Whisperのファインチューニング、話者ダイアライゼーション、複数ASRモデルの比較評価に関する包括的な研究レポートです。
著者: Linchuan Du 所属: The University of British Columbia 数学科 日付: 2023年8月
概要
自動音声認識(ASR)は、音声テキスト変換(STT)とも呼ばれ、ディープラーニング技術を用いて音声を含む音声データをテキストに変換する技術です。大規模言語モデル(LLM)は人間の脳のように単語やフレーズを処理し、テキストデータの理解と生成が可能です。LLMは通常、数百万のパラメータを持ち、多様なデータセットで事前学習されています。ASR用のLLMは、特徴抽出とトークン化によって音声入力を所望の形式に変換します。
理想的な性能を持つASR LLMをカスタマイズするため、OpenAIが開発したWhisperのファインチューニング手順をまずGoogle Colaboratoryでテストしました。その後、学習を高速化しGPU可用性の制限を回避するため、Windows OS上のGPU搭載環境に移行しました。音声品質やトランスクリプトの正確性などに基づいてデータの信頼性を調査し、データ前処理やハイパーパラメータチューニングによるモデルの改善・最適化を行いました。通常のファインチューニングでGPUメモリ問題を解決できない場合には、LoRAを用いたパラメータ効率的ファインチューニング(PEFT)を使用し、大部分のパラメータを凍結してメモリ使用量を削減しつつ、性能の低下を最小限に抑えました。
また、Neural Speaker Diarizationを用いたWhisperの複数話者対応の可能性を調査しました。Pyannoteとの統合をパイプラインおよびWhisperXを用いて実装しました。WhisperXはワードレベルのタイムスタンプや音声活動検出(VAD)などの機能を備えています。
Whisper以外にも、Meta AIのMMS、PaddleSpeech、SpeechBrain、ESPNetなどのASR機能を持つモデルを導入し、Whisperのベースラインと比較しました。中国語データセットを用いてCER指標で比較を行いました。さらに、Azure AIのCustom Speechによるリアルタイム STT機能との性能比較(主に中国語)も実施しました。
概観
本研究で扱うトピック:
- 環境構築 - Google Colab、Anaconda、VS Code、CUDA GPU
- 音声データソース - Hugging Face、OpenSLRデータセット
- Whisperファインチューニング - ファインチューニング、LoRAによるPEFT、結果
- 話者ダイアライゼーション - Pyannote.audio、WhisperX
- その他のモデル - Meta MMS、PaddleSpeech、SpeechBrain、ESPnet
- Azure Speech Studio - Custom Speechの学習とデプロイ
1. 環境構築
a. Google Colaboratory
Google Colaboratoryは、限定的な無料GPU・TPU計算リソースを提供するホスト型Jupyter Notebookサービスです。ipynb形式でPythonスクリプトの編集・実行が可能です。
Googleアカウントでログインし、右上の「共有」からスクリプトを共有でき、GitHubアカウントとの連携も可能です。
Colab上での環境構築手順:
- Runtime タブ → Change Runtime でGPUを有効化
- pipなどのパッケージインストーラーで必要な依存関係をインストール
| |
b. Anaconda
ローカルPCでも環境構築が可能です。Anacondaはデータサイエンス分野で広く使われているディストリビューションプラットフォームで、Pythonでのデータ分析や機械学習モデル構築をサポートします。環境・パッケージマネージャーのCondaが含まれています。
Anacondaでの環境構築手順:
- Anacondaをインストールし、PATH環境変数に追加
- コマンドプロンプトを起動してbase環境に入る(例: Windows)
| |
- 新しいConda環境を作成
| |
- 必要に応じてConda環境をactivate/deactivate
| |
- PyPIまたはCondaパッケージマネージャーで依存関係をインストール
| |
ヒント: その他のCondaコマンドは https://conda.io/projects/conda/en/latest/commands を参照してください。
c. Visual Studio Code
Visual Studio Code(VS Code)は、Windows、macOS、Linuxに対応した高機能なソースコードエディタです。デバッグ、統合ターミナルでの実行、拡張機能による機能追加、Gitによるバージョン管理をサポートしています。
VS Codeでの環境構築手順:
- EXPLORERでフォルダを開き、ファイルを作成
- 右下で必要な環境を選択し、IPythonカーネルでインタラクティブウィンドウを使用するか、コマンドでPythonファイルを実行
| |
- ipynb形式(Jupyter Notebook)も使用可能
- 左パネルのGitアイコンでソースコード管理
ヒント: 環境のパッケージを更新した場合は、VS Codeの再起動が必要です。
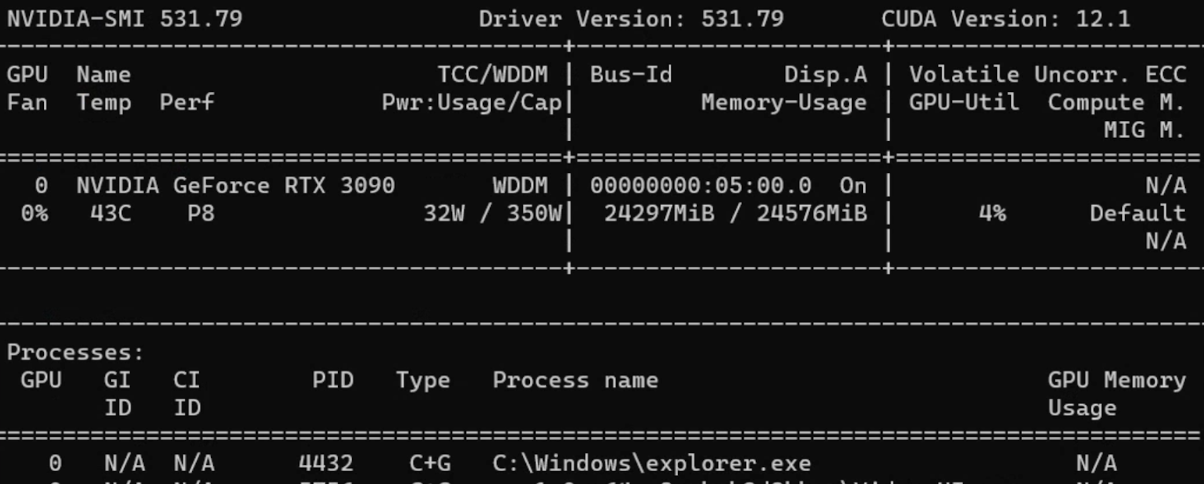
d. CUDA GPU
CUDA(Compute Unified Device Architecture)は、NVIDIAが開発した並列計算プラットフォームおよびAPIです。NVIDIA GPUを様々な計算タスクに活用できます。
CUDA GPUの使用手順:
- CUDA Toolkitをインストール
- コマンドプロンプトで情報を確認
| |
CUDA Toolkitのセットアップ後、PyTorchからGPU対応バージョンをダウンロードします。
ヒント: 旧バージョンのPyTorchが必要な場合は、Previous PyTorch Versionsで正しいコマンドを確認してください。
Pythonで直接バージョンを確認できます。
| |
2. 音声データソース
a. Hugging Face
Hugging Faceは、自然言語処理(NLP)と人工知能に特化した企業およびオープンソースプラットフォームです。
アカウントを作成することで、公開モデルの利用やカスタムモデルのアップロードが可能です。READおよびWRITEトークンは https://huggingface.co/settings/tokens で作成できます。
代表的なASR LLMとその情報:
| モデル | パラメータ数 | 対応言語 | タスク | 構造 |
|---|---|---|---|---|
| OpenAI Whisper | large-v2 1550M | ほとんどの言語 | マルチタスク | Transformer encoder-decoder Regularized |
| OpenAI Whisper | large 1550M | ほとんどの言語 | マルチタスク | Transformer encoder-decoder |
| OpenAI Whisper | medium 769M | ほとんどの言語 | マルチタスク | Transformer encoder-decoder |
| OpenAI Whisper | small 244M | ほとんどの言語 | マルチタスク | Transformer encoder-decoder |
| guillaumekln faster-whisper | large-v2 | ほとんどの言語 | マルチタスク | CTranslate2 |
| facebook wav2vec2 | large-960h-lv60-self | 英語 | 書き起こし | Wav2Vec2CTC decoder |
| facebook wav2vec2 | base-960h 94.4M | 英語 | 書き起こし | Wav2Vec2CTC decoder |
| facebook mms | 1b-all 965M | ほとんどの言語 | マルチタスク | Wav2Vec2CTC decoder |
代表的な音声データセット:
| データセット | 時間/サイズ | 対応言語 |
|---|---|---|
| mozilla-foundation common_voice_13_0 | 17689検証済み時間 | 108言語 |
| google fleurs | 言語あたり約12時間 | 102言語 |
| LIUM tedlium | 3リリースで118〜452時間 | 英語 |
| librispeech_asr | 約1000時間 | 英語 |
| speechcolab gigaspeech | 10000時間 | 英語 |
| PolyAI minds14 | 8.17k行 | 14言語 |
注意: PolyAI/minds14は主にインテント検出タスク向けであり、ASR目的には適していません。
b. Open SLR
Open SLRは、圧縮ファイル形式の音声・言語リソースをホストする便利なWebサイトです。Resourcesタブで各種音声データセットの概要を確認できます。
中国語ASR用音声データセット:
| データセット | 時間(サイズ) | 話者数 | トランスクリプト精度 |
|---|---|---|---|
| Aishell-1 (SLR33) | 178時間 | 400 | 95%以上 |
| Free ST (SLR38) | 100時間以上 | 855 | / |
| aidatatang_200zh (SLR62) | 200時間 | 600 | 98%以上 |
| MAGICDATA (SLR68) | 755時間 | 1080 | 98%以上 |
3. Whisperモデルのファインチューニング
Whisperは、2022年9月にOpenAIがリリースしたASRシステムです。680,000時間の多言語・マルチタスク教師データで学習されており、多言語の書き起こしと翻訳が可能です。アーキテクチャはエンコーダ・デコーダ型Transformerです。
音声は30秒のチャンクに分割され、log-Melスペクトログラムに変換されてエンコーダに入力されます。
参考資料:
a. Colabでのファインチューニング
ステップ1: Hugging Faceトークンでログインしてデータセットのダウンロードを有効化
| |
ステップ2: load_datasetでデータセットを読み込み
ヒント: Hugging Face上で特定のデータセットへのアクセス許可が必要な場合があります。
ステップ3: Whisperにデータを供給するためのデータ前処理:
- カラムの操作(
remove_columns、cast_columnなど) - トランスクリプトの正規化(大文字/小文字、句読点、特殊トークン)
- Datasetsライブラリを使用してサンプリングレートを16kに変更
- transformersライブラリから事前学習済み特徴抽出器とトークナイザーを読み込み
| |
ヒント: AutoProcessorはプロセッサの種類を自動検出します。
トークナイザーでは通常、対象言語とタスクを指定します。
| |
ステップ4: Data Collatorの定義(Sequence to Sequenceのラベルパディング付き)
| |
ステップ5: 評価指標(WER)の読み込み
| |
ヒント: 英語やヨーロッパ系言語ではWER(Word Error Rate)が一般的な書き起こし精度の評価指標です。
WERの計算式: WER = (置換数 + 削除数 + 挿入数) / 参照文の総単語数
ステップ6: メトリクス計算の設計
| |
ステップ7: 条件付き生成モデルの読み込みと設定
| |
ステップ8: Seq2SeqTrainingArgumentsでハイパーパラメータを定義
| |
ステップ9: trainer.train()で学習開始
| |
CUDA Out of Memory(OOM)エラーへの対処:
- 最優先: バッチサイズを削減(gradient accumulationと組み合わせ)
- Gradient checkpointing: 計算時間をわずかに増加させてメモリ使用量を大幅に削減
- 混合精度学習: 学習の安定性を維持しつつメモリ使用量を削減
- GPUキャッシュのクリア:
| |
ヒント: すべての方法が失敗した場合、より小さいモデルサイズに変更することが最後の手段です。
b. データ前処理
Hugging Faceデータセット
load_dataset関数でデータセットを読み込みます。
| |
ヒント: ディスク容量が限られている場合や全データセットのダウンロードが不要な場合は
streaming=Trueを使用してください。
Whisperアーキテクチャが要求する16kHzにサンプリングレートを変更します。
| |
トランスクリプトのクリーニング
| |
| |
c. ファインチューニング結果
略語:
- lr = learning rate, wd = weight decay, ws = warmup steps
- ms = max steps, #e = number of epochs
- es = evaluation strategy, ml = max length
- tbz = train batch size, ebz = eval batch size
- #ts = train sample size, #es = eval sample size
| データセット/サイズ/分割 | モデル/言語/タスク | ハイパーパラメータ | 結果 |
|---|---|---|---|
| common_voice_11_0 #ts=100, #es=100 train/test | Whisper small Hindi Transcribe | lr=1e-5, wd=0, ws=5, ms=40, es=steps, ml=225, tbz=4, ebz=8 | WER: 67.442% |
| common_voice_11_0 #ts=500, #es=500 train+validation/test | Whisper small Hindi Transcribe | lr=1e-5, wd=0, ws=0, ms=60, es=steps, ml=50, tbz=16, ebz=8 | WER: 62.207% |
| common_voice #ts=3500, #es=500 train+validated/validation | Whisper small Japanese Transcribe | lr=1e-6, wd=0, ws=50, ms=3500, es=steps, ml=200, tbz=16, ebz=8 | WER: 2.4% |
| librispeech_asr #ts=750, #es=250 train.100/validation | Whisper medium English Transcribe | lr=1e-5, wd=0.01, ws=10, ms=750, es=steps, ml=80, tbz=1, ebz=1 | WER: 13.095% |
注: 日本語は文字ベースの言語であるため、Character Error Rate(CER)がより適切な評価指標です。
d. LoRAによるPEFT
パラメータ効率的ファインチューニング(PEFT)は、事前学習済みLLMの大部分のパラメータを凍結しつつ少数のパラメータのみをファインチューニングすることで、計算コストとストレージコストを大幅に削減します。
**LoRA(Low Rank Adaptation)**は、事前学習済みモデルの重みを低ランク行列に分解し、ファインチューニングが必要なパラメータ数を大幅に削減します。
| |
PEFTの学習パラメータ:
| |
PEFT結果:
| データセット/サイズ/分割 | モデル/言語/タスク | ハイパーパラメータ | 結果 |
|---|---|---|---|
| common_voice_13_0 #ts=1000, #es=100 train+validation/test | Whisper medium Japanese Transcribe | lr=1e-3, wd=0, ws=50, #e=3, es=steps, ml=128, tbz=8, ebz=8 | WER: 73%, NormWER: 70.186% |
| common_voice_13_0 #ts=100, #es=30 train+validation/test | Whisper large-v2 Vietnamese Transcribe | lr=1e-4, wd=0.01, ws=0, #e=3, es=steps, ml=150, tbz=8, ebz=8 | WER: 26.577%, NormWER: 22.523% |
ヒント: PEFTの参考資料:
e. ロス曲線の可視化
| |
確認すべきパターン:
- 過学習: 学習ロスは低いが検証ロスが高い
- 学習不足: 学習ロスと検証ロスの両方が高い
- 滑らかさ: 滑らかな曲線は安定した学習を示す
- ロスの停滞: モデルがデータからこれ以上学習できない状態
f. ベースライン結果
| データセット/分割/サイズ | モデル/タスク | 結果 |
|---|---|---|
| distil-whisper/tedlium-long-form test | Whisper medium baseline en→en | WER: 28.418% |
| distil-whisper/tedlium-long-form validation | Whisper large-v2 baseline en→en | WER: 26.671% |
| librispeech_asr clean test | Whisper large-v2 baseline en→en | WER: 4.746% |
| Aishell S0770 test #353 | Whisper large-v2 baseline zh-CN→zh-CN | CER: 8.595% |
| Aishell S0768 test #367 | Whisper large-v2 baseline zh-CN→zh-CN | CER: 12.379% |
| MagicData 38_5837 test #585 | Whisper large-v2 baseline zh-CN→zh-CN | CER: 21.750% |
4. 話者ダイアライゼーション
話者ダイアライゼーションは、音声データを異なる話者に対応するセグメントに分割する技術です。音声ストリーム中の個々の話者を識別・区別することが目的です。
a. Pyannote.audio
Pyannote.audioは、話者ダイアライゼーション、音声活動検出、発話ターン分割のためのオープンソースツールキットです。
Pyannote.audioとWhisperの併用方法:
| |
| |
| |
b. WhisperX
WhisperXはWhisper、音素ベースモデル(Wav2Vec2)、Pyannote.audioを統合したツールです。Whisper large-v2と比較してリアルタイム音声認識で70倍高速と謳っており、ワードレベルのタイムスタンプやVAD機能付きの話者ダイアライゼーションを提供します。
| |
| |
ヒント: それぞれの利点:
- WhisperX: マルチスピーカーシナリオ、VAD、追加の音素モデル、ローカル音声の扱いやすさ
- Whisper Pipeline: より多くの言語対応、柔軟なチャンク長(30秒以下)、HFデータセットの扱いやすさ
WhisperXの結果:
| データセット | モデル/タスク/計算タイプ | 結果 |
|---|---|---|
| TED LIUM 1st release SLR7 test | WhisperX medium en→en int8 | WER: 37.041% |
| TED LIUM 1st release SLR7 test | WhisperX large-v2 en→en int8 | WER: 36.917% |
| distil-whisper/tedlium-long-form validation | WhisperX large-v2 en→en int8 batch_size=1 | WER: 24.651% |
| distil-whisper/tedlium-long-form validation | WhisperX medium en→en int8 batch_size=1 | WER: 24.353% |
| AISHELL-4 selected audio file | WhisperX manual check | CER: 15.6%~24.658% |
5. その他のモデル
a. Meta MMS
Meta AIのMassively Multilingual Speech(MMS)プロジェクトは、音声技術の対応言語を約100言語から1,100言語以上に拡大しました。
| |
b. PaddleSpeech
PaddleSpeechは、PaddlePaddleプラットフォーム上の中国語オープンソースツールキットです。DeepSpeech2、Conformer、U2(Unified Streaming and Non-streaming)などのアーキテクチャに対応しています。詳細は機能一覧をご覧ください。
| |
| |
ヒント: Linux上でのASR学習チュートリアル: asr1
c. SpeechBrain
SpeechBrainは、モントリオール大学が開発した対話型AIのオープンソースツールキットです。
| |
| |
d. ESPnet
ESPnetは、音声認識、テキスト音声変換、音声翻訳、話者ダイアライゼーションをカバーするエンドツーエンド音声処理ツールキットです。
| |
| |
e. ベースライン結果の比較
英語:
| データセット | モデル/手法 | WER |
|---|---|---|
| librispeech_asr clean | Meta MMS mms-1b-all | 4.331% |
| common_voice_13_0 #1000 | Meta MMS mms-1b-all | 23.963% |
中国語:
| データセット | モデル/手法 | CER |
|---|---|---|
| Aishell S0770 #353 | PaddleSpeech Default (conformer_u2pp_online_wenetspeech) | 4.062% |
| Aishell S0768 #367 | SpeechBrain wav2vec2-transformer-aishell | 8.436% |
| Aishell S0768 #367 | Meta MMS mms-1b-all | 34.241% |
| MagicData 4 speakers #2372 | PaddleSpeech conformer-wenetspeech | 9.79% |
| MagicData 4 speakers #2372 | SpeechBrain wav2vec2-ctc-aishell | 15.911% |
| MagicData 4 speakers #2372 | Whisper large-v2 baseline | 24.747% |
主要な知見: 中国語の推論においてPaddleSpeechはWhisperよりも優れた性能を示しましたが、Meta MMSの中国語書き起こし結果はWhisperよりも劣っていました。
6. Azure Speech Studio
Azure AI Speech Servicesは、Microsoft Azureが提供するクラウドベースの音声関連サービス群です。Speech StudioのCustom Speechプロジェクトは、さまざまな言語で作成できます。
a. データセットのアップロード
学習・テストデータセットのアップロードには3つの方法があります:
- Speech Studio(直接アップロード)
- REST API
- CLIの使用
Azure Blob Storage:
| |
音声フォーマット要件:
- 形式: WAV
- サンプリングレート: 8kHzまたは16kHz
- チャンネル: モノラル(シングルチャンネル)
- アーカイブ: ZIP形式、2GB以内、10,000ファイル以内
b. モデルの学習とデプロイ
| |
c. Azureの結果
| テストデータセット | 学習データセット | エラー率(カスタム / ベースライン) |
|---|---|---|
| MagicData 9452 11:27:39s | Aishell 12時間以上 | 4.69% / 4.24% |
| MagicData 9452 11:27:39s | Aishell+Minds14 32時間以上: 1時間以上 | 4.67% / 4.23% |
| MagicData+Aishell+CV13 8721 11:45:52s | Aishell+CV13 8時間以上: 7時間以上 | 2.51% / 3.70% |
| MagicData+Aishell+CV13 8721 11:45:52s | Aishell+CV13+Fleurs 8時間以上: 7時間以上: 9時間以上 | 2.48% / 3.70% |
注: 最良のAzureモデルはAISHELL-1、mozilla-foundation/common_voice_13_0、google/fleursで学習され、エラー率2.48%を達成しました。
7. 今後の展望
主要な知見と今後の方向性:
- データソース: 高品質なトランスクリプト付きの中国語音声データは英語と比較して入手が困難
- ハードウェアの制約: マルチGPU学習やより高性能なGPU(NVIDIA 40シリーズ)を使用することで、大規模モデルでさらに良い結果が期待できる
- LoRA設定: 異なるLoRAパラメータがPEFTモデルの性能に与える影響のさらなる調査
- 話者ダイアライゼーション: Pyannote.audioとWhisperの統合は有望だが、現時点ではマルチスピーカー会議シナリオでの精度は十分ではない
- Azure Speech Services: 高品質な音声とワードレベルの正確なトランスクリプトの維持が重要。品質の低い音声ファイルのフィルタリングがモデル性能を向上させる
8. 参考文献
- Anaconda, Inc. (2017). Command reference - conda documentation. conda.io/projects/conda/en/latest/commands
- OpenAI (2022, September 21). Introducing Whisper. openai.com/research/whisper
- Radford, A., Kim, J.W., Xu, T., Brockman, G., McLeavey, C., & Sutskever, I. (2022). Robust Speech Recognition via Large-Scale Weak Supervision.
- Gandhi, S. (2022, November 3). Fine-Tune Whisper for Multilingual ASR with Transformers. huggingface.co/blog/fine-tune-whisper
- The Linux Foundation (2023). Previous PyTorch Versions. pytorch.org/get-started/previous-versions
- Hugging Face, Inc. (2023). Hugging Face Documentations. huggingface.co/docs
- Srivastav, V. (2023). fast-whisper-finetuning. github.com/Vaibhavs10/fast-whisper-finetuning
- Mangrulkar, S., & Paul, S. (2023). Parameter-Efficient Fine-Tuning Using PEFT. huggingface.co/blog/peft
- Bredin, H., et al. (2020). pyannote.audio: neural building blocks for speaker diarization. ICASSP 2020.
- Bain, M., Huh, J., Han, T., & Zisserman, A. (2023). WhisperX: Time-Accurate Speech Transcription of Long-Form Audio. INTERSPEECH 2023.
- Meta AI (2023, May 22). Introducing speech-to-text, text-to-speech, and more for 1,100+ languages. ai.meta.com/blog/multilingual-model-speech-recognition
- Pratap, V., et al. (2023). Scaling Speech Technology to 1,000+ Languages. arXiv.
- Zhang, H. L. (2022). PaddleSpeech: An Easy-to-Use All-in-One Speech Toolkit. NAACL 2022.
- Ravanelli, M., et al. (2021). SpeechBrain: A General-Purpose Speech Toolkit.
- Gao, D., et al. (2022). EURO: ESPnet Unsupervised ASR Open-source Toolkit. arXiv:2211.17196.
- ESPnet (2021). espnet_model_zoo. github.com/espnet/espnet_model_zoo
- Microsoft (2023). Custom Speech overview - Azure AI Services. learn.microsoft.com/en-us/azure/ai-services/speech-service/custom-speech-overview
- Microsoft (2023). Speech service documentation. learn.microsoft.com/en-us/azure/ai-services/speech-service/