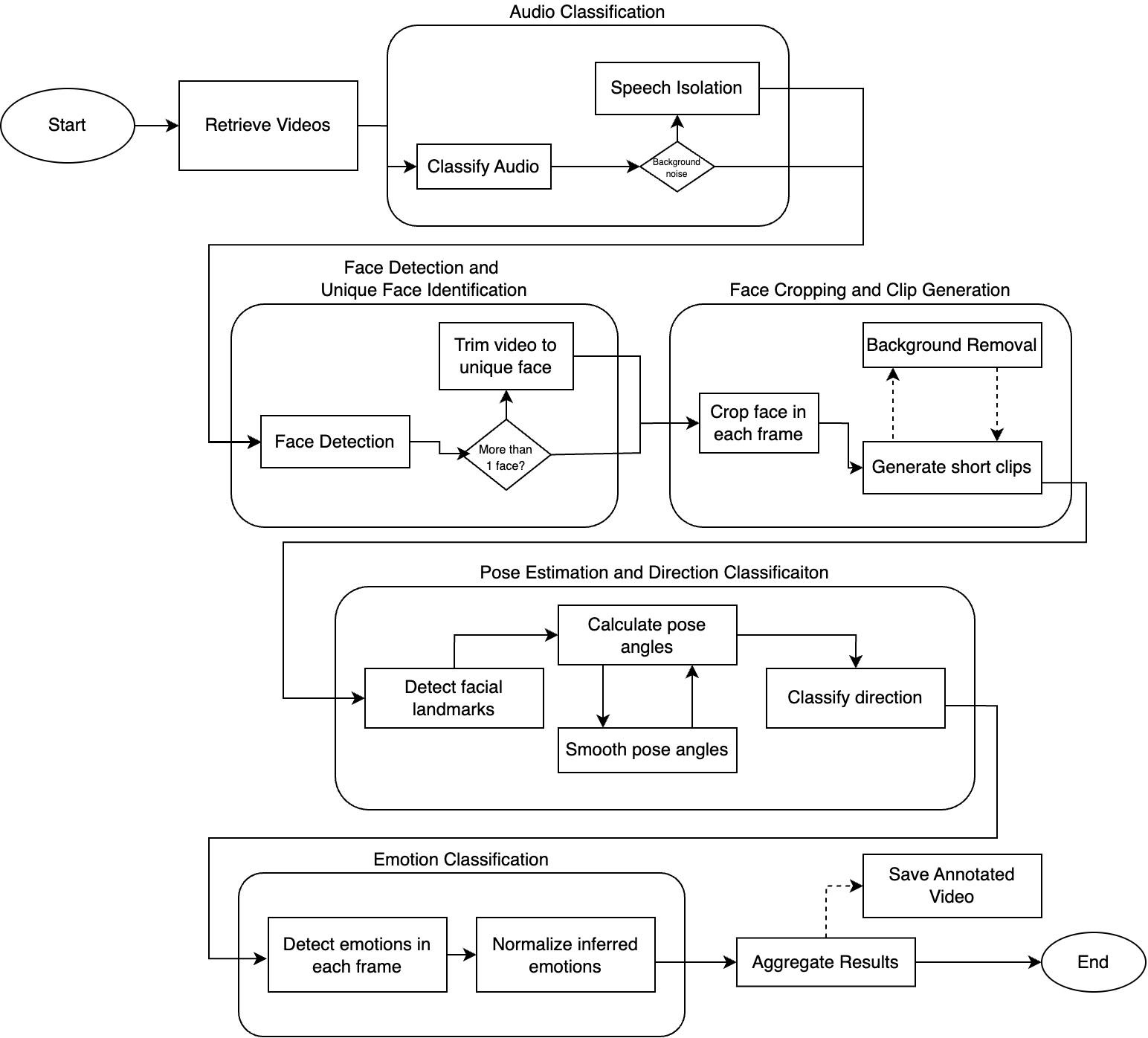
パイプラインの概要
前処理パイプラインは5つの主要ステージで構成されています。
| ステージ | 機能 |
|---|---|
| 音声分類 | 音声の識別とバックグラウンドノイズからの分離 |
| 顔検出 | 動画内の固有の顔の検出と識別 |
| 顔クロッピング | 顔にフォーカスしたクリップの生成(3〜10秒) |
| 姿勢推定 | 頭部の向きの推定(ヨー、ピッチ、ロール) |
| 感情分類 | 各フレームでの感情検出 |
2.1 動画処理
yt-dlpを使用して動画をダウンロードし、フレームごとに処理します。
| |
2.2 音声分類
Audio Spectrogram Transformerモデルを使用して音声を分類します。
- 音声をスペクトログラムに変換
- Vision Transformerで分類を実行
- BGMノイズ検出の閾値は約20%
結果例:
| 動画の種類 | 音声 % | 音楽 % |
|---|---|---|
| 音楽付き解説 | 50.28% | 37.20% |
| ライブパフォーマンス | 1.50% | 46.54% |
| ニュースインタビュー | 82.64% | 0% |
2.3 顔検出とクロッピング
YuNet顔検出モデルを使用:
- 各フレームですべての顔を検出
- 最大の顔を対象として選択
- 一定のサイズにクロップ・リサイズ
- 3〜10秒のクリップを生成
注: rembgを使用したオプションの背景除去により、対象をさらに分離できます。
2.4 姿勢推定
68個の顔ランドマークを使用して頭部姿勢を推定:
- Yaw: 左右の回転(10度以上で右/左向き)
- Pitch: 上下の回転(10度以上で上/下向き)
- Roll: 頭部の傾き
姿勢の値は連続フレームのバッファを使用して平滑化されます。
2.5 感情分類
Hugging Faceのfacial_emotions_image_detectionを使用:
- 検出可能な感情: 喜び、悲しみ、怒り、中立、恐怖、嫌悪、驚き
- スコアは合計100%に正規化
- 動画全体のサマリーとして平均化
3. 結果
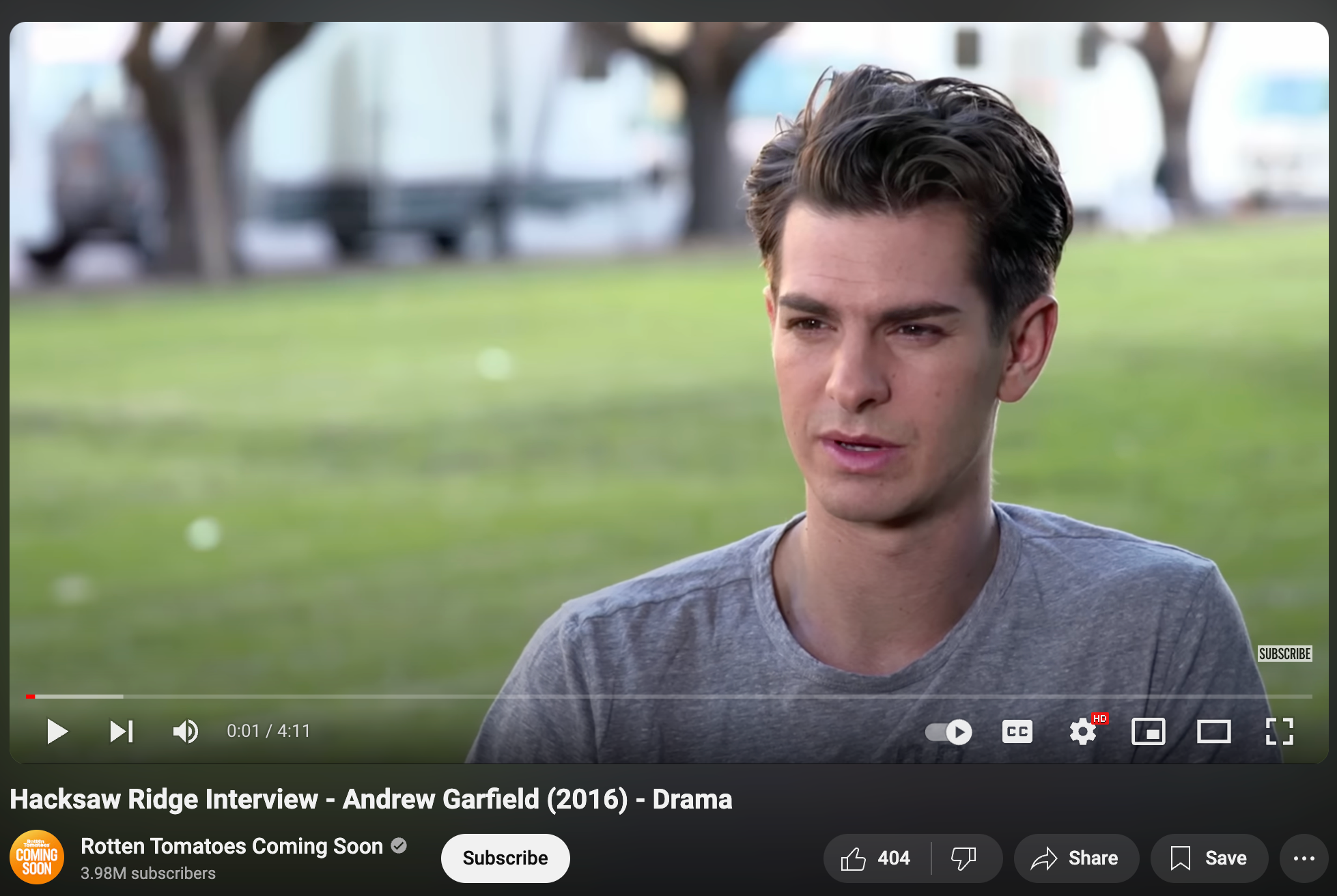
動画分析の例
テスト動画: “Hacksaw Ridge Interview - Andrew Garfield” (4分11秒)
| 指標 | 値 |
|---|---|
| 総フレーム数 | 6,024 |
| FPS | 23.97 |
| 顔検出率 | 98.26% |
| フレームあたりの平均顔数 | 1.0 |
| 生成クリップ数 | 26 |
音声分類
Speech: 88.89%
Rustling leaves: 1.12%
Rustle: 0.74%
音声信頼度が高いため、音声分離の必要なし。
姿勢推定の例
正面向きクリップ:
- Yaw: 0.65°, Pitch: 4.07°
- 方向: “Forward”

右向きクリップ:
- Yaw: 10.36°, Pitch: -1.22°
- 方向: “Right”

感情分類
モデルは感情間で不確実性を示し、最高確率が約25%でした。これは静止画像からの感情検出の複雑さを示しています。
4. 今後の展望
- 追加の分類機能: 読唇術、ジェスチャー検出
- GPU高速化: リソース制限により現在はCPUのみ
- ファインチューニング済みモデル: 特定タスク向けのカスタムモデル
- 高度な感情検出: 静止画像を超えたマルチモーダルアプローチ
参考文献
- 1adrianb/face-alignment - 2D・3D顔アラインメントライブラリ
- ageitgey/face_recognition - Python用顔認識API
- CelebV-HQ - 大規模動画顔属性データセット
- danielgatis/rembg - 背景除去ツール
- dima806/facial_emotions_image_detection - Hugging Face
- facebookresearch/demucs - 音楽ソース分離
- MIT/ast-finetuned-audioset - Audio Spectrogram Transformer