AISHELL-3データセットとBert-VITS2フレームワークを活用した中国語音声合成システムの開発に関する研究レポートです。
概要
本研究では、Bert-VITS2フレームワークを用いた高速かつ自然な中国語(標準語)音声合成(TTS)システムの開発について報告します。会議シナリオに特化し、明瞭で表現力豊かな、文脈に適した音声生成を目指しています。
主要な成果:
- 比較モデル中で最低のWER 0.27を達成
- 音声の自然さに関するMOS 2.90を達成
- 最大22秒の音声合成に成功
- AISHELL-3データセット(85時間、218話者)で学習
1. はじめに
音声合成(TTS)とは
音声合成(TTS)技術は、書かれたテキストを自然な音声に変換する技術です。最新のTTSシステムはディープラーニングを活用して、ますます自然で表現力のある音声を生成しています。主な応用分野は以下の通りです。
- 音声アシスタント
- アクセシブルな読み上げソリューション
- ナビゲーションシステム
- 自動カスタマーサービス
なぜ中国語か
中国語(標準語)は10億人以上の話者を持つ世界最大の言語です。しかし、声調言語としての特性と複雑な言語構造により、TTSにとって独特の課題を呈しています。
Bert-VITS2とは
Bert-VITS2は、事前学習済み言語モデルと先進的な音声合成技術を組み合わせたシステムです。
- BERT統合: 意味的・文脈的なニュアンスの深い理解
- GANスタイルの学習: 敵対的学習により高度にリアルな音声を生成
- VITS2ベース: 最先端の音声合成アーキテクチャ
2. 方法論
2.1 データセットの選定
本研究ではAISHELL-3を選定しました。
- 85時間の音声データ
- 218人の話者
- 話者あたり平均約30分
- 高品質なトランスクリプション
注: 当初Alimeeting(118.75時間)で実験を行いましたが、トランスクリプション品質の低さと話者あたりの音声時間の短さにより、無音の音声が生成されました。
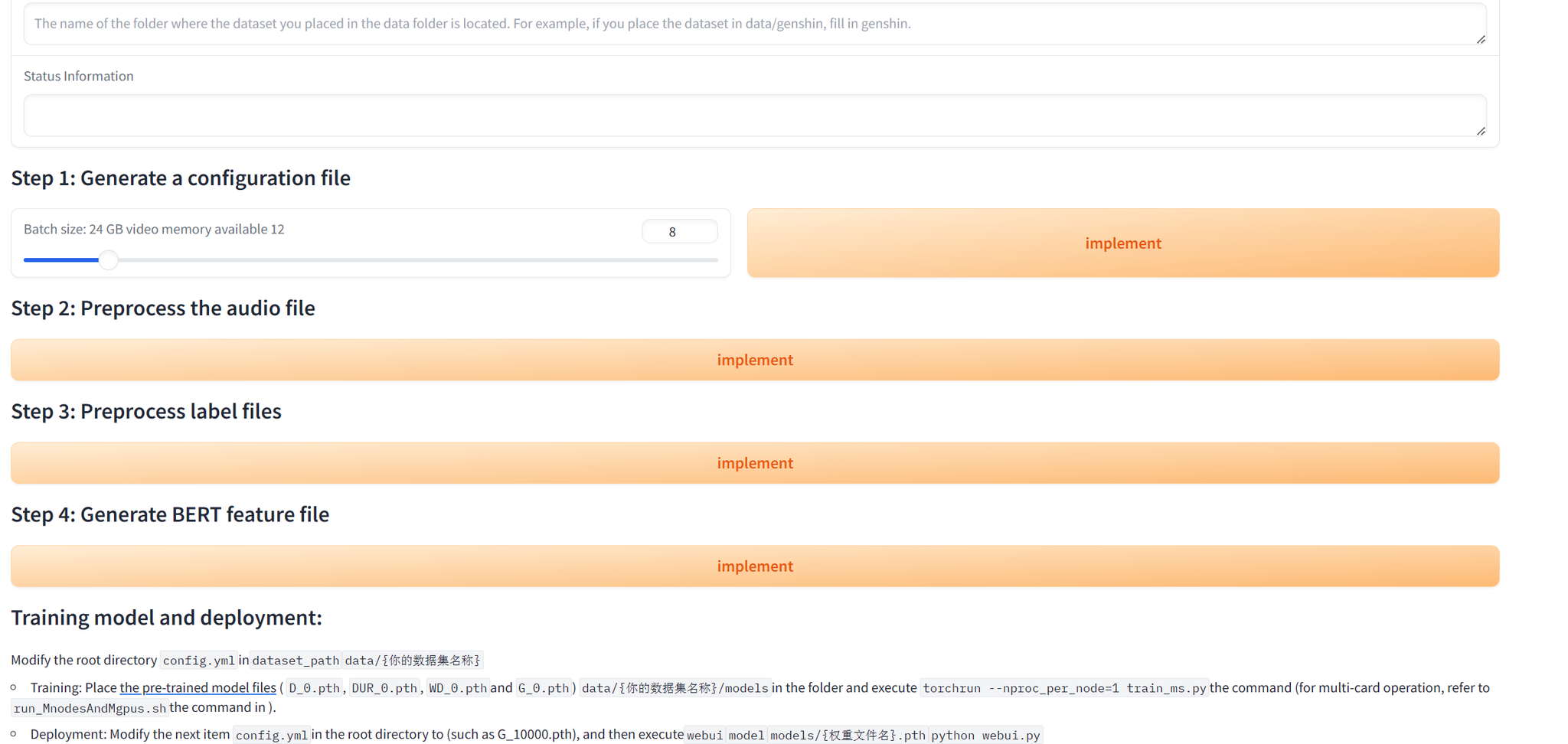
2.2 モデルアーキテクチャ
Bert-VITS2フレームワークは4つの主要コンポーネントで構成されています。
| コンポーネント | 機能 |
|---|---|
| TextEncoder | 事前学習済みBERTを用いて入力テキストを処理し意味を理解 |
| DurationPredictor | 確率的な変動を持つ音素継続時間を推定 |
| Flow | 正規化フローを用いてピッチとエネルギーをモデリング |
| Decoder | 最終的な音声波形を合成 |
2.3 学習プロセス
損失関数
- Reconstruction Loss: 生成音声を正解音声に一致させる
- Duration Loss: 音素継続時間の予測誤差を最小化
- Adversarial Loss: リアルな音声生成を促進
- Feature Matching Loss: 中間特徴量を整合
モード崩壊の緩和策
- 判別器の安定化のためのGradient Penalty
- 生成器と判別器のSpectral Normalization
- 複雑さを段階的に上げるProgressive Training
ハイパーパラメータ
| |
ヒント: 学習はRTX 4090 GPU 1台でbfloat16精度を使用して行いました。
3. 結果と考察
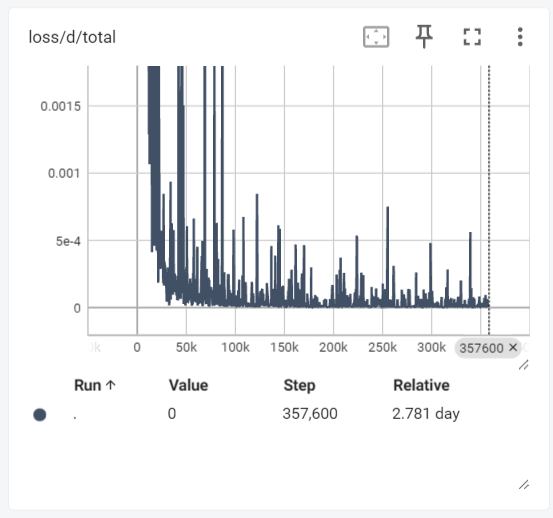
学習の推移
初期学習ではモード崩壊(無音音声の生成)が発生しました。調整後:
- 判別器の損失が安定
- 生成器の損失が明確な下降傾向を示す
- 学習中にWERが約0.5から約0.2に低下
他モデルとの比較
| モデル | WER | MOS |
|---|---|---|
| 本モデル(Bert-VITS2) | 0.27 | 2.90 |
| myshell-ai/MeloTTS-Chinese | 5.62 | 3.04 |
| fish-speech (GPT) w/o ref | 0.49 | 3.57 |
注: 本モデルは最低WERを達成し、正確な音声生成を示しています。ただし、MOS(自然さ)については、大幅に多いパラメータを持つfish-speechと比較すると改善の余地があります。
生成例
以下のような音声合成に成功しました。
- 短いフレーズ(2〜10秒)
- 長時間音声(22秒)- 学習データの範囲外
制限事項
コードスイッチング: 複数言語が混在するテキスト(例: 中国語に英語の専門用語「Speech processing」が含まれる場合)には対応できません。
4. まとめと今後の展望
達成事項
- 中国語TTSのためのBert-VITS2のファインチューニングに成功
- 比較モデル中で最低WERを達成
- GAN学習の課題を緩和する手法を習得
- さまざまな長さの明瞭で認識可能な音声を生成
今後の方向性
- MOSスコア向上のための追加学習ステップ
- コードスイッチングの制限への対応
- 追加の話者やドメインへの拡張
5. 参考文献
- Ren, Y., et al. (2019). “Fastspeech: Fast, robust and controllable text to speech.” NeurIPS.
- Wang, Y., et al. (2017). “Tacotron: Towards end-to-end speech synthesis.” Interspeech.
- Kim, J., et al. (2021). “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech.” ICML.
- Kong, J., et al. (2023). “VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech.” INTERSPEECH.
- Shi, Y., et al. (2020). “AISHELL-3: A Multi-speaker Mandarin TTS Corpus and the Baselines.” ArXiv.
- Saeki, T., et al. (2022). “UTMOS: UTokyo-SaruLab System for VoiceMOS Challenge 2022.” INTERSPEECH.
リソース
- Bert-VITS2リポジトリ: github.com/fishaudio/Bert-VITS2
- AISHELL-3データセット: openslr.org/93