Open-source cross-platform mobile app for fully offline speech translation — combining on-device ASR (SenseVoice), neural machine translation, and TTS on iOS and Android with system audio capture
Source Code:
- ios-android-offline-speech-translation — Cross-platform offline speech translation app with ASR, translation, TTS, and system audio capture for iOS and Android (Apache 2.0)
Abstract
We present an open-source cross-platform mobile application that performs fully offline speech translation on iOS and Android. The app combines on-device automatic speech recognition (SenseVoice Small via sherpa-onnx), neural machine translation (Apple Translation / Google ML Kit), and text-to-speech synthesis into a unified pipeline. Both platforms support microphone and system audio capture — enabling translation of audio from other apps (video calls, media, etc.) without cloud connectivity, subject to platform capture restrictions. On-device ASR achieves 23.6 tok/s on iPad Pro (A12X) and 33.6 tok/s on Samsung Galaxy S10 (RTF < 0.1). Translation and TTS stages use platform-native engines and were not individually benchmarked in this release.
Motivation
Can a complete speech translation pipeline — ASR, machine translation, and TTS — run reliably offline on consumer phones from 2018–2019? Most on-device AI research benchmarks individual models in isolation, but a real application must chain multiple stages together, manage system audio capture across platform sandboxing restrictions, and handle the full lifecycle (persistence, export, background processing).
This project tests the system feasibility question: whether the full pipeline works end-to-end on real consumer hardware without network connectivity. The app is open-source so developers can evaluate the architecture directly.
App Overview
iOS
| Home | Transcription + Translation | Demo |
|---|---|---|
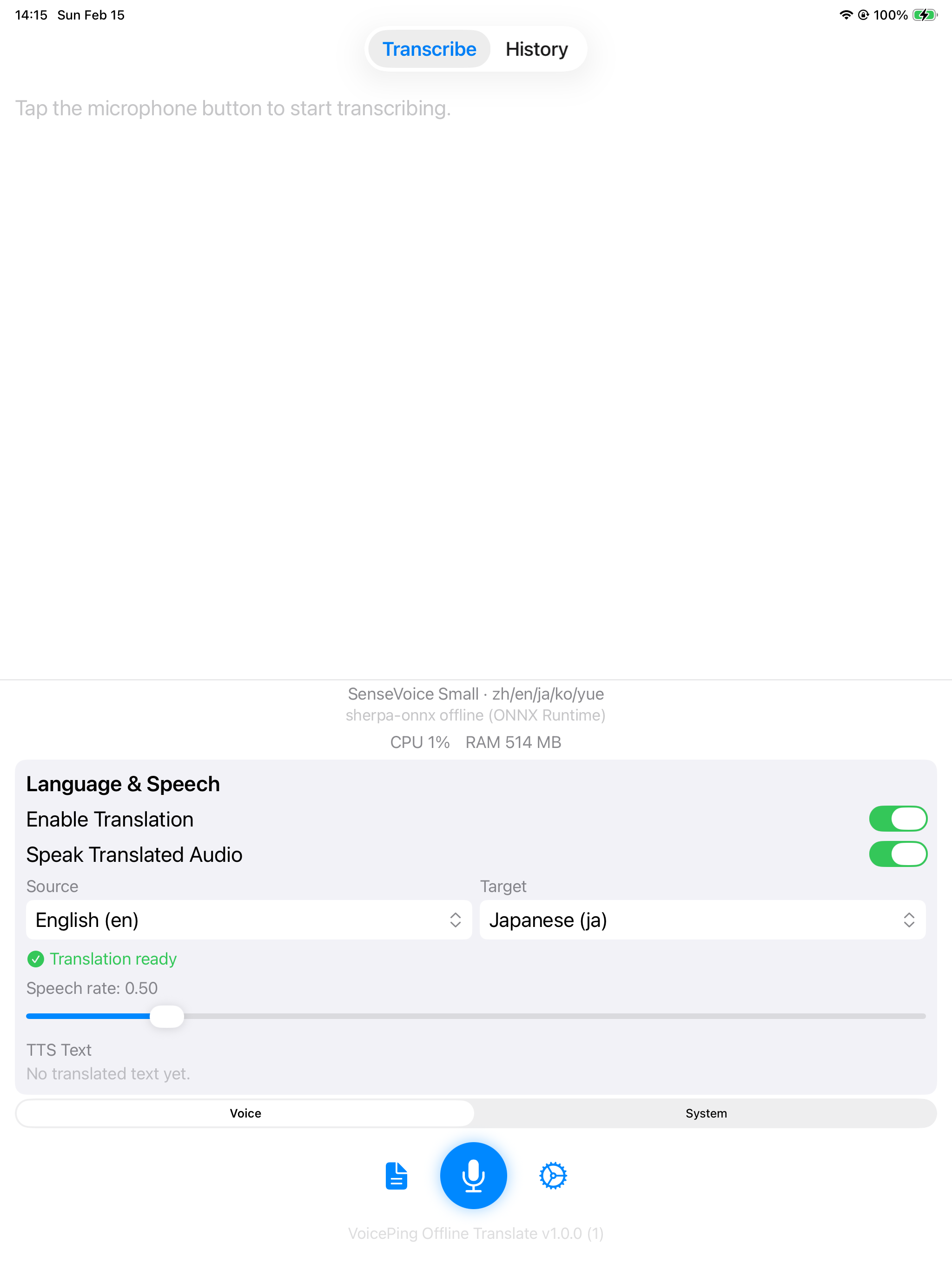 |  | 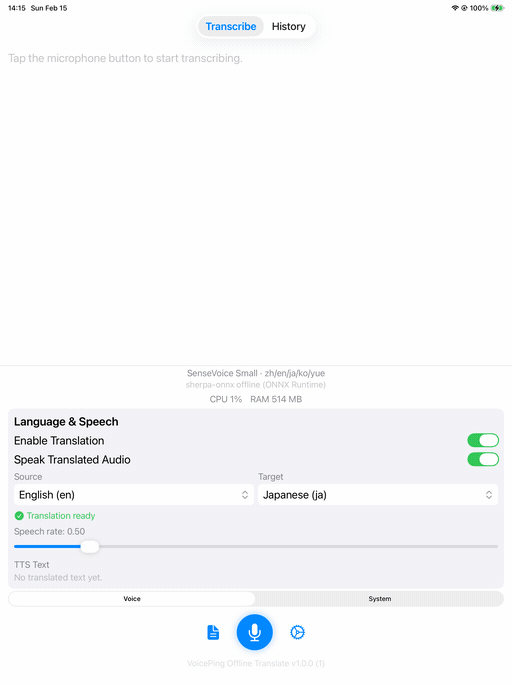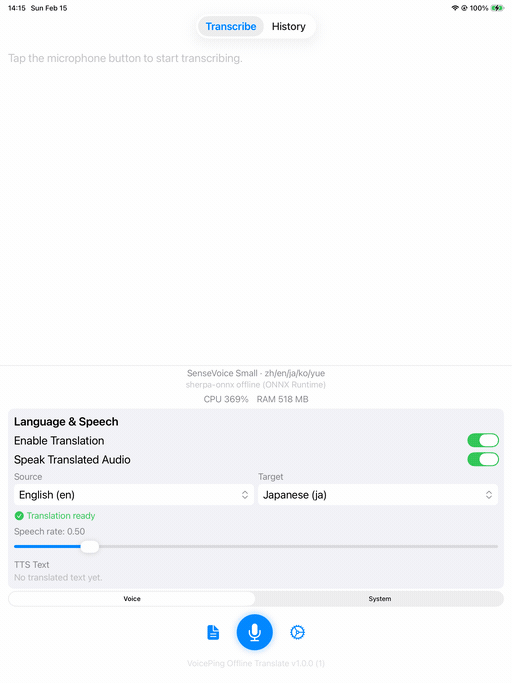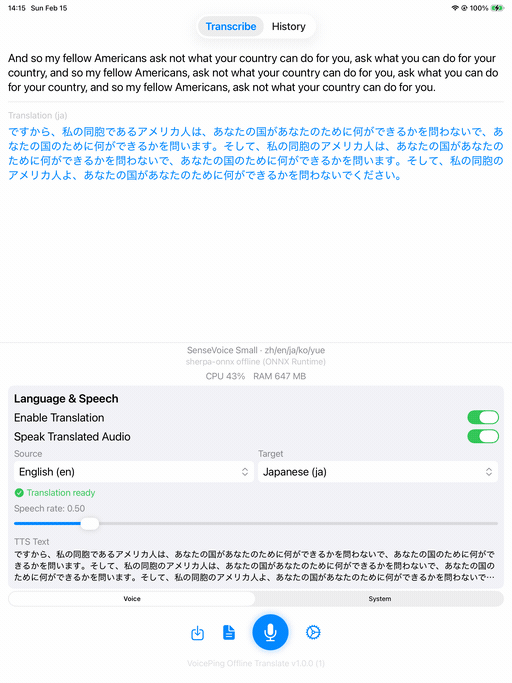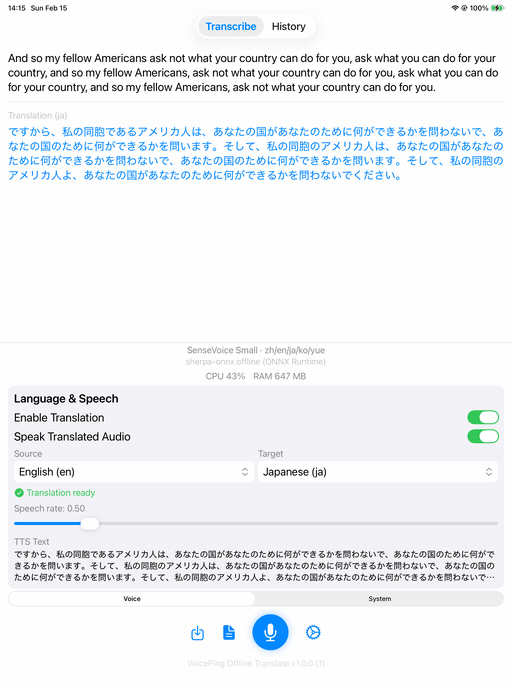 |
SenseVoice Small with Apple Translation (English → Japanese) and TTS.
Android
| Transcription + Translation | Demo |
|---|---|
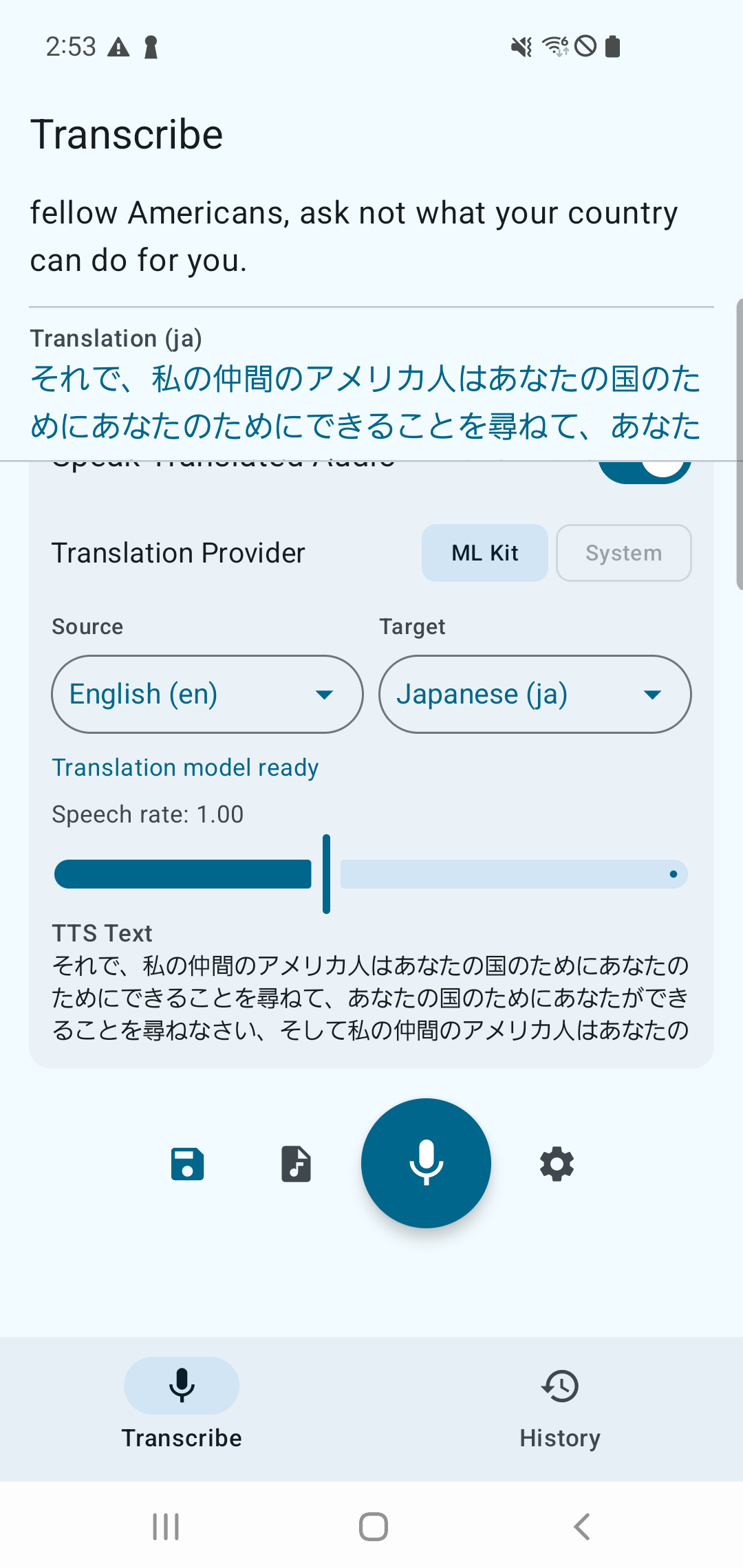 | 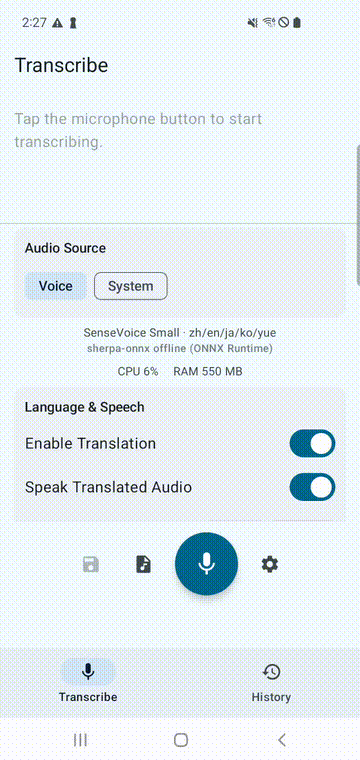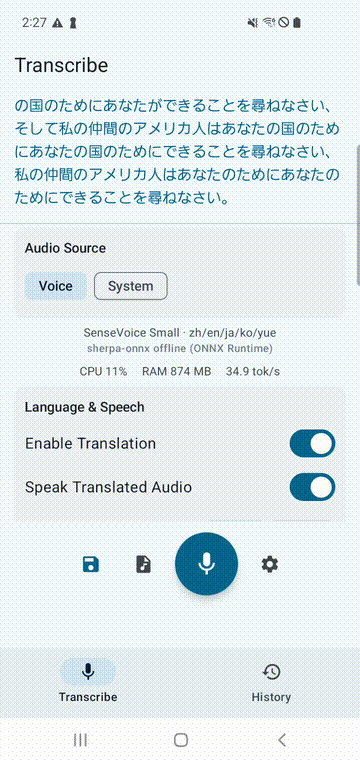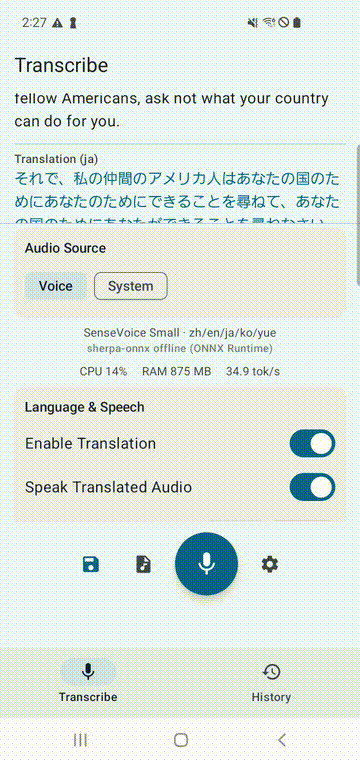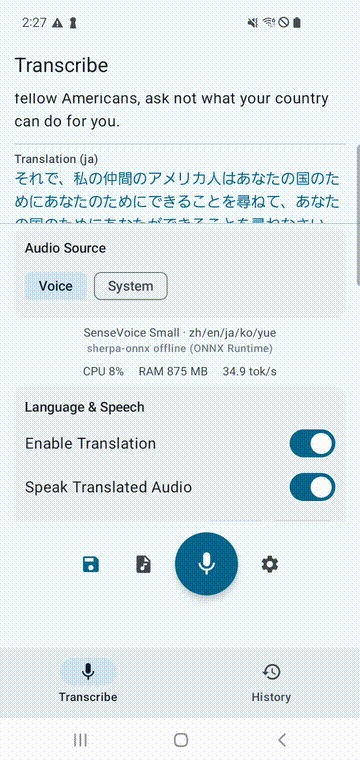 |
SenseVoice Small with ML Kit Translation and TTS.
Pipeline Architecture
The app implements a complete offline speech translation pipeline:
| Stage | Component | Details |
|---|---|---|
| Audio Input | Mic / System Audio | Microphone or system audio capture |
| → ASR | SenseVoice Small | Speech-to-text via sherpa-onnx (offline) |
| → Translation | Apple Translation / Google ML Kit | Neural machine translation (offline) |
| → TTS | System TTS | AVSpeechSynthesizer (iOS) / Android TextToSpeech |
| Audio Output | Speaker | Translated speech playback |
Each stage runs entirely on-device with no network dependency at inference time.
Supported Models
iOS:
| Model | Engine | Languages |
|---|---|---|
| SenseVoice Small | sherpa-onnx offline | zh/en/ja/ko/yue |
| Apple Speech | SFSpeechRecognizer | 50+ languages |
Android:
| Model | Engine | Languages |
|---|---|---|
| SenseVoice Small | sherpa-onnx offline | zh/en/ja/ko/yue |
| Android Speech (Offline) | SpeechRecognizer (on-device, API 31+) | System languages |
| Android Speech (Online) | SpeechRecognizer (standard) | System languages |
Translation Providers
| Platform | Provider | Mode | Coverage |
|---|---|---|---|
| iOS | Apple Translation | Offline (iOS 18+) | 20+ language pairs |
| Android | Google ML Kit | Offline | 59 languages |
| Android | Android System Translation | Offline (API 31+) | System languages |
TTS
| Platform | Engine |
|---|---|
| iOS | AVSpeechSynthesizer |
| Android | Android TextToSpeech |
Audio Capture Scope
This app supports both microphone input and system audio capture from other apps (subject to platform restrictions such as DRM and app-level opt-out). To keep this article focused on pipeline behavior and deployment outcomes, low-level capture implementation details are intentionally omitted here. For iOS capture internals, see the offline transcription project: ios-mac-offline-transcribe.
Data Persistence and Export
Both platforms store transcription history locally and support export:
| Feature | iOS | Android |
|---|---|---|
| Persistence | SwiftData (TranscriptionRecord) | Room (TranscriptionEntity, AppDatabase) |
| Audio files | SessionFileManager | AudioPlaybackManager |
| Export | ZIP export (ZIPExporter) | ZIP export (SessionExporter) |
Limitations
- ASR only benchmarked: Only the ASR stage (SenseVoice Small) was benchmarked for speed. Translation and TTS stages use platform-native engines and were not individually measured — end-to-end pipeline latency is unknown.
- System audio capture restrictions: Some apps opt out of audio capture, so “other apps” capture is not universal.
- Two devices tested: Results are from Galaxy S10 (2019) and iPad Pro 3rd gen (2018). Performance on other devices may vary.
- No accuracy evaluation: ASR transcription accuracy (WER) and translation quality were not formally measured in this release.
Further Research
- End-to-end latency breakdown: Measure ASR, translation, and TTS stages separately and report full pipeline latency percentiles.
- Quality evaluation: Add WER for ASR and translation quality metrics with human validation for common language pairs.
- Broader device matrix: Benchmark mid-range and newer NPU-equipped phones to understand scaling across 2018-2026 hardware.
- Background reliability: Stress-test long sessions, interruptions, and background execution policies on both OS platforms.
- Power and thermals: Quantify battery drain and thermal throttling during continuous translation sessions.
Conclusion
Fully offline speech translation is practical on current mobile hardware. The ASR stage (SenseVoice Small) achieves 23–34 tok/s with RTF < 0.1 on consumer devices from 2019 (Galaxy S10) and 2018 (iPad Pro 3rd gen). Translation and TTS use platform-native engines (Apple Translation / Google ML Kit and system TTS) which were not individually benchmarked — end-to-end pipeline latency depends on utterance length and these downstream stages.
The system audio capture capability extends translation beyond microphone input to other audio sources, enabling translation of video calls, media, and other apps without cloud connectivity.
For edge deployment scenarios where network access is unreliable or where data privacy is paramount, this architecture demonstrates that the full speech translation pipeline can be deployed entirely on-device using consumer hardware. The app is open-source under Apache 2.0 and supports community contributions of additional models and benchmark results.
References
Our Repository:
- ios-android-offline-speech-translation — Cross-platform offline speech translation app (Apache 2.0)
ASR Models:
- SenseVoice Small — Alibaba’s multilingual ASR model (zh/en/ja/ko/yue)
- Parakeet TDT 0.6B v3 — NVIDIA NeMo, 25 European languages
Inference Engine:
- sherpa-onnx — Next-gen Kaldi ONNX Runtime for on-device speech processing
Translation:
- Apple Translation Framework — On-device translation for iOS 18+
- Google ML Kit Translation — Offline translation for Android