NeMo MSDDとPyannote 3.1を6つの実運用シナリオで比較評価した技術レポートです。
テスト構成: 6シナリオ、5言語(EN、JA、KO、VI、ZH)、3モデル ハードウェア: NVIDIA GeForce RTX 4090 日付: 2025年12月
要約
3つの話者ダイアライゼーションモデルを6つのシナリオで評価しました。
| モデル | 説明 | 平均DER | 平均RTF |
|---|---|---|---|
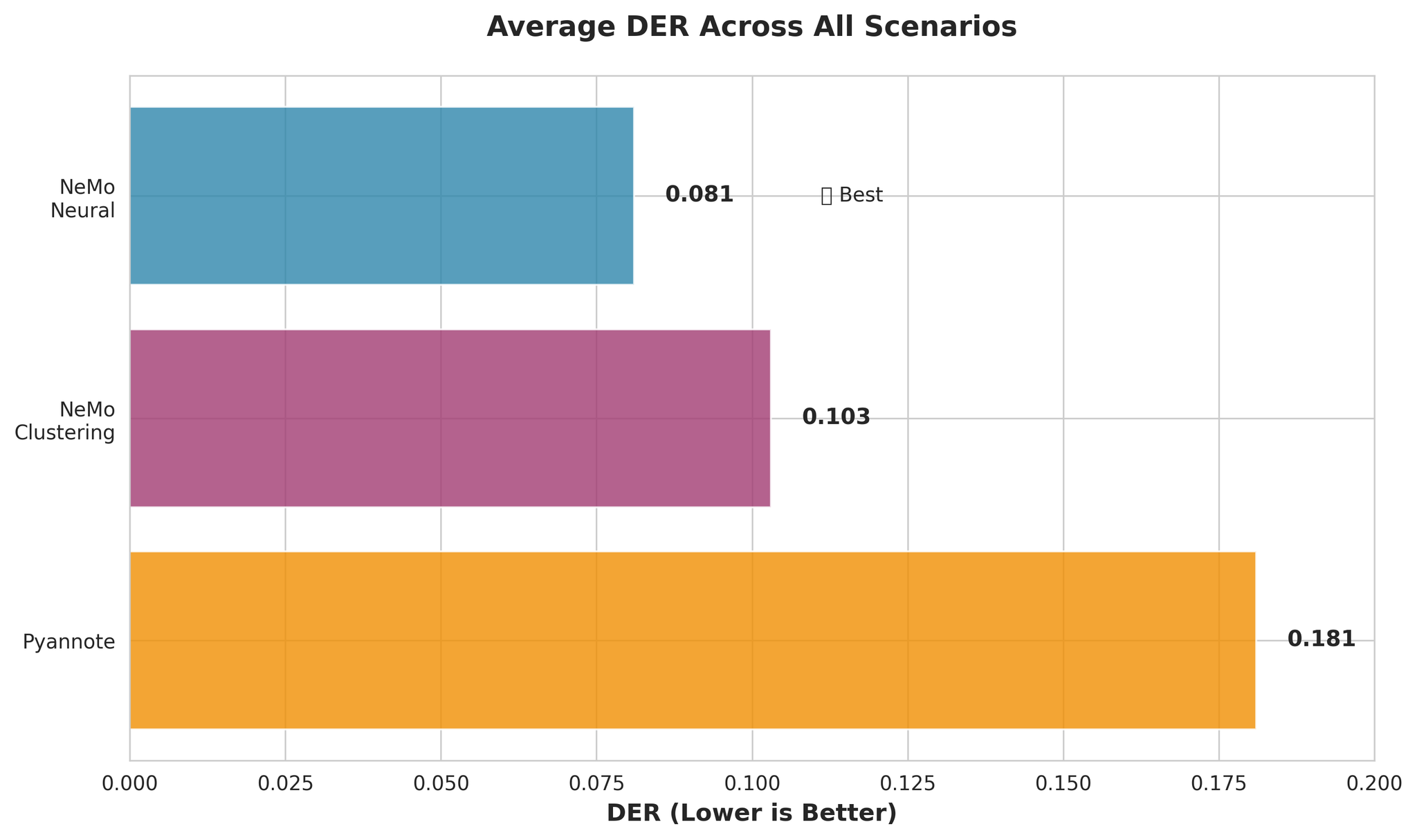
| NeMo Neural (MSDD) | ニューラル精緻化を伴うMulti-Scale Diarization Decoder | 0.081 | 0.020 |
| NeMo Clustering | MSDDなしのクラスタリングのみ | 0.103 | 0.010 |
| Pyannote 3.1 | エンドツーエンドのダイアライゼーションパイプライン | 0.181 | 0.027 |
主要な発見:
- NeMo Neuralが最高精度と高速処理を両立
- 日本語は長時間コンテキストで改善: 30分以上の音声で性能が向上
- 日本語を除く多言語処理では優秀な結果(DER: 0.050)
1. はじめに
本番環境で使用するダイアライゼーションモデルを選定するため、実運用条件を反映した6つのシナリオで評価を実施しました。
- 音声長の違い(10分〜1時間)
- 話者数の違い(4〜14名)
- オーバーラップ比率の違い(0%〜40%)
- 多言語音声の混在
2. テスト対象モデル
NeMo Neural (MSDD)
- TitaNet-largeによる192次元の話者埋め込み
- 5つの時間スケール(1.0秒〜3.0秒のウィンドウ)で音声を処理
- MSDDニューラルネットワークが初期クラスタリング結果を精緻化
- 平均RTF: 約0.015〜0.032
NeMo Clustering(クラスタリングのみ)
- 同一の埋め込みモデル(TitaNet-large)
- MSDD精緻化なしのスペクトラルクラスタリングのみ
- ニューラル精緻化を省略するため大幅に高速
- 平均RTF: 約0.014〜0.028
Pyannote 3.1
- VAD、セグメンテーション、クラスタリングを含むエンドツーエンドパイプライン
- pyannote/segmentation-3.0およびwespeakerモデルを使用
- 平均RTF: 約0.018〜0.043
3. 評価設定
3.1 テストシナリオ
| シナリオ | 長さ | 話者数 | オーバーラップ | 目的 |
|---|---|---|---|---|
| 長時間音声 | 10分 | 4〜5 | 15% | 標準的な本番環境 |
| 超長時間 | 30分 | 10〜12 | 15% | ストレステスト |
| 1時間音声 | 60分 | 12〜14 | 15% | 極限時間テスト |
| 高オーバーラップ | 15分 | 8〜10 | 40% | 最悪ケースのオーバーラップ |
| 多言語(5言語) | 15分 | 8 | 20% | EN+JA+KO+VI+ZH |
| 多言語(4言語) | 15分 | 8 | 20% | EN+KO+VI+ZH(JP除外) |
3.2 評価指標
精度指標:
- DER Full(collar=0.0秒): 最も厳密な指標、境界許容なし
- DER Fair(collar=0.25秒): 主要指標、250msの許容あり
- DER Forgiving(collar=0.25秒、オーバーラップ無視): 最も寛容
DERの構成要素:
- Miss Rate: システムが見逃した音声
- False Alarm Rate: 非音声を音声と誤判定
- Confusion Rate: 誤った話者に割り当てられた音声
4. 全体的な性能
4.1 精度比較
主な観察事項:
- NeMo NeuralはPyannoteより約55%高精度(DER: 0.081 vs 0.181)
- NeMo ClusteringもNeuralに近い性能(わずか27%の差)
- PyannoteのConfusion Rateは3.4倍高い
4.2 処理速度の比較
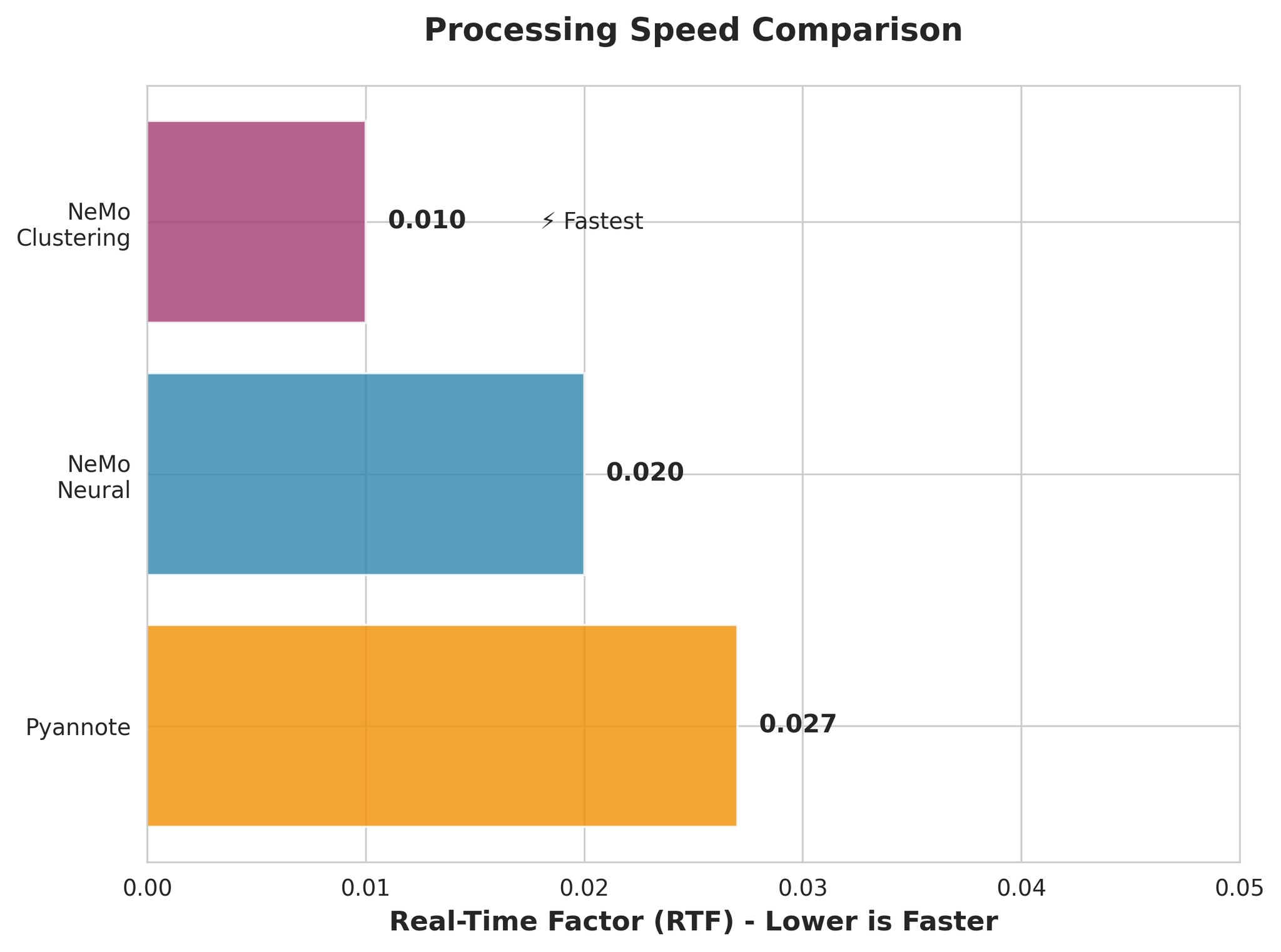
- NeMo Clusteringが最速(RTF 0.010)
- NeMo Neuralも非常に高速(RTF 0.020)
- 全モデルがリアルタイムより大幅に高速
4.3 精度と速度のトレードオフ
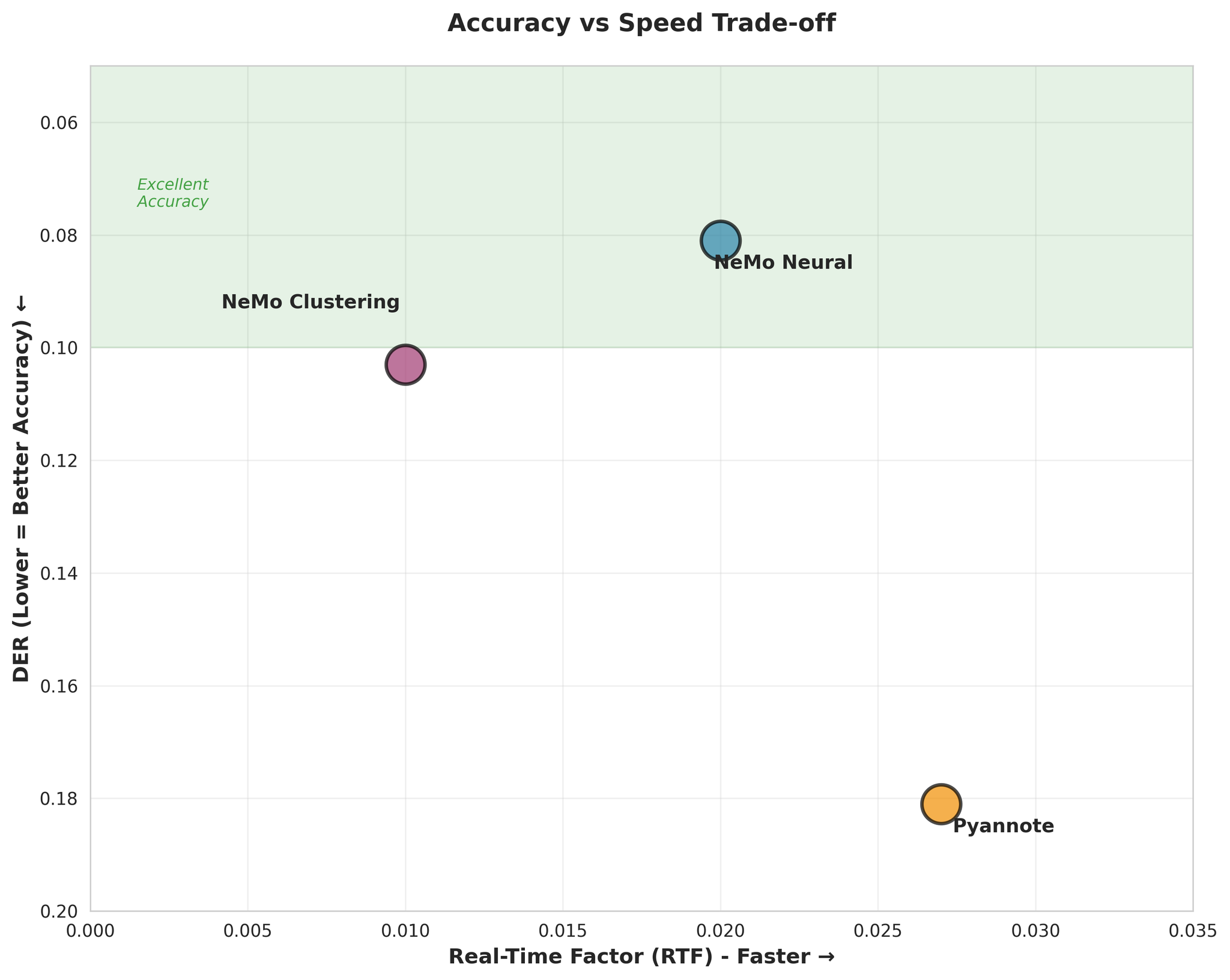
重要な発見: NeMo Neuralは最高精度と高速処理を両立しており、大半のユースケースで最適な選択です。
5. シナリオ別の結果
5.1 長時間音声(10分)
NeMo Neuralの言語別結果:
- EN: 0.019(優秀)
- JA: 0.157(英語の8.3倍困難)
- KO: 0.046
- VI: 0.037
- ZH: 0.053
- 平均: 0.062
5.2 超長時間音声(30分)
重要な発見 - 日本語は長時間コンテキストで改善:
- 10分音声: DER 0.157(英語の8.3倍困難)
- 30分音声: DER 0.067(英語の2.9倍困難)
長時間の音声はピッチアクセント言語のモデリングに有効な音響コンテキストを提供します。
5.3 高オーバーラップ(40%)
- NeMo NeuralとClusteringはほぼ同等の性能(DER: 0.114 vs 0.115)
- Pyannoteはより苦戦(DER: 0.202、NeMoより約77%悪い)
- 日本語が最も困難な言語(DER: 0.232)
6. 言語別分析
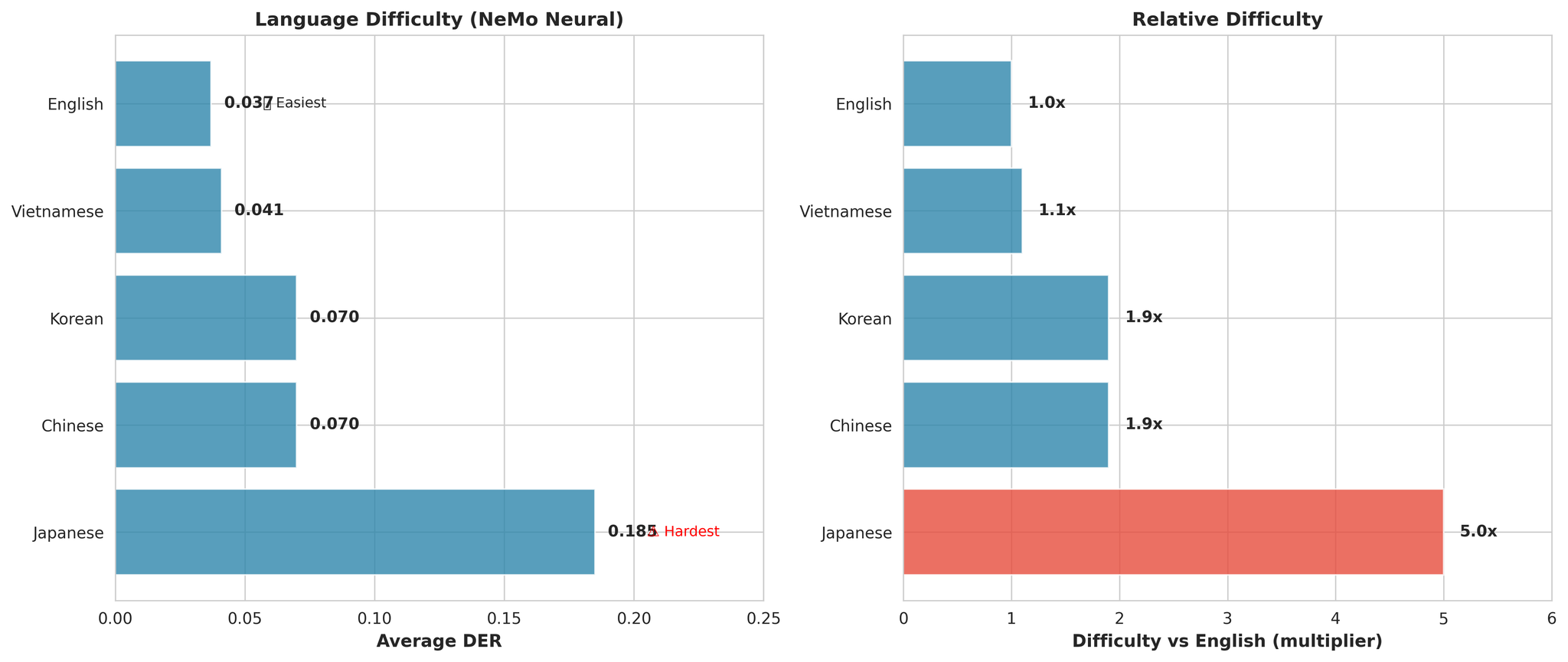
主な観察事項:
- 日本語は一貫して最も困難(英語の平均5.0倍困難)
- 英語が最も容易(DER: 0.037)
- ベトナム語は僅差で2位(英語の1.1倍のみ)
日本語が困難な理由
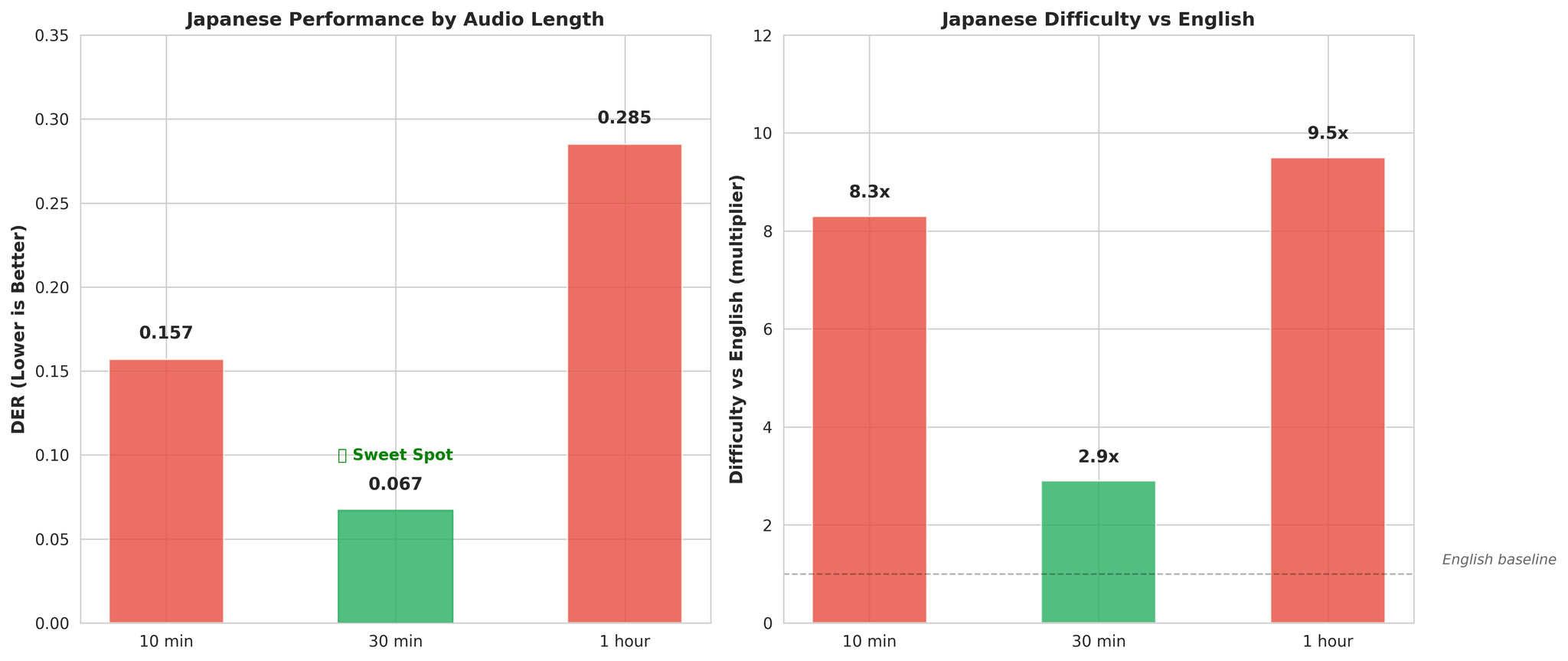
仮説:
- ピッチアクセント言語: ピッチが言語的意味を持つため、話者埋め込みが混乱
- 限られた音韻体系: 約100拍 vs 英語の数千の音素
- 短い音節持続時間: 発話ターンごとの時間的コンテキストが少ない
7. ニューラル方式 vs クラスタリング方式
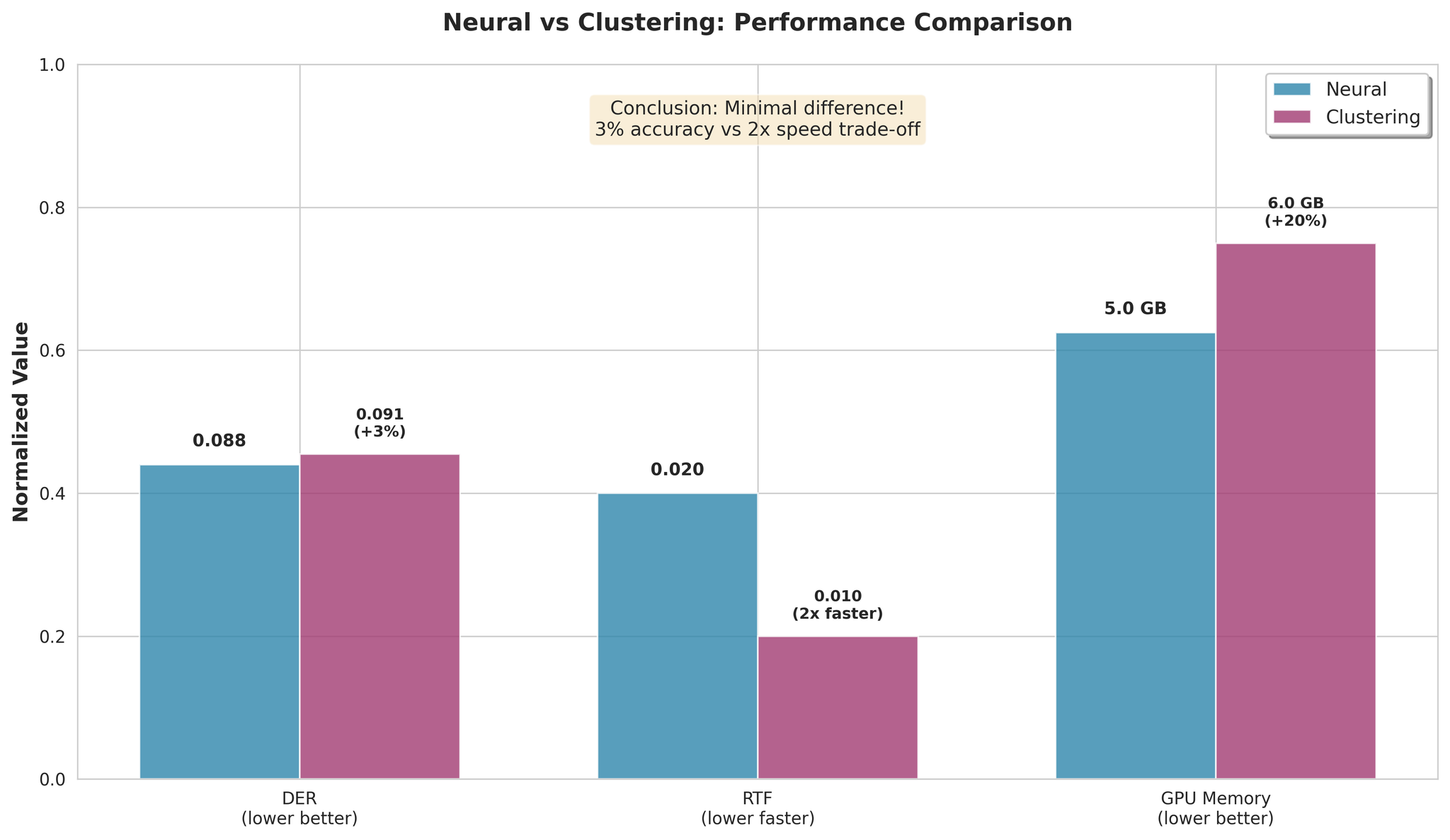
主な発見:
- Clusteringは平均でわずか3%劣る
- Clusteringは処理速度が2倍
- 速度と精度のトレードオフは最小限
推奨:
- 最高精度にはNeMo Neural
- 最高速度にはNeMo Clustering(2倍高速、3%の性能差)
8. 多言語性能
8.1 日本語の影響
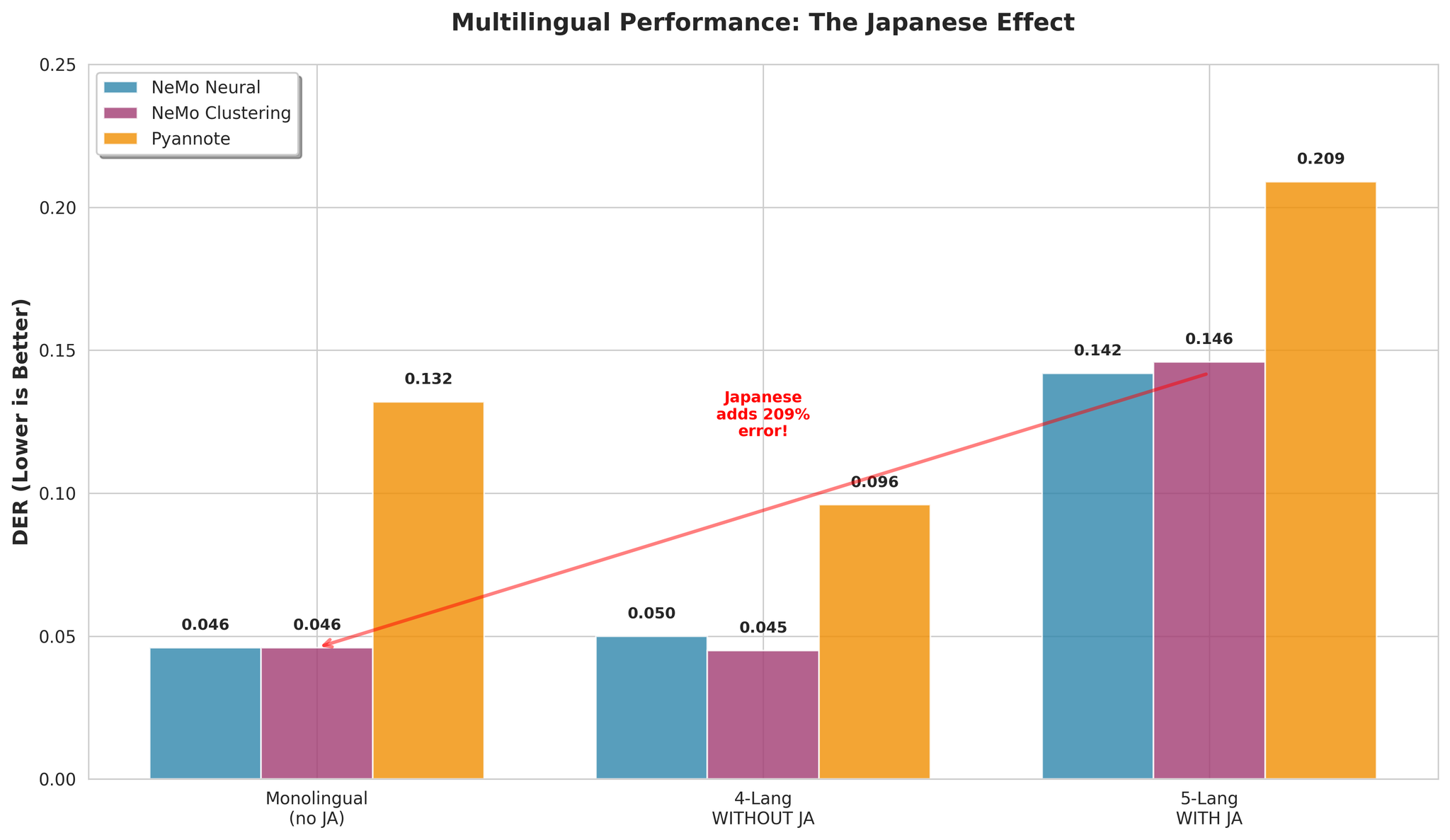
重要な知見: 日本語は多言語ダイアライゼーションを困難にする主要因です。
| 構成 | NeMo Neural DER |
|---|---|
| 日本語あり(5言語) | 0.142 |
| 日本語なし(4言語) | 0.050 |
8.2 エラー分析
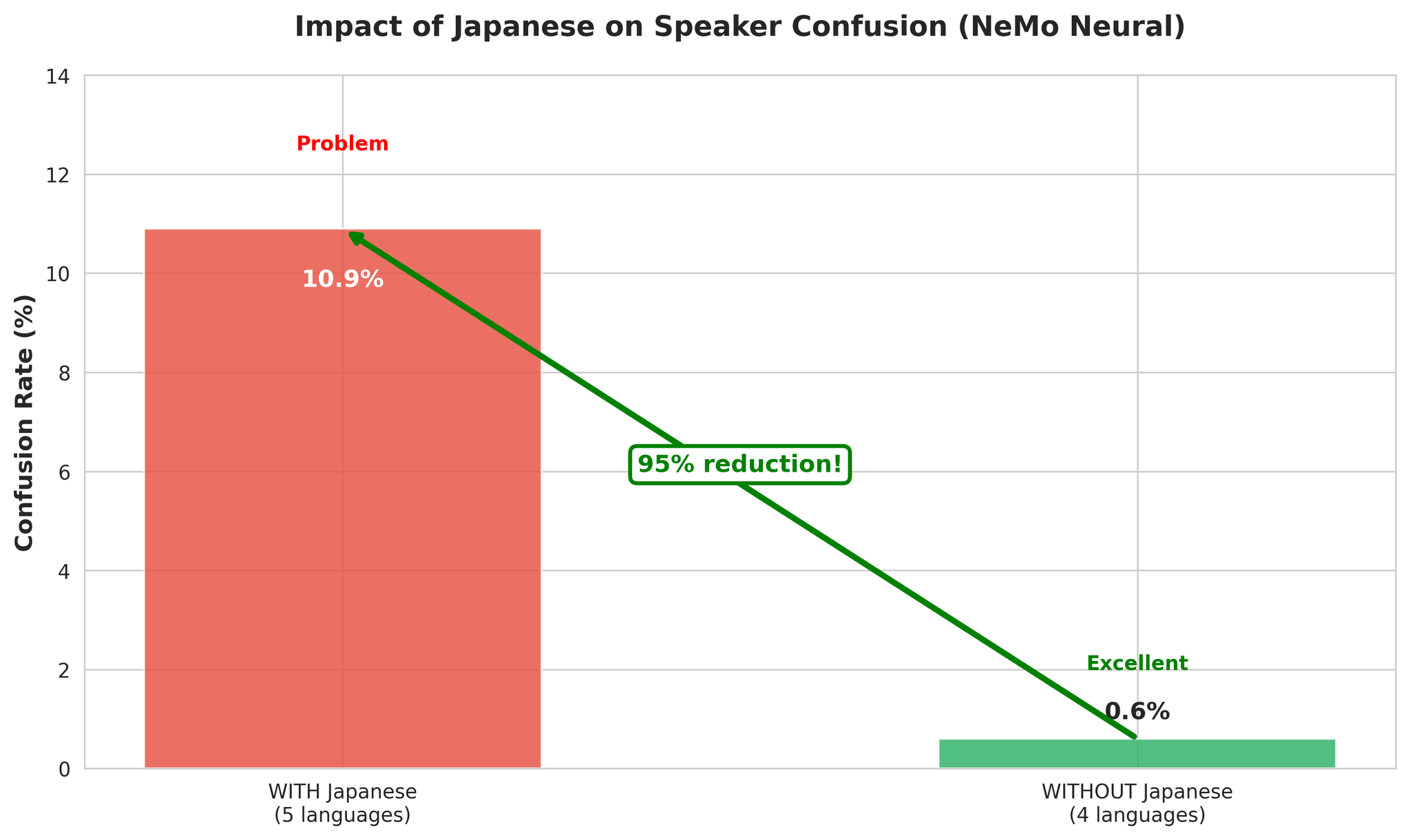
4言語多言語が好成績を収める理由:
- 音響的多様性がVADの音声境界検出を支援
- 言語の切り替えが自然なセグメント境界を提供
- 英語、韓国語、ベトナム語、中国語は互換性のある音響特徴を持つ
- 日本語のピッチアクセント特徴が言語間の話者混同を引き起こす
9. まとめ
主要な結論
NeMo Neuralが最適な選択:
- 最高精度: DER 0.081(平均)
- 高速処理: RTF 0.020(リアルタイムの50倍)
- 日本語を除く多言語で優秀: DER 0.050
重要な発見:
- 日本語は長時間コンテキストで大幅に改善(30分が最適)
- 日本語を含む多言語は困難(DER 0.142)だが対処可能
- MSDDニューラル精緻化はクラスタリングに対しわずかな改善(27%向上)
- 全モデルが高速で本番環境に対応可能
推奨
| ユースケース | モデル | 理由 |
|---|---|---|
| 最高精度 | NeMo Neural | DER 0.081 |
| 最高速度 | NeMo Clustering | 2倍高速 |
| 長時間音声(30分〜1時間) | NeMo Neural | 複雑さに対応 |
| 多言語(日本語なし) | NeMo Neural | DER 0.050 |
| 日本語(30分以上) | NeMo Neural | コンテキストが有効 |
デフォルトの選択: NeMo Neural - 最高精度と高速処理を両立。